目次
1.RNN
2.BPTT
3.LSTM
4.GRU
5.双方向RNN
6.Seq2Seq
7.Word2vec
8.Attention
9.実装演習
10.確認テスト
1. RNN
CNNでは画像などのデータを扱ったが、RNN(Recurrent Neural Network)では文章などの時系列データを扱うことができる。例えば、ある文章を順にRNNに入力し、次に現れる単語を推定するといったタスクを行うことができる。
RNNの特徴は、RNNの出力を再度RNNに入力することで過去のデータを記憶しながら、次の出力値を推定する点である。以下の図で、x、hがそれぞれRNNの入力、出力である。

以下の図は、RNNを時間に沿って展開したものである。この展開したニューラルネットワークは通常のニューラルネットワーク同様に誤差逆伝播法により学習を行うことができる。

RNNの箱の中身は以下。

数式で表すと下記になる。
$\boldsymbol{m} = \boldsymbol{h_{prev} W_h} $
$\boldsymbol{p} = \boldsymbol{x W_x}$
$\boldsymbol{k} = \boldsymbol{m} + \boldsymbol{p}$
$\boldsymbol{t} = \boldsymbol{k} + \boldsymbol{b}$
$\boldsymbol{h_{next}} = \tanh (\boldsymbol{t}) $
$\boldsymbol{y_t} = \mathrm{softmax} (\boldsymbol{h_{next} W_{out}} + \boldsymbol{c})$
2. BPTT
RNNでの誤差逆伝播法をBPTT(BackPropagation Trough Time)と呼ぶ。$\boldsymbol{h}_{prev}, \boldsymbol{W}_h, \boldsymbol{W}_x, \boldsymbol{b}$についての偏微分は下記の通り。これらを用いて勾配更新を行う。
\begin{align}
\frac{\partial \boldsymbol{h}_{next}}{\partial \boldsymbol{h}_{prev}} &= \frac{\partial \boldsymbol{h}_{next}}{\partial \boldsymbol{t}} \times \frac{\partial \boldsymbol{t}}{\partial \boldsymbol{k}} \times \frac{\partial \boldsymbol{k}}{\partial \boldsymbol{m}} \times \frac{\partial \boldsymbol{m}}{\partial \boldsymbol{h}_{prev}} \\
&= \frac{\partial \boldsymbol{h}_{next}}{\partial \boldsymbol{t}} \times 1 \times 1 \times \boldsymbol{W}_h\\
&= \frac{\partial \boldsymbol{h}_{next}}{\partial \boldsymbol{t}} \times \boldsymbol{W}_h
\\
\end{align}
\begin{align}
\frac{\partial \boldsymbol{h}_{next}}{\partial \boldsymbol{W}_h} &= \frac{\partial \boldsymbol{h}_{next}}{\partial \boldsymbol{t}} \times \frac{\partial \boldsymbol{t}}{\partial \boldsymbol{k}} \times \frac{\partial \boldsymbol{k}}{\partial \boldsymbol{m}} \times \frac{\partial \boldsymbol{m}}{\partial \boldsymbol{W}_h} \\
&= \frac{\partial \boldsymbol{h}_{next}}{\partial \boldsymbol{t}} \times 1 \times 1 \times \boldsymbol{h}_{prev}\\
&= \frac{\partial \boldsymbol{h}_{next}}{\partial \boldsymbol{t}} \times \boldsymbol{h}_{prev}
\\
\end{align}
\begin{align}
\frac{\partial \boldsymbol{h}_{next}}{\partial \boldsymbol{W}_x} &= \frac{\partial \boldsymbol{h}_{next}}{\partial \boldsymbol{t}} \times \frac{\partial \boldsymbol{t}}{\partial \boldsymbol{k}} \times \frac{\partial \boldsymbol{k}}{\partial \boldsymbol{p}} \times \frac{\partial \boldsymbol{p}}{\partial \boldsymbol{W}_x} \\
&= \frac{\partial \boldsymbol{h}_{next}}{\partial \boldsymbol{t}} \times 1 \times 1 \times \boldsymbol{x}\\
&= \frac{\partial \boldsymbol{h}_{next}}{\partial \boldsymbol{t}} \times \boldsymbol{x}
\\
\end{align}
\begin{align}
\frac{\partial \boldsymbol{h}_{next}}{\partial \boldsymbol{b}} &= \frac{\partial \boldsymbol{h}_{next}}{\partial \boldsymbol{t}} \times \frac{\partial \boldsymbol{t}}{\partial \boldsymbol{b}} \\
&= \frac{\partial \boldsymbol{h}_{next}}{\partial \boldsymbol{t}} \times 1 \\
&= (1-\tanh^2 (\boldsymbol{t}))
\\
\end{align}
RNNの問題点
RNNでは時間経過が大きくなった場合に、時間方向に層が深くなるため、誤差逆伝播において勾配消失または勾配爆発(勾配が指数関数的に増加)が発生しやすくなる。勾配消失の対策としては、微分値が大きくなる活性化関数を利用したり正則化を行う。勾配爆発にはクリッピングなどを行う。

3. LSTM
LSTM(Long Short-Term Memory)では、CEC(記憶セル)を用いることでLSTMにより勾配消失と勾配爆発を防ぐ。LSTMの構造は以下。特徴として、CEC、入力・出力・忘却ゲートを持つ。
入力ゲートでは$x(t)W_i$と$h(t-1)u_i$から$i(t)$を計算する。この$i(t)$により入力$a(t)$の値調整を行う。次にCECでは$i(t)・a(t)$に前回のCECの出力$c(t-1)$に$f(t)$を乗算したものを足し合わせることで、記憶している情報を反映させる。CECには過去の情報が継続して保管されてしまうことを避けるため、忘却ゲートで$f(t)$の値を調整する。出力ゲートは入力ゲートと同様にCECからの出力$g(c(t))$に$o(t)$を乗算し調整を行う。

4. GRU
LSTMは3種類のゲートとCECがあり、重みパラメータが多く計算量が大きい。GRUでは重みパラメータの数を大幅に削減。リセットゲートと更新ゲートが存在。

5. 双方向RNN
未来の情報を加味することで精度を向上させる。機械翻訳などに利用される。

6. Seq2Seq
時系列データを別の時系列データに変換。日本語から英語への機械翻訳など。Seq2SeqはEncoder-Decoderモデルと呼ばれる。EncoderはRNNを利用して、時系列データを隠れ状態ベクトルに変換。隠れ状態ベクトルをDecoderも入力して与えることで別の時系列データを生成。

HRED
過去n-1 個の発話から次の発話を生成する。Seq2seqでは会話の文脈無視で応答がなされたが、HREDでは前の単語の流れに即して応答されるため、より人間らしい文章が生成される。HREDではSeq2SeqにプラスしてContext RNNが用いられる。Context RNNではEncoderのまとめた各文章の系列をまとめて、これまでの会話コンテキスト全体を表すベクトルに変換する。
VHRED
HREDに、VAEの潜在変数の概念を追加したもの。VAEの潜在変数の概念を追加することで解決した構造
オートエンコーダー
教師なし学習の一つ。入力層より中間層のサイズを小さくすることで次元削減を行う。
VAE
通常のオートエンコーダーの場合、何かしら中間層にデータを押し込めているものの、その構造がどのような状態かわからない。VAEは中間層に正規分布N(0,1)を仮定したもの
7. Word2vec
語の表現にはカウントベースによるものと推論ベースによるものの2種類がある。
カウントベースには、与えられたデータを全て用いて計算しなければならず、時間がかかる。
それに対して、推論ベースであれば与えられたデータの一部からから学習が可能で、データを追加して与えて計算させることも可能。
Word2vecは推論ベースの語表現である。
Word2vecには2種類のモデルが存在する。1つはCBoW、もうひとつはSkip-gramである。
CBOWモデルでは、文中の抜けおちた単語の周辺の単語から抜けおちた単語を推定する手法である。
反対に、Skip-gramは、ある単語に隣接する単語を推定する。
CBOW
CBOWは、Continuous Bag Of Wordsの略である。文中の抜けおちた単語の周辺の単語から抜けおちた単語を推定する方法。
CBOW概要
コーパス(学習に用いるテキストデータ)のなかから語彙を取りだして、各単語にIDを振る。
また、単語をone-hot表現(ベクトルの要素のなかで1つだけ1で他が0であるようなベクトル)で表す。これをone-hotベクトルと呼ぶ。one-hotベクトルの長さは、コーパスの語彙数になる。
抜け落ちた単語の前後1つずつから抜け落ちた単語を推定する場合、前後の単語1つずつをone-hotベクトルにして入力層に入力する。2つの単語(one-hotベクトル)に重みをかけて足し合わせて作成した行列に別の重み行列をかけ合わせ、語彙数長のベクトルを作る。このとき、入力にかけあわせた重み行列が各単語の分散表現(単語の意味を捉えたベクトル)になっている。
8. Attention
Seq2Seqは長い文章への対応が難しい。我々が翻訳を行うとき、ある単語に注目して単語の変換を随時行っている。つまり、翻訳先の単語と対応関係にある翻訳元の単語を選び出し、その情報を利用して翻訳を行っている。Attentionでは「入力と出力のどの単語が関連しているのか」の関連度を学習して、それを利用して翻訳を行う。

9. 実装演習
Simple RNN
重みの初期値、学習率、中間層の層数を変化させて結果を確認する。まず基準となるモデルでは最初は誤差が1程度であるが学習が進むに連れて0に近づいていることがわかる。重みの初期値を1 → 0.01に変更すると学習を繰り返しても誤差は減らない。重みが小さく勾配消失が発生しているため、誤差が減らないと考えられる。学習率を0.1 → 0.01に変更しても学習を繰り返すにつれて微減する傾向はあるものの、誤差は十分に小さくならない。学習率が小さく学習が効率的に進まないためだと思われる。中間層の層数を16層 → 160層に変更すると学習が進むにつれて誤差が小さくなるものの、16層の場合と比べると誤差が大きい。層が深すぎることで余計な過去の時系列データまで捉えてしまい、その結果誤差が16層の場合ほどに小さくはならなかったと考えられる。
基準モデル(weight_init_std = 1, learning_rate = 0.1, hidden_layer_size = 16)
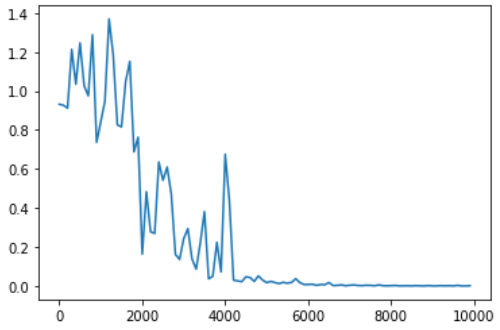
重み初期値を変更(weight_init_std = 0.01, learning_rate = 0.1, hidden_layer_size = 16)
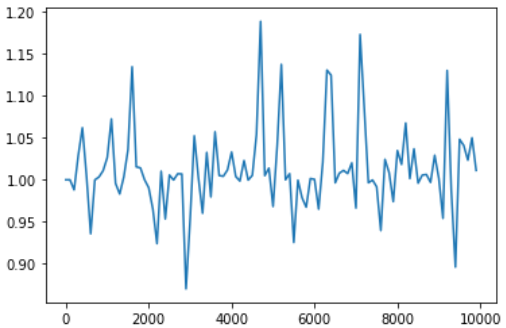
学習率を変更(weight_init_std = 1, learning_rate = 0.01, hidden_layer_size = 16)

中間層の層数を変更(weight_init_std = 1, learning_rate = 0.1, hidden_layer_size = 160)

以下では、初期値としてXavierとHeを採用したものを比較する。Heの方がより早く学習が進んでいることがわかる。
Xavierの初期値


Heの初期値


以下では、活性化関数としてReLUとtanhを用いた場合を比較する。初期値はHeを利用。ReLUでは学習が進んでも誤差が2前後で推移していることから勾配爆発が起きていると思われる。tanh関数は早い段階で誤差が0になっている。勾配が消失せず、また荒漠爆発にもならずに伝播しているためだと思われる。
ReLU

tanh


Sign関数の予測
以下ではSign関数予測を行う。繰返し回数と時系列データを変化させて結果を確認する。時系列データを2 → 5に変更し、繰返し回数を100 → 3000回にすることでSign関数を予測ができるようになっている。
iters_num = 100, maxlen = 2

iters_num = 500, maxlen = 2

iters_num = 500, maxlen = 5

iters_num = 3000, maxlen = 5

10. 確認テスト
確認テスト P.23
RNNのネットワークには大きくわけて3つの重みがある。1つは入力から現在の中間層を定義する際にかけられる重み、1つは中間層から出力を定義する際にかけられる重みである。残り1つの重みについて説明せよ。
(回答):過去の出力を現在のRNNに入力する際にかけられる重
演習チャレンジ P.26

確認テスト P.45

確認テスト P.78

(回答):忘却ゲート
演習チャレンジ P.79

(回答):3
確認テスト P.88

(回答):LSTMはパラメータが多く計算量が大きい。CECは勾配が1のため学習機能がないため、入力・出力・忘却ゲートで学習。
演習チャレンジ P.90

(回答):4
演習チャレンジ P.92

(回答):LSTMに比べ、GRUは重みパラメータが少なく計算量が小さい。
確認テスト P.109

(回答):2
確認テスト P.119

(回答):Seq2Seqは時系列データを別の時系列データに変換する。HREDはコンテキストを汲みとって時系列データを生成する。
HREDは簡単な応答を返しがちなため、VAEを取り入れてより複雑な応答ができるようにしたのがVHRED。
確認テスト P.119

(回答):確率分布