どうもオリィ研究所(http://orylab.com)の畑中です。
近ごろ強化学習界隈の盛り上がりが素晴らしく、OpenAI UniverseやDeepMind Labのようなプラットフォームがリリースされるなど、開発は今後さらに活発化していくと思われます。ですが従来のDQN等の強化学習手法だとGPUや大規模分散環境が前提になっていたりとハード面がネックになって気軽に試すというわけにもいかなかったりすることが多いかと思います。
ということで何かいいものはないかと探していたところ、DeepMindが開発したA3Cという手法が良さげだったので、手元のMacBookで気軽に強化学習してみます。
A3Cとは
Asynchronous Advantage Actor-Criticの略記です。
DeepMindが2016年に発表した手法で、従来の手法のようにGPUや大規模分散環境等の特殊なハードウェア環境には依存せず、CPUのマルチスレッドを利用して学習を行います。パラメータを最適化する方法として複数のエージェントを利用して勾配更新を非同期的に行う点に特徴があります。GPUを使う従来の手法の半分程度の時間で最高水準の結果を出せるとのことです。
論文 (疑似コード付き)
論文内で従来の手法との性能比較がされていたので見てみます。ちなみにDQNの場合はNVIDIA K40 GPUを利用した結果でA3Cの場合は16コアのCPUを利用したものです。
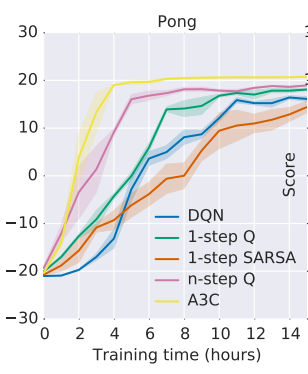
こちらがAtariのPong(ページ下部に動画あり)の結果。y軸がゲームのスコアで、DQNと比較すると何倍も早く最高値に到達していることがわかります(21点先取で勝利)。
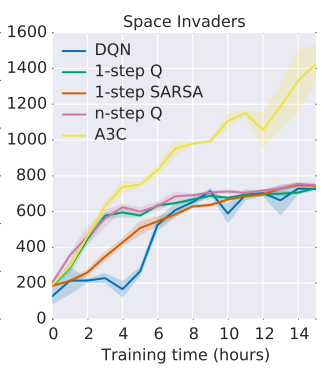
こちらがSpace Invadersのもの。先ほどのPongの場合だとスコアに上限があったのですが、Space Invadersには(おそらく)無いため、スコアの開きが顕著になっています。
とまあ、ざっと見てみるにとても良さげなので早速動かしてみます。
環境
- PC: MacBook Air(Early 2015)
- プロセッサ: 2.2GHz Intel Core i7
- メモリ: 8GB 1600 MHz DDR3
- GPU: Intel HD Graphics 6000 1536MB
準備
miyosudaさんの実装が素晴らしかったので訓練用、テスト用コードをお借りして環境を作っていきます。
miyosuda / async_deep_reinforce
ちなみにゲームのプレー動画をファイル保存したい場合は保存機能追加版のこちらをお使いください(要ffmpeg)。
tatsuyah / async_deep_reinforce
Anaconda(もしくはminiconda)のインストールがされていない場合、下記を参考にインストールし、仮想環境を構築します。
HomebrewのインストールからpyenvでPythonのAnaconda環境構築までメモ
$ git clone git@github.com:miyosuda/async_deep_reinforce.git
$ cd path/to/async_deep_reinforce
$ git clone https://github.com/miyosuda/Arcade-Learning-Environment.git
$ cd Arcade-Learning-Environment
$ cmake -DUSE_SDL=ON -DUSE_RLGLUE=OFF -DBUILD_EXAMPLES=OFF .
$ make -j 4
$ pip install .
以下のライブラリがインストールされていない場合はpipもしくはbrewでインストールしておきます。
- Tensorflow
- cv2
- matplotlib
- sdl
以上で環境構築は終了です。
試す
学習
async_deep_reinforce内で使われているALEはAtariのエミュレータがベースになっており、constants.py内で指定するROMファイルを切り替えることで学習対象のゲームの切り替えが可能です(初期値はpong.bin)。
ROM = "pong.bin"
他に試してみたいタイトルがある場合、ROMファイルは以下のサイトから取ってくるのが良さげです(Space Invadersのものはこちらのレポジトリのものを使った)。
a3c.pyを実行すると学習が始まります。
$ python a3c.py
テスト
学習結果を表示します。
$ python a3c_display.py
結果を見る(動画)
Pong
学習初期(≒720000step。≒1時間)
Atari Pong played by reinforcement learning agent using DeepMind's A3C algorithm. At 720000 step. #RL #Atari #MachineLearning #DeepMind pic.twitter.com/PMsP88NZlZ
— tsy (@thht11) 2017年2月10日
学習後期(≒16Mstep。≒24時間)
Atari Pong played by reinforcement learning agent using DeepMind's A3C algorithm. At 16M step. #RL #Atari #MachineLearning #DeepMind pic.twitter.com/awJg63T4HK
— Tatsuya (@thht11) 2017年2月10日
Space Invaders
学習初期(≒720000step。≒1時間)
Space Invaders played by reinforcement learning agent using DeepMind's A3C algorithm. At 720000 step. #RL #MachineLearning #DeepMind pic.twitter.com/8wMUjOqlqP
— tsy (@thht11) 2017年2月10日
学習後期(≒16Mstep。≒24時間)
Space Invaders played by reinforcement learning agent using DeepMind's A3C algorithm. At 16M step. #RL #MachineLearning #DeepMind pic.twitter.com/oAthx7MAVl
— tsy (@thht11) 2017年2月10日
結果を見る(Tensorboard)
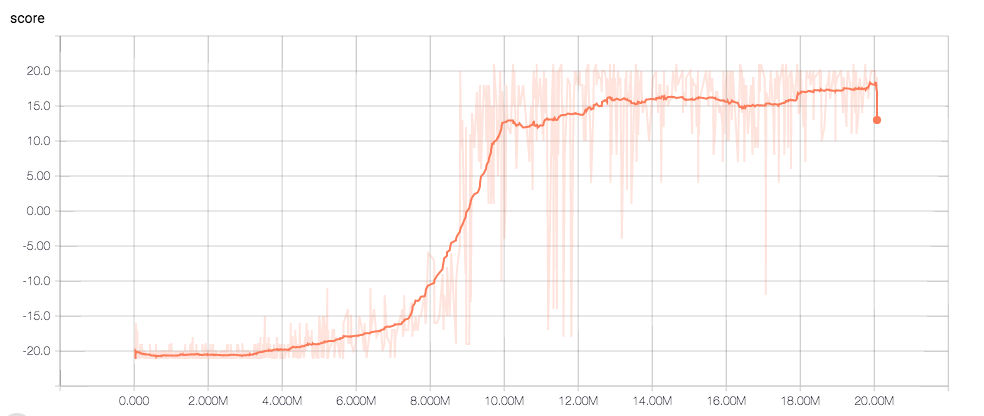
Pong
x軸が総ステップ数、y軸がスコアです。8M stepを超えたあたりから急激にスコアが伸びているのが確認できます。
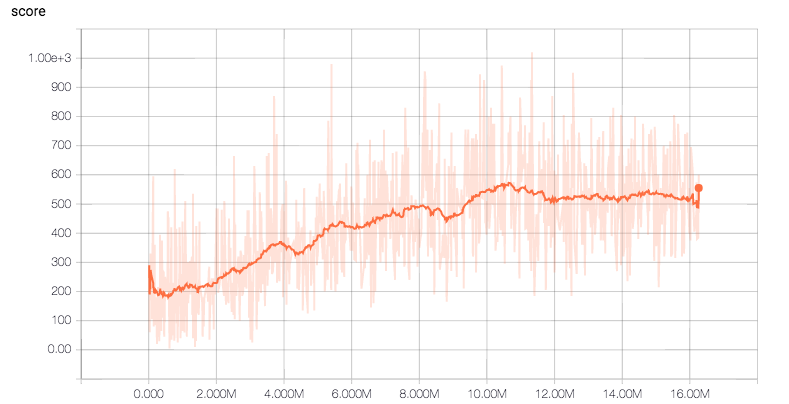
Space Invaders
論文内のグラフに比べるとスコアの伸びが少なくもう少しパラメータのチューニングが必要なようですが、学習はなされています。
おわりに
まあ学習に1日かかっているのを気軽と見るかはアレですが(爆)、手元のCPUのみの環境で強化学習アルゴリズムが試せて、結果を視覚的に理解しやすい形で確認できるというのは機械学習の裾野を広げるという意味では良いことかと思います。
今後も新しい手法が次々出てくると思われますので、この辺はチェックしておいた方が良さそうです。
DeepMind News&Blog
OpenAI Blog