この記事はIoTLT Advent Calendar 2019(Neo)の21日目の記事です。
作ったもの
今回はAmazon Rekognitionを使った職場のプリンを守る警備システムを作りました。

これで大切な職場のプリンを守ります。
aNo研様のSIerIoTLT vol.16発表で職場のプリンを守る技術を知り、警備といえばプリンだなと思い製作しました。
今回はRaspberry Piのプログラムをメインに記事を書きました。
他の部分に興味のある方がいらっしゃいましたらコメント頂けると嬉しいです。
使い方
オーナー、過去に人のプリンを食べた人(=犯人)、怪しい人の3種類の人間を識別します。
オーナーが現れた場合は動作していることをTwitterで報告します。
犯人が現れた場合はゴム鉄砲を発射し警告音を鳴らします。同時にゴム鉄砲発射直後のカメラ画像を送りオーナーはTwitterで確認できます。
オーナー、犯人以外の人が現れた場合は怪しい人と認識。警告音で威嚇し犯人同様カメラ画像をTwitterでカメラ画像を確認できます。
※予めオーナーと犯人の顔写真はAmazon Rekognitionに登録します。
構成
Raspberry Pi(ハードウェア)
おおよその構成はこんな感じです。
色々雑ですが、レゴを使ってカメラモジュールとゴム鉄砲を固定しています。

Raspberry Pi(ソフトウェア)
おおよその流れは以下の通りです。
- Amazon Rekognitionに予め所有者と犯人の2種類の顔を登録します。
- CameraModuleで画像を取得しまずOpenCVでカメラ内に人の顔があるか検知します。
- 顔があればboto3経由でAmazon Rekognitionにカメラ映像を送り問い合わせを行います。
- Amazon Rekognitionはカメラ映像にある顔が登録された所有者と犯人である確率を返します。それを元に所有者/犯人/(どちらでもない)怪しい人を判断します。
- 所有者であればIFTTT経由で動作状況をTwitterで報告します。
- 犯人であれば以下の動作をします。
- Pigpio経由でServoを動かしゴム鉄砲を発射!
- ゴム鉄砲発車後の画像を取得。
- 警告音を出します。
- S3にboto3経由でカメラ画像をアップしてIFTTT経由で所有者にTwitterで報告します。
- 怪しい人であれば以下の動作をします。
- 警告音を出します。
- S3にboto3経由でカメラ画像をアップしてIFTTT経由で所有者にTwitterで報告します。
Raspberry Piのプログラムはこちら。
# -*- coding: utf-8 -*-
from picamera.array import PiRGBArray
from picamera import PiCamera
import cv2, time, boto3
import requests
import urllib.request, json
import datetime
import numpy as np
from PIL import ImageFont, ImageDraw, Image
import subprocess
from datetime import datetime as dt
import pigpio
# Pi Camera
FRAME_W = 640
FRAME_H = 480
# Open CV
CASC_PATH = '/usr/local/share/opencv4/lbpcascades/lbpcascade_frontalface.xml'
FRAME_RATE = 32
MIN_FACE_SIZE = 10
CHECK_FILE = 'check.jpg'
# AWS Rekognition
COLLECTION_ID = 'test'
THRESHOLD = 70
MAX_FACES = 1
SERVICE_NAME = 'rekognition'
LOCATE = 'ap-northeast-1'
PERSON_TYPE = {0:'怪しい人', 1:'Owner', 2:'犯人', 3:''}
# S3
S3_URL = 'https://s3-ap-northeast-1.amazonaws.com/'
BUCKET_NAME = 'test'
# IFTTT (Webhooks Settings)
TRIGGER = 'rekognition'
URL1 = 'https://maker.ifttt.com/trigger/'
URL2 = '/with/key/xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
EVENT = {0:'other', 1:'owner', 2:'enemy', 3:''}
MESSAGE = {0:'怪しい奴がきたよ', 1:'ちゃんと監視してるよ!', 2:'犯人やっつけた!', 3:''}
# Servo
GPIO_NO = 18
GPIO_READY = 500
GPIO_FIRE = 1600
def rotate_servo(servo, angle):
# サーボ操作
if -90 <= angle <= 90:
d = ((angle + 90) * 9.5 / 180) + 2.5
servo.ChangeDutyCycle(d)
else:
raise ValueError("angle")
def send_message(msg_no, file_name):
# S3にファイルをアップロード
dt_now = dt.now()
s3_filename = 'img_' + dt_now.strftime('%m%d_%H%M%S') + '.jpg'
s3 = boto3.resource('s3')
s3.Bucket(BUCKET_NAME).upload_file(file_name, s3_filename, ExtraArgs={"ContentType": "image/jpeg"})
s3_url = S3_URL + BUCKET_NAME + "/" + s3_filename
# IFTTT URL設定
url = URL1 + TRIGGER + URL2
method = "POST"
headers = {"Content-Type" : "application/json"}
date = datetime.datetime.now()
message = MESSAGE[msg_no] + ' ' + str(date.hour) + '-' + str(date.minute)
print('Send Message:', message)
# PythonオブジェクトをJSONに変換する
obj = {"value1" : message, "value2" : s3_url}
json_data = json.dumps(obj).encode("utf-8")
# httpリクエストを準備してPOST
request = urllib.request.Request(url, data=json_data, method=method, headers=headers)
with urllib.request.urlopen(request) as response:
response_body = response.read().decode("utf-8")
print('response:',response_body)
def aws_rekognition(cl):
#顔認証
img = open(CHECK_FILE, 'rb')
img_byte = img.read()
try:
response = cl.search_faces_by_image(CollectionId=COLLECTION_ID,
Image={'Bytes':img_byte},
FaceMatchThreshold=THRESHOLD,
MaxFaces=MAX_FACES)
except:
return 3
print('Rekognition!')
person=""
#カメラに複数人写っていた場合最後の人を判定(手抜き)
for faceRecord in response['FaceMatches']:
person = faceRecord['Face']['ExternalImageId']
if person.endswith("owner"):
rtn = 1
elif person.endswith("bad"):
rtn = 2
else:
rtn = 0
return rtn
# GUI処理
def face_maker(frame, faces, rtn):
# フォントを読み込み
font = ImageFont.truetype('TanukiMagic.ttf', 48)
for (x, y, w, h) in faces:
# 見つかった顔を矩形で囲む
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
img_pil = Image.fromarray(frame)
draw = ImageDraw.Draw(img_pil)
draw.text((30, 60), PERSON_TYPE[rtn], font = font, fill = (128,255,0))
frame = np.array(img_pil)
return frame
def main():
# 初期化
faceCascade = cv2.CascadeClassifier(CASC_PATH)
camera = PiCamera()
camera.resolution = (FRAME_W, FRAME_H)
camera.framerate = FRAME_RATE
camera.rotation = 180
rawCapture = PiRGBArray(camera, size=(FRAME_W, FRAME_H))
time.sleep(0.1)
client = boto3.client(SERVICE_NAME,LOCATE)
pi = pigpio.pi()
old_rtn = 3
# ループ
for image in camera.capture_continuous(rawCapture, format="bgr", use_video_port=True):
frame = image.array
#frame = cv2.flip(frame, -1) #上下反転
camera.start_preview()
# OpenCVの顔検出をグレースケールで実施
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
gray = cv2.equalizeHist( gray )
faces = faceCascade.detectMultiScale(gray, 1.1, 3, 0, (MIN_FACE_SIZE, MIN_FACE_SIZE))
# 表示調整用
#frame = cv2.resize(frame, (800,600))
# 顔あり
if faces is not None:
# 顔ファイル出力
cv2.imwrite(CHECK_FILE, frame)
time.sleep(0.01)
# AWS Rekognition
rtn = aws_rekognition(client)
if rtn is None:
rtn = 3
frame = face_maker(frame,faces,rtn)
# ビデオに表示
cv2.imshow('Video', frame)
time.sleep(0.1)
# 同じ結果の場合は何もしない
print('rtn:', rtn, ' old_rtn:', old_rtn)
if old_rtn != rtn:
if(rtn == 0):
# 怪しい人
subprocess.call("mpg321 warning.mp3", shell=True)
send_message(rtn, CHECK_FILE)
if(rtn == 1):
# オーナー
send_message(rtn, CHECK_FILE)
if(rtn == 2):
# 過去に人のプリンを食べたことがある人
pi.set_servo_pulsewidth(GPIO_NO, GPIO_READY)
time.sleep(0.2)
pi.set_servo_pulsewidth(GPIO_NO, GPIO_FIRE)
subprocess.call("mpg321 fire.mp3", shell=True)
# 攻撃後の画像をTwitterに送る
camera.capture('fire.jpg')
send_message(rtn, 'fire.jpg')
old_rtn = rtn
# qを押されたら終了
key = cv2.waitKey(1) & 0xFF
rawCapture.truncate(0)
if key == ord("q"):
break
time.sleep(0.01)
cv2.destroyAllWindows()
exit
if __name__ == "__main__":
main()
IFTTT
WebhookとTwitterとの連携設定をします。
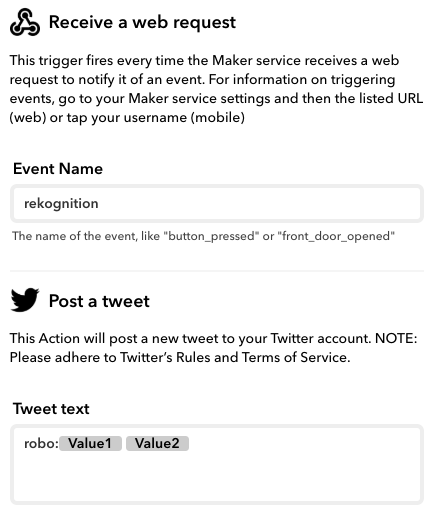
Amazon Rekognition
アマゾンウェブサービス(AWS)のAmazon Rekognition は、深層学習に基づいた画像認識および画像分析をアプリケーションに簡単に追加できるサービスです。
予めオーナー(名前の末尾がowner)と犯人(名前の末尾がbad)の画像をAmazon Rekognitionに登録しています。
上記プログラムでboto3を利用してAWSにアクセスするとカメラ映像に近い画像名を返します。