はじめに
本記事は以下の投稿で手に入れた関数を使用して傾向スコアマッチングを1変数で試みるものです.
(そもそもちゃんと関数が動作するのか、というテーマの占める割合が大きいです...
pythonコードの修正
前回の投稿では、Bingチャットに提案してもらった傾向スコアマッチング用の関数を眺めるところで終わってしまいました.
この関数と、所定の元データを使用して傾向スコアマッチングを実施したところ、エラーとなりました.
エラーの原因はどうやら以下のコードにあるようです.
# データの読み込み
data = biased_data
こちらを次のように修正するとうまくいきました.
# データの読み込み
data = biased_data.reset_index()
件の傾向スコアマッチング用の関数はpandasのDataFrameのインデックスが順番に整列していることを前提とした関数となっているようです.
biased_dataは元データのDataFrameから、レコードを削除する形で作成したのですが、これがいけなかったようです.
念の為、再度修正箇所の行を含めたコードを以下に示します.
# 必要なライブラリのインポート
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
from scipy.stats import norm
# データの読み込み
data = biased_data.reset_index()
# 処置変数と共変量を指定
treatment = "treatment"
covariates = ["history"]
# 傾向スコアをロジスティック回帰で推定
model = LogisticRegression()
model.fit(data[covariates], data[treatment])
propensity_scores = model.predict_proba(data[covariates])[:, 1]
# 傾向スコアマッチングを行う関数の定義
def propensity_score_matching(treated, control, pscores, caliper):
matched = []
unmatched = []
for i in range(len(treated)):
t_score = pscores[treated[i]]
min_dist = np.inf
min_index = -1
for j in range(len(control)):
c_score = pscores[control[j]]
dist = abs(t_score - c_score)
if dist < min_dist:
min_dist = dist
min_index = j
if min_dist <= caliper:
matched.append((treated[i], control[min_index]))
control.remove(control[min_index])
else:
unmatched.append(treated[i])
return matched, unmatched
# 処置群と対照群のインデックスを取得
treated_index = data[data[treatment] == 1].index.tolist()
control_index = data[data[treatment] == 0].index.tolist()
# キャリパーを設定(傾向スコアの標準偏差の0.2倍)
caliper = 0.2 * np.std(propensity_scores)
# 傾向スコアマッチングを実行
matched_pairs, unmatched_pairs = propensity_score_matching(treated_index, control_index, propensity_scores, caliper)
# マッチング結果を表示
print("Number of matched pairs:", len(matched_pairs))
print("Number of unmatched pairs:", len(unmatched_pairs))
"""
Number of matched pairs: 13993
Number of unmatched pairs: 3210
"""
実行結果は上図の終盤にありますとおり、マッチングされたペアは13993組になった模様です.
さらに、何度も繰り返し使用しそうなので、傾向スコアを得るところも関数にしました. また、今回は関係なかったものの、カテゴリカルデータを入れるとうまくいかないようだったので、ロジスティック回帰のところも若干手直ししたものが以下です.
# 必要なライブラリのインポート
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
from scipy.stats import norm
# 傾向スコアをロジスティック回帰で推定する関数
def get_propensity_scores(X, y):
X = pd.get_dummies(X, drop_first = True)
model = LogisticRegression()
model.fit(X, y)
propensity_scores = model.predict_proba(X)[:, 1]
return propensity_scores
# 傾向スコアマッチングを行う関数の定義
def propensity_score_matching(treated, control, pscores, caliper):
matched = []
unmatched = []
for i in range(len(treated)):
t_score = pscores[treated[i]]
min_dist = np.inf
min_index = -1
for j in range(len(control)):
c_score = pscores[control[j]]
dist = abs(t_score - c_score)
if dist < min_dist:
min_dist = dist
min_index = j
if min_dist <= caliper:
matched.append((treated[i], control[min_index]))
control.remove(control[min_index])
else:
unmatched.append(treated[i])
return matched, unmatched
RCT下での分析結果
はじめに発射台を確認するために、RCT(ランダム化実験)が起こったときの介入による効果を確認するため、線形回帰係数を取得したいと思います.
最初に、著書で説明のあったRのコードです.
# (2) ライブラリの読み出し
library("tidyverse")
# (3) データの読み込み
email_data <- read_csv("http://www.minethatdata.com/Kevin_Hillstrom_MineThatData_E-MailAnalytics_DataMiningChallenge_2008.03.20.csv")
# (4) データの準備
## 女性向けメールが配信されたデータを削除したデータを生成
male_df <- email_data %>%
# 女性向けメールが配信されたデータを削除
filter(segment != "Womens E-Mail") %>%
# 介入を表すtreatment変数を追加
mutate(treatment = if_else(segment == "Mens E-Mail", 1, 0))
## a simple regression with RCT data
rct_reg <- lm(data = male_df,
formula = spend ~ treatment)
rct_reg_coef <- summary(rct_reg) %>% tidy()
rct_reg_coef
# A tibble: 2 × 5
# term estimate std.error statistic p.value
# <chr> <dbl> <dbl> <dbl> <dbl>
# (Intercept) 0.6527894 0.1027070 6.355841 2.093808e-10
# treatment 0.7698272 0.1452479 5.300090 1.163201e-07
介入による平均的な効果("treatment"の係数)の推定値は約0.76となりました.
次にpythonのコードでも試してみたいと思います.
(male_dfを生成するところは割愛
import statsmodels.api as sm
X = male_df['treatment']
y = male_df['spend']
X_const = sm.add_constant(X)
model = sm.OLS(y, X_const)
results = model.fit()
results.params
"""
const 0.652789
treatment 0.769827
dtype: float64
"""
"treatment"の回帰係数の推定値は同じく約0.76になっているようです.
以上から、ランダム化試験による介入効果を把握することができました.
Rによる傾向スコアマッチング
著書では、傾向スコアマッチングのためのRの関数としてMatchItパッケージが紹介されています. Bingに教えてもらった関数を試す前にこちらの方法を試みたいと思います.
## パッケージのインストール
install.packages("MatchIt")
## ライブラリの読み込み
library("MatchIt")
ここからは傾向スコアマッチングのコードです.
# (7) 傾向スコアマッチング
## 傾向スコアを利用したマッチング
m_near <- matchit(formula = treatment ~ history,
data = biased_data,
method = "nearest",
repalce = TRUE)
## マッチング後のデータを作成
matched_data <- match.data(m_near)
## マッチング後のデータで効果の推定
PSM_result <- matched_data %>%
lm(spend ~ treatment, data = .) %>%
tidy()
# Warning message:
# “Fewer control units than treated units; not all treated units will get a match.”
Rの方が簡潔なコードになっているように見えます.
Google Colaboratory上では10秒未満で完了しました.
それでは結果を確認したいと思います.
PSM_result
# A tibble: 2 × 5
# term estimate std.error statistic p.value
# <chr> <dbl> <dbl> <dbl> <dbl>
# (Intercept) 0.5483062 0.1254869 4.369430 1.249988e-05
# treatment 1.0417538 0.1774653 5.870184 4.399911e-09
treatmentの係数の推定値(≒1.04)がRCT充足下での推定値(≒0.76)を上回りました.
次に、バイアスのかかったデータを単に線形回帰した結果も表示させてみます.
## a simple regression with biased data
nonrct_reg <- lm(data = biased_data,
formula = spend ~ treatment)
nonrct_reg_coef <- summary(nonrct_reg) %>% tidy()
nonrct_reg_coef
# A tibble: 2 × 5
# term estimate std.error statistic p.value
# <chr> <dbl> <dbl> <dbl> <dbl>
# (Intercept) 0.5483062 0.126891 4.321081 1.557365e-05
# treatment 0.9794465 0.172717 5.670817 1.433467e-08
treatmentの係数の推定値≒0.97となりました.
ここで、著書の文言を引用してみたいと思います.
これは介入を受けたサンプルにおける介入効果の期待値で、ATT(AverageTreatmenteffectonTreated)と呼ばれます。ATTは介入を受けたサンプルにおける効果なので、ATTの推定を行った値は、平均的な効果を推定した値と結果が異なる可能性があります。
安井 翔太. 効果検証入門〜正しい比較のための因果推論/計量経済学の基礎 (Japanese Edition) (p.153). Kindle 版.
"これ"というのは、傾向スコアマッチングの手法で推定された介入効果の推定値ということになります.
$$
\hat{ATT} \fallingdotseq 1.04
$$
ということですね.
そもそもRCT下では0.76であったところ、バイアスのかかったデータを使用したことで介入効果が本来よりも上振れしている.
そういった設例の趣旨でした.
実際、バイアスのかかったデータで線形回帰を行うと、介入効果の推定値が約0.97でしたので、確かに上振れしたと言えます.
そして$\hat{ATT} \fallingdotseq 1.04$は更に上振れています.
傾向スコアマッチングはセレクションバイアスを補正するための手法だが、バイアスのかかった線形回帰結果よりも上振れたということになります.
そして、そのことを説明するための概念として、ATT(Average Treatment effect on Treated)がある. そういった理解を持ちました.
ATTの考え方によると、介入のあったサンプルの方が、介入のなかったサンプルよりも平均としての介入効果が大きいということになります. 確かにサンプルを(介入, 非介入に)2分割したとき、それぞれのサンプルの(spendの)平均がもとの平均と同じになることは保証されません.
ただ、初見ですと単にセレクションバイアスが増加したように感じますね.
Bingに教えてもらった関数で傾向スコアマッチングを行う
先ほど、バイアスのかかったデータをRを用いて線形回帰しました.
すると、treatmentの回帰係数の推定値は約0.97でした.
pythonでも同じようになるか確認したいと思います.
ここで、Rとpythonでは、バイアスのかかったデータを元データから加工するときに使用したランダムシードが異なるような気がしたので、Rで作成したbiased_dataを使用しました.
(先ほどpythonのコード修正でpandasのDataFrameに対してreset_index()をかけましたが、もはや意味が無いのかもしれません.
import statsmodels.api as sm
biased_data_from_R = pd.read_csv('biased_data.csv')
X = biased_data_from_R['treatment']
y = biased_data_from_R['spend']
X_const = sm.add_constant(X)
model = sm.OLS(y, X_const)
results = model.fit()
results.params
# const 0.548306
# treatment 0.979446
# dtype: float64
treatmentの回帰係数の推定値は、想定通りの約0.97でした.
それでは、Bingに教えてもらった関数を使用して傾向スコアマッチンをしてみたいと思います.
# データの読み込み
data = biased_data_from_R
# 処置変数と共変量を指定
treatment = "treatment"
covariates = ['history']
# ロジスティック関数の引数
X = data[covariates]
y = data['treatment']
# 傾向スコアを取得
propensity_scores = get_propensity_scores(X, y)
# 処置群と対照群のインデックスを取得
treated_index = data[data[treatment] == 1].index.tolist()
control_index = data[data[treatment] == 0].index.tolist()
# キャリパーを設定(傾向スコアの標準偏差の0.2倍)
caliper = 0.2 * np.std(propensity_scores)
# 傾向スコアマッチングを実行
matched_pairs, unmatched_pairs = propensity_score_matching(treated_index, control_index, propensity_scores, caliper)
# マッチング結果を表示
print("Number of matched pairs:", len(matched_pairs))
print("Number of unmatched pairs:", len(unmatched_pairs))
# Number of matched pairs: 13986
# Number of unmatched pairs: 3212
エラーなく実行されました.
Google Colaboratory上では37秒で完了しました.
Bingチャットに尋ねる際は、軽快に動作することを要件としてお願いした方が良いですね.
それでは、結果を見てみたいと思います.
list_df = []
for i in range(2):
list_matched_indices = np.array(matched_pairs)[:, i].ravel().tolist()
data1 = data.loc[list_matched_indices]
list_df.append(data1)
df1 = pd.concat([list_df[0], list_df[1]], axis = 0)
import statsmodels.api as sm
X = df1['treatment']
y = df1['spend']
X_const = sm.add_constant(X)
model = sm.OLS(y, X_const)
results = model.fit()
results.params
# const 0.568413
# treatment 0.717282
# dtype: float64
これは笑ってしまいました.
結果は、先ほどのRのMatchItパッケージを活用した結果と大きく異なるものでした.
それだけではありません、treatmentの係数の推定値(≒0.71)がRCT充足下での推定値(≒0.76)を下回りました.
効果検証の入門書として名高い著書内で触れられているRのパッケージと、私が他力本願で作成したpythonの関数の優劣は比べるまでもないことです.
下図は今回得られたデータのhistoryをそれぞれヒストグラムにしたものとそのコードです.
この図をどう解釈すれば良いのか見当がつきませんが、少なくとも足元は素性のよくわからない自作関数ではなくMatchItを使った方が良さそうです. また、ロジスティック回帰でうまく分類できないような変数を使用した傾向スコアマッチングは要注意なのかもしれません.
頭がエネルギー切れになってきたので本日はここまでとしたいと思います.
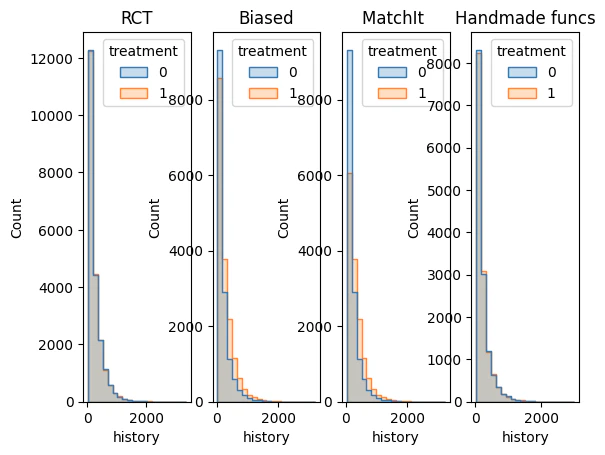
import seaborn as sns
import matplotlib.pyplot as plt
list_df = []
for i in range(2):
list_matched_indices = np.array(matched_pairs)[:, i].ravel().tolist()
data1 = data.loc[list_matched_indices]
list_df.append(data1)
df1 = pd.concat([list_df[0], list_df[1]], axis = 0)
rct_data = male_df
biased_data = biased_data_from_R
matched_data_from_R = pd.read_csv('matched_data.csv')
matched_data_from_python = df1
fig, axes = plt.subplots(nrows = 1, ncols = 4)
list_data = [rct_data,
biased_data,
matched_data_from_R,
matched_data_from_python]
for i, df in enumerate(list_data):
sns.histplot(data=df, x = 'history',
hue = 'treatment',
element = 'step',
bins = 20,
ax = axes[i])
list_title = ['RCT',
'Biased',
'MatchIt ',
'Handmade funcs']
for i, title in enumerate(list_title):
axes[i].set_title(title)