はじめに
Microsoft Fabricという企業向けのサービスが存在するようで、利用者向けのチュートリアルコンテンツが以下のようにアップされています. 私の個人環境ではMicrosoft Fabricを利用することができないものの、コンテンツ(以下参考サイト)内の手順に沿って高揚モデルについて学んでいきたいと思います.
個人メモ
高揚モデルとは、いわゆるアップリフトモデリングを指すものだと理解
作業環境はGoogle Colaboratoryです。
当初は私用Macのローカル環境で試みたものの、途中で諦めました。
理由は、何度もエラーが発生し、Bingチャットに問い合わせても、解決につながらなかったからです。
用語の確認
参考サイトでは、2種類の見慣れない用語があったので、最初に確認しておきます.
Microsoft Fabric
参考サイトでは、さも一般常識かのように"Microsoft Fabric"という用語が出現します. 残念ながら、私の理解が及ばないので、Bing氏に聞いてみました.
Bingとのチャット
- Microsoft Fabricとは何ですか?
Microsoft Fabricは、データと分析のエンドツーエンドの統合プラットフォームで、データレイク、データエンジニアリング、データウェアハウス、データサイエンス、リアルタイム分析、ビジネスインテリジェンスなどのサービスを提供します。また、Azure OpenAI Servieを利用してAIを活用することもできます。
- Microsoft Fabricは無料ですか?
Microsoft Fabricは、パブリックプレビューとして開始され、Microsoft Fabric (プレビュー) 試用版にサインアップすると一時的に無料で提供されます。1Microsoft Fabric (プレビュー) 試用版の使用には、Fabric製品エクスペリエンスへのアクセスと、Fabricアイテムを作成およびホストするためのリソースが含まれます。Fabric (プレビュー) の試用期間は60日間ですが、Microsoftの裁量により延長される場合があります。
ということです.
どうやらリンク先のコンテンツは、この統合プラットフォーム上のノートブックで作業することを前提としているようです. 前述のとおり今回はGoogle Colabを利用したので、Microsoft Fabricを利用することはありませんでした。
Lakehouse
"Lakehouse"という用語も私には初見でした. Lakehouseとは何なのでしょうか.
Bingとのチャット
- 関連して、レイクハウスとは何ですか?
レイクハウスは、データレイクとデータウェアハウスの優れた部分を組み合わせた新しい、オープンなデータ管理アーキテクチャです。データレイクは、様々なフォーマットの生データを格納するデータリポジトリで、安価なストレージに直接アクセスすることができます。一方、データウェアハウスは、意思決定サポートやBIアプリケーションにおいて長い歴史があります。レイクハウスは、データレイクの柔軟性、経済性、スケーラビリティとデータウェアハウスのデータ管理やACIDトランザクションの機能を取り入れたオープンで新たなデータ管理アーキテクチャーです。
- ACIDトランザクションとは何ですか?
ACIDトランザクションとは、トランザクションを定義する4つの重要な特性、Atomicity(原子性)、Consistency(一貫性)、Isolation(独立性)、Durability(永続性)の頭文字をとった略語です。トランザクションは、データベース内で実行される一連の作業の塊であり、ACIDトランザクションは、データベースの一貫性を維持するためにトランザクションシステムが持つべき性質です。
ということです.
LakehouseはBingチャットの回答によると一般名詞のようですが、前述の通り今回私はGoogle Colabを利用し、元データはGoogle Drive内のcsvファイルを利用することになるので、関係ないでしょう.
用語の確認ができました. それではここからは、実際のコードに取り組みます.
関連ライブラリのインポート
はじめに、Colabのノートブック上で以下のようにインストールを実施しました.
!pip install mlflow
!pip install pyspark
!pip install synapseml
なお、インストールのためのセルのアウトプットを見る限り、バージョンはPython 3.10、pyspark 3.4.1のようで、pysparkのインストール時に要件となっているpy4jについてはpy4j 0.10.9.7のようです.
ちなみに、参考サイトではこれらのライブラリをインストールする手順は明示されていないので、おそらく最初からインストール済みなのでしょう.
また、Google Colabの利用の前段で一度挫折している私用PCのローカル環境で行うときは、別途apache-sparkをbrew installコマンドでインストールする作業がありました. 恐らくこれは必要な手順だと思うのものの、結論として挫折しているので結局のところ必要不可欠な手順なのかどうか判然としません.
話を戻しまして、続いて以下は関連ライブラリのインポート部分です.
# import relevant libraries
import pyspark.sql.functions as F
from pyspark.sql.window import Window
from pyspark.sql.types import *
from pyspark.sql import SparkSession
from pyspark import SparkConf, SparkContext
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.style as style
import seaborn as sns
%matplotlib inline
import os
import gzip
import mlflow
import py4j
上記は参考サイト内の手順とほぼ同じですが、py4jのインポートは本稿独自のものです. というのも、後続のセル実行時にpy4jエラーなるものが発生したので試しにpy4jをインポートしたところ解消したため、このようにしています.
上記のライブラリインポート内で、pysparkについては、利用経験がなく、Bingチャットに聞いたところ、apache-sparkというソフトウェアをPythonから操作するためのAPIみたいでした. 普通に考えると、どのapache-sparkを操作するのか設定する必要があると思うのですが、Google Colabのデフォルト設定がうまく処理してくれているのでしょう.
以上が関連ライブラリのインポートです.
データの読み込み
次にデータをロードしていきます.
使用するデータ参考サイト内で利用されていデータと同じで、Microsoft社からすると外部サイトのデータになります. 関連して、引用時にはクレジットの表示をした方が良さそうでしたので、データの読み込み作業の説明の前に、元データが掲示されているWebサイトの指示どおりに以下のとおりクレジット表示します.
@inproceedings{Diemert2018,
author = {{Diemert Eustache, Betlei Artem} and Renaudin, Christophe and Massih-Reza, Amini},
title={A Large Scale Benchmark for Uplift Modeling},
publisher = {ACM},
booktitle = {Proceedings of the AdKDD and TargetAd Workshop, KDD, London,United Kingdom, August, 20, 2018},
year = {2018}
}
以下のコードでは、パラメータを指定します. 本当は、冒頭にその他のパラメータも合わせてまとまっているのですが、本稿では都度確認するスタイルにしたいと思います.
DATA_FOLDER = '/content/drive/MyDrive/Colab Notebooks/spark'
DATA_FILE = 'criteo-uplift-v2.1.csv'
つまり、外部サイトからダウンロードしたcsvファイルをGoogle Drive上の任意のフォルダにアップロードしました. 一方で、参考サイトではMicrosoft Fabricと関連のあるディレクトリが指定されているようです.
さて、ここでデータの読み込みにチャレンジします. 以下はデータを読み込むコードです. フォルダのパスの部分の佇まいが、参考サイトの記載とは若干異なります.
raw_df = spark.read.csv(
f"{DATA_FOLDER}/{DATA_FILE}",
header=True,
inferSchema=True
).cache()
上記のコードを実行したところ、残念ながらエラーとなりました. エラーの趣旨としてはsparkがそもそも定義されていないというものでした. 色々と調べていると、pysparkの基本的な使い方として、まず初めにスパークセッションなるものを立ち上げる必要があるようです. 私は以下のようにしてスパークセッションを立ち上げました.
# Sparkの全ての機能へのエントリーポイントはSQLSession クラスです。
# 基本的な SparkSessionを生成するには、単にSparkSession.builderを使います
spark = pyspark.sql.SparkSession.builder.appName("MyApp") \
.config("spark.jars.packages", "com.microsoft.azure:synapseml_2.12:0.11.2") \
.getOrCreate()
import synapse.ml
一方で、参考サイトではスパークセッションを立ち上げている形跡を確認することができませんでした. デフォルトでセッションが立ち上がっているということでしょうか.
なお、スパークセッションの立ち上げ時には色々と設定をすることができるようです. pysparkが保管されているディレクトリを下っていくと設定用のファイルがあるのでそれを直接メンテしたり、上述の.appName()などのように、ふさわしいpysparkのメソッドから設定することも可能なようです. 私の場合この設定がうまくいかずローカル環境では挫折したのですが、以下のようなコードで、設定を確認することができます.
spark.sparkContext.getConf().getAll()
何はともあれ、上記のコードでsparkを定義してやれば、データの読み込みができました. csvファイルのサイズは約3GB。読み込みには2分程度かかりました.
個人メモ
SparkSessionのread_csvメソッドの使い方についてBing氏に聞いてみました.
sparksession のread_csvの代表的な引数について教えてください.
SparkSessionのread_csvメソッドの代表的な引数は以下の通りです。
- path: CSVファイルのパス
- header: ヘッダーがあるかどうか
- sep: 区切り文字
- schema: スキーマ情報
- inferSchema: スキーマを自動推定するかどうか
このメソッドを実行すると何が起こりますか?
read_csvメソッドは、CSVファイルを読み込んで、Spark DataFrameに格納するメソッドです。
メソッドのあとに.cache()を追加するとどうなりますか?
.cache()メソッドは、DataFrameをキャッシュするためのメソッドです。キャッシュされたDataFrameは、次回以降の処理で再利用されるため、処理速度が向上します。
スパークセッションは明示的に閉じる必要はないのですか?
スパークセッションは、明示的に閉じる必要はありません。
集計値の確認
このセクションでは、各種の集計値を確認してきます. コード内に出てくるFはpyspark.sql.functionsをインポート時に改名したものです. 簡潔なネーミングなのでおそらく頻繁に使用するモジュールなのでしょう.
アクセス率・コンバージョン率
raw_df.select(
F.mean("visit").alias("Percentage of users that visit"),
F.mean("conversion").alias("Percentage of users that convert"),
(F.sum("conversion") / F.sum("visit")).alias("Percentage of visitors that convert"),
).show()
+------------------------------+--------------------------------+-----------------------------------+
|Percentage of users that visit|Percentage of users that convert|Percentage of visitors that convert|
+------------------------------+--------------------------------+-----------------------------------+
| 0.046992000911042324| 0.002916680257907384| 0.06206759025709019|
+------------------------------+--------------------------------+-----------------------------------+
SparkDataFrameのselect()メソッドはこんな感じでF(pyspark.sql.functions)と組み合わせて使うようです. 個人的には直感的に理解できました、スッキリしていて良いですね.
アクセス率は4%台、コンバージョンは0.2%台、アクセスを分母にするとコンバージョンは6%台だったということですね.
個人メモ
pyspark.sql.dataframe.DataFrameのselect()メソッドの使い方についてBing氏に聞いてみました.
selectメソッドは、使用する列を選択するために使用されます。この場合、"visit"と"conversion"列の平均を計算し、より説明的な名前にエイリアスを付けています。また、「conversion」列の合計を「visit」列の合計で除算して、訪問者のコンバージョン率を計算しています。結果はshowメソッドで表示されます。
Fはpyspark.sql.functionsのことですが、データフレーム名を引数に指定しなくて良いのはなぜですか?
pyspark.sql.functionsは、PySparkの関数ライブラリであり、データフレームの列を操作するために使用されます。F.mean("visit")のように、関数名を指定して列を操作することができます。データフレーム名を指定しなくてもよいのは、selectメソッドがデータフレームの列を選択するために使用されるためです。つまり、raw_df.select(...)は、raw_dfデータフレームの列を選択し、それらに対して関数を適用します。
pyspark.sql.functions.mean()の代表的な引数を教えてください
pyspark.sql.functions.mean()の代表的な引数は、colです。colは、平均を計算する列を指定するために使用されます。たとえば、F.mean("visit")は、"visit"列の平均を計算します。
介入有無でグルーピングした場合のアクセス率の比較
raw_df.groupby("treatment").agg(
F.mean("visit").alias("Mean of visit"),
F.sum("visit").alias("Sum of visit"),
F.count("visit").alias("Count"),
).show()
+---------+--------------------+------------+--------+
|treatment| Mean of visit|Sum of visit| Count|
+---------+--------------------+------------+--------+
| 1|0.048543360048743316| 576824|11882655|
| 0| 0.03820095691954503| 80105| 2096937|
+---------+--------------------+------------+--------+
これを見ると、そもそも介入群(treatment == 1)がかなり多いようです.
介入群, 非介入群の間では訪問率に差がありますね.
私の浅いpandasの知識をベースにすると、groupbyのあとに、異なる集計計算の列を複数作るような作業が簡単にできるようです.
介入有無でグルーピングした場合のコンバージョン率の比較
raw_df.groupby("treatment").agg(
F.mean("conversion").alias("Mean of conversion"),
F.sum("conversion").alias("Sum of conversion"),
F.count("conversion").alias("Count"),
).show()
+---------+--------------------+-----------------+--------+
|treatment| Mean of conversion|Sum of conversion| Count|
+---------+--------------------+-----------------+--------+
| 1|0.003089461067412...| 36711|11882655|
| 0|0.001937588015281...| 4063| 2096937|
+---------+--------------------+-----------------+--------+
同様に、介入群(treatment == 1)がかなり多いようです.
介入群, 非介入群の間ではコンバージョン率にも差がありますね.
機械学習のための準備
特徴量のベクトル化
最初に以下のようなコードを実行します.
(上段コードの3行目は新たに設定したパラメータです.
DATA_FOLDER = '/content/drive/MyDrive/Colab Notebooks/spark'
DATA_FILE = 'criteo-uplift-v2.1.csv'
FEATURE_COLUMNS = [f"f{i}" for i in range(12)]
fストリングスの直後にあるfは単なる文字列で、元データの列名がf0, f1...となっていることに対応するのですが、やや紛らわしいですね.
以下は、特徴量をベクトル化するためのコードです.
synapsemlでは何らかの理由で特徴量を一つのベクトルに集約するみたいです.
from synapse.ml.featurize import Featurize
from synapse.ml.core.spark import FluentAPI
from synapse.ml.lightgbm import *
from synapse.ml.train import ComputeModelStatistics
transformer = (
Featurize().setOutputCol("features").setInputCols(FEATURE_COLUMNS).fit(raw_df)
)
df = transformer.transform(raw_df)
冒頭では、synapsemlをpipでインストールしませんでしたが、ここでsynapsemlの関連モジュールが問題なくインポートできるのは、スパークセッションの立ち上げ時にspark.jars.packagesなる設定で、synapsemlに関する言及があることから、恐らくどこかにsynapsemlがインストールされているのでしょう.
スパークセッション自体は、spark.jars.packagesの設定をしなくても立ち上がりますが、Google Colabではpipでsynapsemlをインストールし、spark.jars.packagesに何も設定せずにスパークセッションを立ち上げると上記のFeaturize()オブジェクトの生成に失敗しました.
(JavaPackage is not collable というエラーが返されます
さて、synapseml全般がそもそも見慣れませんが、このFeaturize()についてBing氏に聞いてみました.
Bing氏に上述のコードは何を行なっているか尋ねた結果です.
このコードは、PySparkのVectorAssemblerという機能を使って、複数の列を1つのベクトル列にマージしています。Featurize()は、入力列を特徴量に変換するためのTransformerです。setInputCols()は、入力列を設定するためのメソッドで、setOutputCol()は出力列を設定するためのメソッドです。このコードでは、raw_dfというデータフレームに対して、Featurize()で特徴量に変換し、その結果をfeaturesという列名で出力しています。VectorAssemblerでマージされたベクトル列は、各列の値が1つのベクトルにまとめられます。このベクトルは、機械学習アルゴリズムに入力するために使用されます。このコードでは、Featurize()で特徴量に変換したデータフレームraw_dfに対して、複数の列を1つのベクトル列にマージしています。featuresという列名で出力されるベクトルは、inputColsで指定された複数の列から構成されます。各要素は、入力列の値に対応しています。ただし、VectorAssemblerが選択する出力形式は、メモリ使用量が少ない方を選択します。つまり、DenseVectorまたはSparseVectorのどちらかです。
参考までに、spark.jars.pacakagesやsynapsemlについても聞いてみました.
Bingとのチャット
- "spark.jars.packages"とは何の設定をしているのですか?
"spark.jars.packages"は、Sparkアプリケーションで使用する外部パッケージを指定するための設定です。この設定を使用すると、Sparkアプリケーションが実行されるときに、指定されたパッケージが自動的にダウンロードされます。この設定は、Sparkアプリケーションで使用する外部パッケージを指定するために使用されます。Synapse MLのドキュメントによると、synapseml_2.12パッケージは、Synapse MLのPython APIを提供するパッケージです。このパッケージを使用することで、Synapse MLの機能をPythonから呼び出すことができます。
- スパークセッションを起動するときにダウンロードされるのですか?
"spark.jars.packages"設定は、スパークセッションを起動するときに指定されたパッケージが自動的にダウンロードされるようになっています。つまり、Synapse MLのPython APIであるsynapseml_2.12パッケージは、スパークセッションを起動するときに自動的にダウンロードされます。
- Synapse MLとは何ですか?
Synapse MLは、Microsoft Azure Synapse Analyticsの機械学習ライブラリです。Synapse MLは、大規模スケーラブルな機械学習パイプラインの作成を簡略化するオープンソースライブラリです。Synapse MLは、Python APIを提供し、PySparkと統合されています。
Synapse MLには、次のような機能があります。
_データの前処理
_特徴量エンジニアリング
_モデルトレーニング
_モデル評価
_モデルデプロイ
Synapse MLは、Azure Synapse Analyticsで使用できるため、大規模なデータセットに対してスケーラブルな機械学習パイプラインを作成することができます。
トレーニングデータ、テストデータへの分割
このセクションでは、データを分割します.
まずはパラメータに2つの列名を追加しています.
DATA_FOLDER = '/content/drive/MyDrive/Colab Notebooks/spark'
DATA_FILE = 'criteo-uplift-v2.1.csv'
FEATURE_COLUMNS = [f"f{i}" for i in range(12)]
TREATMENT_COLUMN = "treatment"
LABEL_COLUMN = "visit"
続いて、元のraw_dfに先程のtransform()を適用したdfを以下のように分割します. 参考サイトと同じコードです.
train_df, test_df = df.randomSplit([0.8, 0.2], seed=42)
print("Size of train dataset: %d" % train_df.count())
print("Size of test dataset: %d" % test_df.count())
train_df.groupby(TREATMENT_COLUMN).count().show()
Size of train dataset: 11182965
Size of test dataset: 2796627
+---------+-------+
|treatment| count|
+---------+-------+
| 1|9505415|
| 0|1677550|
+---------+-------+
randomSplitというメソッドがあるんだな、といったところでしょうか.
後続作業へのつながりとしては、ここでtrain_dfとtest_dfというデータフレームが作成されていますね.
介入データ、コントロールデータへの分割
ここでは、train_dfをさらに分割して、介入群とコントロール群に分けます. 以下のコードは参考サイトのコードと同じです.
treatment_train_df = train_df.where(f"{TREATMENT_COLUMN} > 0")
control_train_df = train_df.where(f"{TREATMENT_COLUMN} = 0")
where()メソッドがあるんだな、といったところでしょうか.
手法としては、tree-based approachにおけるTwo Tree Algorithmに近いのでしょうか.
Two Tree Algorithmについては以下の投稿でまとめています.
決定木のleaf内の平均を予測値$\hat{\mu}$として使用するという前提のもと、$\hat{\mu}(1, x)$の推定には$W_i=1$(介入があったことを示すダミー変数)のサブサンプルを使用し、$\hat{\mu}(0, x)$の推定には$W_i=0$のサブサンプルを使用するというものでした.
\begin{align}
\hat{\tau_{TT}}(x) &= \hat{\mu}(1, x) - \hat{\mu}(0, x)
\end{align}
参考サイトのコードでこれから行う高揚モデルは恐らくLightGBMとなりますが、考え方としては介入群とコントロール群でそれぞれモデルを学習し、同じ特徴量に対しての予測値の差をとったものを高揚だとするのでしょう. 介入有無は直接的には特徴量として使用せず、プロペンシティスコアを使用した従属変数の変形もないということだと理解しました.
ここで一度データについて見ておきましょう.
treatment_train_df.show(2)
+------------------+------------------+-----------------+-----------------+------------------+-------------------+-------------------+------------------+-----------------+------------------+-----------------+--------------------+---------+----------+-----+--------+--------------------+
| f0| f1| f2| f3| f4| f5| f6| f7| f8| f9| f10| f11|treatment|conversion|visit|exposure| features|
+------------------+------------------+-----------------+-----------------+------------------+-------------------+-------------------+------------------+-----------------+------------------+-----------------+--------------------+---------+----------+-----+--------+--------------------+
|12.616364906986497|10.059654474774547|8.214382844395335|4.679881620097284|10.280525225748212|-1.1751376923445536|0.29444271125560606| 10.65387495920022|3.971857989350875|13.190055934673358|5.300374864042156|-0.16867922100056124| 1| 0| 0| 0|[-0.1686792210005...|
|12.616364906986497|10.059654474774547|8.214382844395335|4.679881620097284|10.280525225748212|-0.9736510105903111|0.29444271125560606|11.267923954447209|3.971857989350875|13.190055934673358|5.300374864042156|-0.16867922100056124| 1| 0| 0| 0|[-0.1686792210005...|
+------------------+------------------+-----------------+-----------------+------------------+-------------------+-------------------+------------------+-----------------+------------------+-----------------+--------------------+---------+----------+-----+--------+--------------------+
only showing top 2 rows
12の特徴量に、介入有無を表すダミー変数、さらにconversion, visit, exposureという従属変数が元データにはあり、featuresという特徴量ベクトルのようなものが追加されていることが分かりますね. 特徴量のベクトル化時にはfit()、transform()メソッドが使用されていましたが、このfeaturesに格納されている見切れたリストのエントリーを確認する限り、平均値の調整など標準化のような作業が行われているようですね.
モデルのトレーニングと評価
最初に、LightGBMClassifierオブジェクトを立ち上げて初期設定を行ったあと、介入群データ, コントロール群データのそれぞれに対して、モデルを作成する流れです. 以下はコードで参考サイトのコードと同じです.
classifier = (
LightGBMClassifier()
.setFeaturesCol("features")
.setNumLeaves(10)
.setNumIterations(100)
.setObjective("binary")
.setLabelCol(LABEL_COLUMN)
)
treatment_model = classifier.fit(treatment_train_df)
control_model = classifier.fit(control_train_df)
次に、モデルの評価のために、テストデータで予測を行います.
具体的にはtest_pred_dfを作成します. コードは参考サイトのものをほぼ同じですが、私の場合display()がうまくいかず、最後のコードをshow()に変更しています.
getPred = F.udf(lambda v: float(v[1]), FloatType())
test_pred_df = (
test_df.mlTransform(treatment_model)
.withColumn("treatment_pred", getPred("probability"))
.drop("rawPrediction", "probability", "prediction")
.mlTransform(control_model)
.withColumn("control_pred", getPred("probability"))
.drop("rawPrediction", "probability", "prediction")
.withColumn("pred_uplift", F.col("treatment_pred") - F.col("control_pred"))
.select(
TREATMENT_COLUMN, LABEL_COLUMN, "treatment_pred", "control_pred", "pred_uplift"
)
.cache()
)
test_pred_df.show(20)
上図のコードを見るとtest_dfに対して、mlTransform()を2回適用していることが分かります. 引数は先ほど学習したモデルのようです.
F.udf()はユーザー定義関数で、mlTransform()の結果データに付される"probability"という列の2要素目を取得しているようです. 恐らくですが、予測値が0となる確率, 1となる確率がそれぞれ順番に格納されているのでしょう.
以下は上述のセルの出力です.
+---------+-----+--------------+------------+------------+
|treatment|visit|treatment_pred|control_pred| pred_uplift|
+---------+-----+--------------+------------+------------+
| 1| 0| 0.0015556811|9.4063015E-4|6.1505096E-4|
| 1| 0| 0.0014097986|9.4063015E-4|4.6916847E-4|
| 1| 0| 0.0015556811|9.4063015E-4|6.1505096E-4|
| 1| 0| 0.0015556811|0.0010787837|4.7689746E-4|
| 1| 0| 0.0014097986|0.0010787837|3.3101498E-4|
| 1| 0| 0.0014097986|0.0010787837|3.3101498E-4|
| 1| 0| 0.0014097986|0.0010787837|3.3101498E-4|
| 1| 0| 0.0015556811|0.0010787837|4.7689746E-4|
| 1| 0| 0.0015556811|0.0011248785|4.3080258E-4|
| 1| 0| 0.0015556811|0.0011248785|4.3080258E-4|
| 1| 0| 0.0015556811|0.0011248785|4.3080258E-4|
| 1| 0| 0.0015556811|0.0011248785|4.3080258E-4|
| 1| 0| 0.0015556811|0.0011248785|4.3080258E-4|
| 1| 0| 0.0015556811|0.0011248785|4.3080258E-4|
| 1| 0| 0.0014097986|0.0010787837|3.3101498E-4|
| 1| 0| 0.0014097986|0.0010787837|3.3101498E-4|
| 1| 0| 0.0014097986|0.0010787837|3.3101498E-4|
| 1| 0| 0.0014097986|0.0010787837|3.3101498E-4|
| 1| 0| 0.0014097986|0.0010787837|3.3101498E-4|
| 1| 0| 0.0014097986|0.0010787837|3.3101498E-4|
+---------+-----+--------------+------------+------------+
only showing top 20 rows
upliftの予測が"pred_uplift"という列になり、上図のコードでは、まさに以下のような佇まいの計算を行いpred_uplift($\hat{\tau_{TT}}(x)$)をデータフレームに追加していることが分かります.
\begin{align}
\hat{\tau_{TT}}(x) &= \hat{\mu}(1, x) - \hat{\mu}(0, x)
\end{align}
続いてPySparkのpercent_rank()関数を使用して、test_pred_dfデータフレームのpred_uplift列のパーセンタイルランクを計算します. 以下はそのコードで、display()関数を除き参考サイトのコードと同じです.
test_ranked_df = test_pred_df.withColumn(
"percent_rank", F.percent_rank().over(Window.orderBy(F.desc("pred_uplift")))
)
test_ranked_df.show(5)
私はSQLにOVER句という概念が存在することを知らなかったのですが、文法がSQLと似ていますね. 以下は上記セルの出力です。
+---------+-----+--------------+------------+-----------+--------------------+
|treatment|visit|treatment_pred|control_pred|pred_uplift| percent_rank|
+---------+-----+--------------+------------+-----------+--------------------+
| 1| 0| 0.6986088| 0.3155115| 0.38309732| 0.0|
| 1| 1| 0.6346671| 0.25711975| 0.37754735|3.575737334917147E-7|
| 1| 0| 0.6840624| 0.30765513| 0.3764073|7.151474669834294E-7|
| 1| 1| 0.61154467| 0.23895992| 0.37258476|1.072721200475144E-6|
| 0| 0| 0.613813| 0.2412428| 0.3725702|1.430294933966858...|
+---------+-----+--------------+------------+-----------+--------------------+
only showing top 5 rows
最上段のpercent_rankが0.0となっているのが気になりますが次に進みましょう.
以下のコードは、display()を除き参考サイトと同じものです. 関数を組み合わせてpred_uplift(のパーセントランク)降順で累積計算をした列"control_cumsum", "treatment_cumsum"をそれぞれ作成しているようです. 分子がバイナリ変数"visit"の累積、分母が対象の群のカウントですので横軸にpred_upliftを降順でとり、縦軸にこれらのcumsumをとると単調増加になるような気がします.
C = test_ranked_df.where(f"{TREATMENT_COLUMN} == 0").count()
T = test_ranked_df.where(f"{TREATMENT_COLUMN} != 0").count()
test_ranked_df = (
test_ranked_df.withColumn(
"control_label",
F.when(F.col(TREATMENT_COLUMN) == 0, F.col(LABEL_COLUMN)).otherwise(0),
)
.withColumn(
"treatment_label",
F.when(F.col(TREATMENT_COLUMN) != 0, F.col(LABEL_COLUMN)).otherwise(0),
)
.withColumn(
"control_cumsum",
F.sum("control_label").over(Window.orderBy("percent_rank")) / C,
)
.withColumn(
"treatment_cumsum",
F.sum("treatment_label").over(Window.orderBy("percent_rank")) / T,
)
)
さらに、次のように"group_uplift"という列も追加します.
test_ranked_df = test_ranked_df.withColumn(
"group_uplift", F.col("treatment_cumsum") - F.col("control_cumsum")
).cache()
最後にAUUCを描画します. matplotlibでエラーが出た箇所を一部削除したこと除き以下のコードは参考サイトと同じです. pysparkのデータフレームはmatplotlibで描画する前に、.toPandas()でpandasデータフレームに変換する必要があるようです.
def uplift_plot(uplift_df):
"""
Plot the uplift curve
"""
gain_x = uplift_df.percent_rank
gain_y = uplift_df.group_uplift
# plot the data
plt.figure(figsize=(10, 6))
mpl.rcParams["font.size"] = 8
ax = plt.plot(gain_x, gain_y, color="#2077B4", label="Normalized Uplift Model")
plt.plot(
[0, gain_x.max()],
[0, gain_y.max()],
"--",
color="tab:orange",
label="Random Treatment",
)
plt.legend()
plt.xlabel("Porportion Targeted")
plt.ylabel("Uplift")
plt.grid(which="major")
return ax
test_ranked_pd_df = test_ranked_df.select(
["pred_uplift", "percent_rank", "group_uplift"]
).toPandas()
uplift_plot(test_ranked_pd_df)
セルの出力結果を見る前に、以下はクエリの再掲です.
+---------+--------------------+------------+--------+
|treatment| Mean of visit|Sum of visit| Count|
+---------+--------------------+------------+--------+
| 1|0.048543360048743316| 576824|11882655|
| 0| 0.03820095691954503| 80105| 2096937|
+---------+--------------------+------------+--------+
上図を見ると、介入群、コントロール群の間の"visit"のアップリフトはおよそ0.01で、先ほどの"control_cumsum"は、"pred_uplift"降順を横軸にとると、およそ0.038に向かって増加していくようなプロットとなることが予想されます. 一方で同じ横軸で"group_uplift"をプロットするとどうなるのでしょうか.
さて、以下は上記セルの出力結果です.
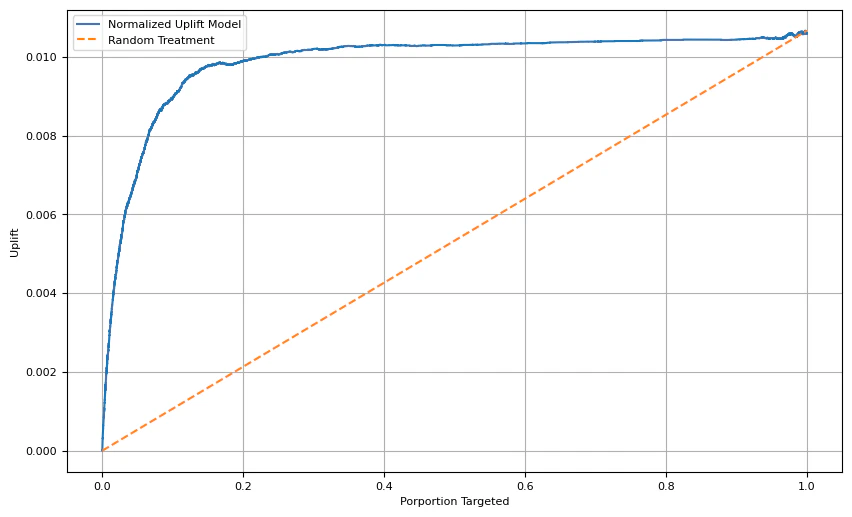
上図から、pred_upliftの上位20%の層よりも先は介入効果が薄いことが分かります.
効果検証の文脈でいうと、上図のx軸名でいうところの"Proportion Targeted"が0.2より大きいような特徴量xでは、当該介入効果の再現性が薄いので注意せよということでしょうか.
以上でコードは終わりです.
おわりに
Pysparkデータフレームと、synapsemlのLightGBMを利用した所謂Two Model Algorithmの類似手法を適用して、介入効果の高いレコードを特定するためのアップリフトモデリングの方法をGoogleColabで試すとができました.
最後に、この流れがRCT(ランダム化試験: Randomized Controlled Trial)データを想定しているのか気になるので参考サイトの引用を確認したいと思います. 私は、Two Model Algorithmによるアプローチが観察データに使えるのかを大前提として理解できていないのですが、今回の元データは以下のとおりRCTを想定しているようでした. "治療"とは介入(treatment)の誤訳かと思います.
データセットの説明: Criteo AI ラボによってこのデータセットが作成されました。 データセットは 13M 行で構成され、それぞれが 12 個の特徴、治療インジケーター、2 つのバイナリ ラベル (訪問と変換) を持つユーザーを表します。
- f0、f1、f2、f3、f4、f5、f6、f7、f8、f9、f10、f11: 特徴値 (dense、float)
- 治療: 顧客がランダムに広告によって標的にされたかどうかを示す治療グループ (1 = 処理、0 = コントロール)
- conversion: このユーザーに対して変換が発生したかどうか (バイナリ、ラベル)
- visit: このユーザーに対して訪問が発生したかどうか (バイナリ、ラベル)
ところでRCTの場合、介入群とコントロール群の属性が介入有無を除き、母集団?(介入群とコントロール群をあわせたもの)と同じになることが期待できますが、モデルを2つ作ると、同じuplift_predパーセントランクで区切った時に、両群の属性は平均的に同じなのか異なるのかイメージが湧きませんでした. 観察データの場合はあまり期待できそうにないので、AUUCを作ったあとの考察が難航しそうな予感がしますね. 実際に手を動かしてみるとこんな疑問が頭に浮かびました.
まとめ
- RCTデータにLightGBMを利用したアップリフトモデリングの所謂Two Model Algorithm系統の手法のコード例がMicrosoft Fabricのspark機械学習チュートリアルに紹介されている
- 上記はGoogle Colabで再現可能