初めまして、構造系のバイオインフォ初心者の者です。
構造系のバイオインフォの記事はあまり見かけないので自分の勉強も兼ねて色々書いてみようと思います。
初心者なので変なところとか、こうしたほうがいいとか、教えていただけると幸いでございます。
閑話休題、とりあえず今回はPDBのAPI(SearchAPI)の使い方について
そもそもAPIとはなんぞやって人はこちらの動画が参考になります
それでは本編↓↓
基本的なSearch APIの使い方(Python)
今回は簡単な説明なので、詳細はドキュメントを確認してください!
Search APIのフォーマットURL:
f'https://search.rcsb.org/rcsbsearch/v2/query?json={search-request}'
search-requestは、検索パラメータを含むJSON(Python辞書)。
Python辞書を作成し、jsonライブラリを使ってjson(検索APIが要求するデータ型)に変換して代入すればOK
例:
import json
import requests
# queryの作成
my_query = {
"query": {
"type": "terminal",
"service": "full_text",
"parameters": {
"value": '"oxygen storage"'
}
},
"return_type": "entry"
}
# 辞書形式からjson形式に変更
my_query = json.dumps(my_query)
このクエリをrequest.getに入れる
data = requests.get(f"https://search.rcsb.org/rcsbsearch/v2/query?json={my_query}")
results = data.json()
results
{'query_id': '06b4b547-40cf-4b89-9536-428bbb2a0805',
'result_type': 'entry',
'total_count': 628,
'result_set': [{'identifier': '1D8U', 'score': 1.0},
{'identifier': '1UVY', 'score': 1.0},
{'identifier': '2EF2', 'score': 1.0},
{'identifier': '3BOM', 'score': 1.0},
{'identifier': '2EB8', 'score': 0.99487975568309},
{'identifier': '3H57', 'score': 0.9898115893937386},
{'identifier': '2D6C', 'score': 0.9847948997690406},
{'identifier': '6ZMY', 'score': 0.9847948997690406},
{'identifier': '1M6C', 'score': 0.9798287246283488},
{'identifier': '1UX8', 'score': 0.9798287246283488}],
'facets': []}
結果
- total_count:検索結果の数
- results_set:検索結果のリスト、identifierキーにPDB ID
一般化した関数を作る
このままだといちいち辞書を手動で作るのが大変なのでなんとか楽をしたい!
Advanced Searchでクエリを作成
検索に使うqueryはAdvanced Searchを使うことで簡単に作ることが可能
Search Examplesを参考にX線で解かれたタンパク質-リガンド複合体を検索するクエリを作ってみる↓
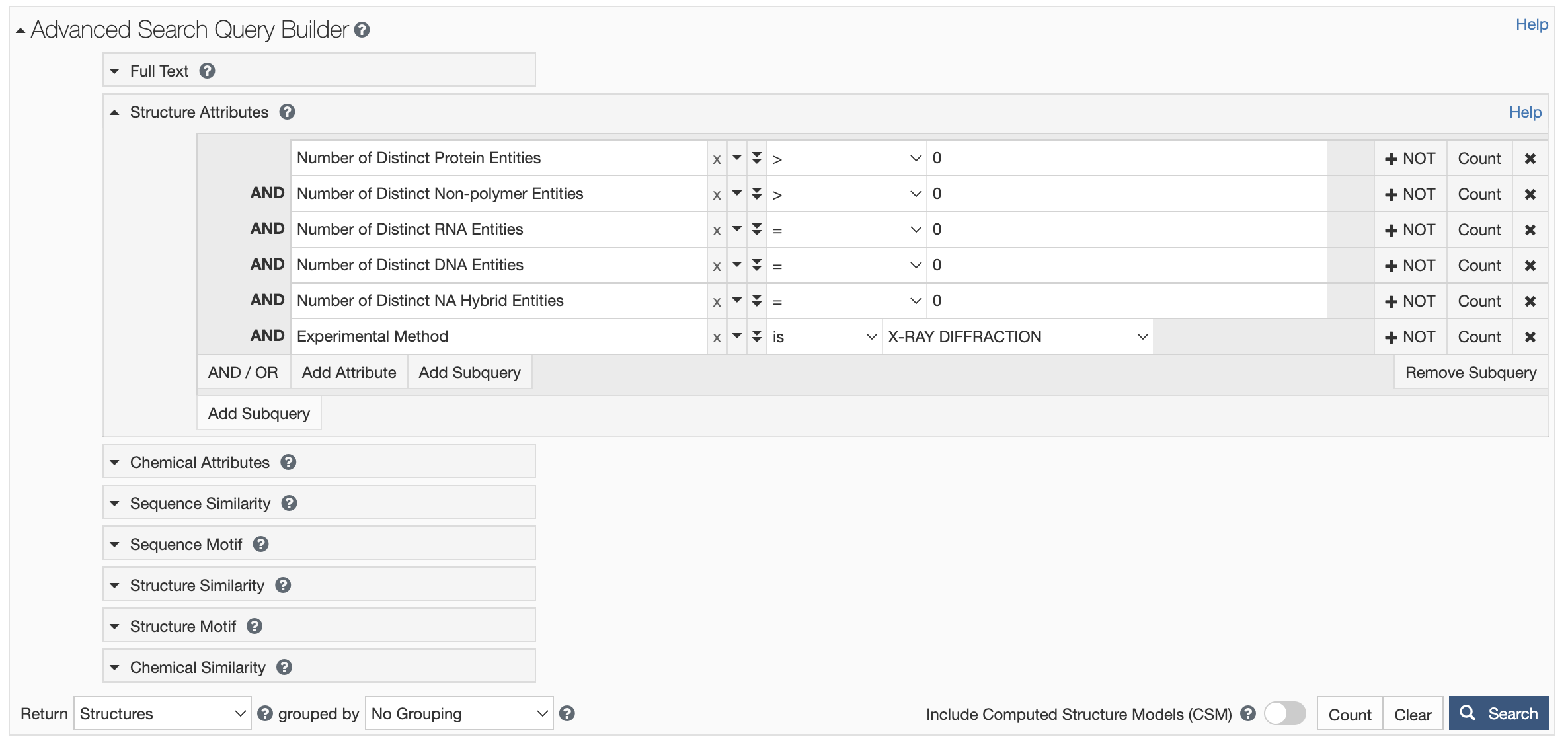
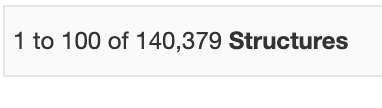
結果は140379構造(2024/01/21)
右上のSearch API を押すことで自動的に作成されたクエリをコピーできる
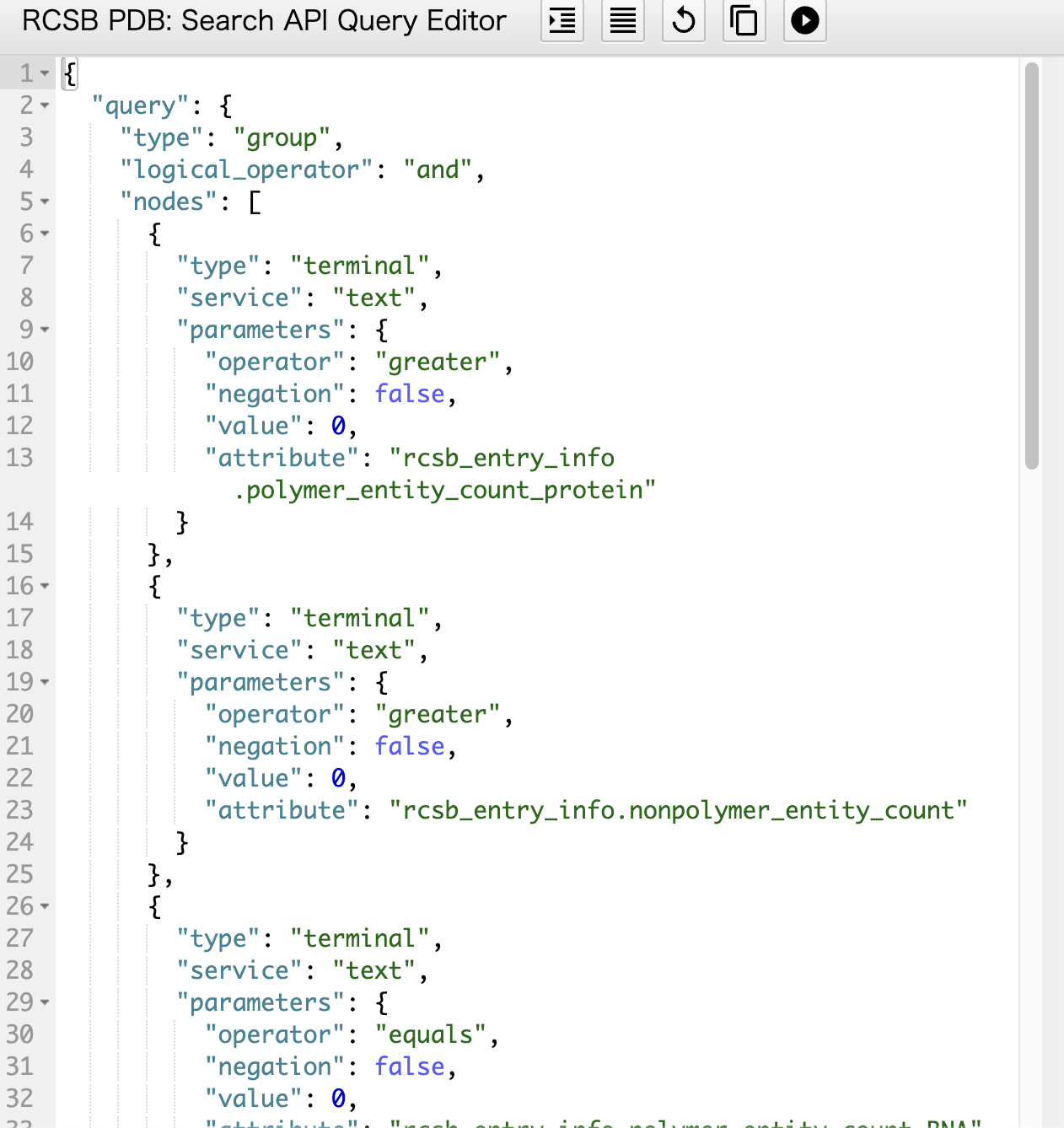
これをquery.jsonファイルを作ってあげて貼り付け
関数の作成
関数を作る前にちゃんとできるかどうか確認
import requests
import os
import json
# クエリファイルのパス
query = 'query.json'
# クエリファイルの読み込み
with open(query, "r") as f:
query = json.load(f)
# Serch API の URL
base_url="https://search.rcsb.org/rcsbsearch/v2/query"
# レスポンスの取得
response = requests.post(base_url, json=query) #getではなくpostを使用
print(response.status_code) # ステータスコードの確認
data = response.json() # 結果をjson形式で取得
print(data) # 結果の確認
# PDBIDを格納するリスト
pdb_ids = []
# dataの内、PDBIDだけを取得
for entry in data['result_set']:
pdb_ids.append(entry['identifier'])
print(data['total_count']) #検索結果数
print(len(pdb_ids)) #取得されたPDBIDの数
print(pdb_ids) #取得されたPDBID
実行結果
200
{'query_id': '7a6d7a9a-8f0c-46fe-bf28-122392a07693', 'result_type': 'entry', 'total_count': 140379, 'result_set': [{'identifier': '101M', 'score': 1.0}, {'identifier': '102L', 'score': 1.0}, {'identifier': '102M', 'score': 1.0},
####省略####
{'identifier': '193L', 'score': 1.0}, {'identifier': '194L', 'score': 1.0}, {'identifier': '195L', 'score': 1.0}], 'facets': []}
140379
100
['101M', '102L', '102M', '103L', '103M', '104M', '105M', '106M', '107L', '107M', '108L', '108M', '109L', '109M', '10GS', '110L', '110M', '111L', '111M', '112L', '112M', '113L', '114L', '115L', '117E', '118L', '119L', '11AS', '11BA', '11BG', '11GS', '120L', '121P', '122L', '123L', '125L', '126L', '127L', '128L', '129L', '12AS', '12CA', '12GS', '130L', '131L', '138L', '139L', '13GS', '13PK', '140L', '141L', '142L', '143L', '144L', '145L', '146L', '147L', '148L', '14GS', '151L', '152L', '155C', '155L', '156L', '157L', '158L', '159L', '160L', '161L', '162L', '163L', '164L', '165L', '166L', '16GS', '16PK', '16VP', '170L', '172L', '173L', '174L', '176L', '178L', '17GS', '181L', '182L', '183L', '184L', '185L', '186L', '187L', '188L', '18GS', '190L', '1914', '191L', '192L', '193L', '194L', '195L']
このままだと100行しか取得できないのでquery.jsonの"request_options"の"paginate"を変更してみる↓
変更前
"request_options": {
"paginate": {
"start": 0,
"rows": 100
},
変更後
"request_options": {
"paginate": {
"start": 0,
"rows": 150000
},
実行結果
{'status': 400, 'message': 'JSON schema validation failed for query: {"query":{"type":"group",
### 省略 ###
Errors: numeric instance is greater than the required maximum (maximum: 10000, found: 150000).', 'link': 'https://search.rcsb.org/redoc/index.html'}
どうやら10000までしか取得できないらしい
ならばwhile文で無理やり回せばOK
import requests
import os
import json
# クエリファイルのパス
query = 'query.json'
# クエリファイルの読み込み
with open(query, "r") as f:
query = json.load(f)
# Serch API の URL
base_url="https://search.rcsb.org/rcsbsearch/v2/query"
start = 0
rows_per_request = 10000
while True:
query["request_options"]["paginate"]["start"] = start
query["request_options"]["paginate"]["rows"] = rows_per_request
response = requests.post(base_url, json=query)
data = response.json()
if response.status_code != 200:
break
for entry in data['result_set']:
pdb_ids.append(entry['identifier'])
if start + rows_per_request > data['total_count']:
break
else:
start += rows_per_request
print(data['total_count'])
print(len(pdb_ids))
print(pdb_ids[:10])
print(pdb_ids[-10:])
実行結果
140379
140379
['101M', '102L', '102M', '103L', '103M', '104M', '105M', '106M', '107L', '107M']
['9LDT', '9LPR', '9NSE', '9PAP', '9PTI', '9RNT', '9RSA', '9RUB', '9XIA', '9XIM']
どうやら成功した様子
あとはいい感じに関数を作ってみる
import requests
import os
import json
def get_pdb_ids(query, filename="pdb_ids.txt", save=True, save_dir="data", verbose=True, base_url="https://search.rcsb.org/rcsbsearch/v2/query", rows_per_request=10000):
if isinstance(query, str):
with open(query, "r") as f:
query = json.load(f)
elif isinstance(query, dict):
pass
start = 0
pdb_ids = []
while True:
query["request_options"]["paginate"]["start"] = start
query["request_options"]["paginate"]["rows"] = rows_per_request
response = requests.post(base_url, json=query)
data = response.json()
for entry in data['result_set']:
pdb_ids.append(entry['identifier'])
if start + rows_per_request > response.json()['total_count']:
break
else:
start += rows_per_request
if save:
filename = os.path.join(save_dir, filename)
with open(filename, "w") as f:
for pdb_id in pdb_ids:
f.write(pdb_id + "\n")
if verbose:
print(f"pdb ids are saved in {filename}")
return pdb_ids, filename
関数の実行
pdb_ids, path = get_pdb_ids(query="query.json", save=True, save_dir="data")
print(f'取得されたPDB:{len(pdb_ids)}')
print(f'保存されたファイルパス:{path}')
print(f'取得されたPDBのIDの例:{pdb_ids[:10]}')
print(f'取得されたPDBのIDの例:{pdb_ids[-10:]}')
実行結果
pdb ids are saved in data/pdb_ids.txt
取得されたPDB:140379
保存されたファイルパス:data/pdb_ids.txt
取得されたPDBのIDの例:['101M', '102L', '102M', '103L', '103M', '104M', '105M', '106M', '107L', '107M']
取得されたPDBのIDの例:['9LDT', '9LPR', '9NSE', '9PAP', '9PTI', '9RNT', '9RSA', '9RUB', '9XIA', '9XIM']
いい感じに感じにできました!
他のクエリでも対応できるハズ
Advanced Search:RCSB PDB
Queryの参考:Search Examples