はじめに
Ray関連の文献から得た情報をメモしていく(随時更新)
Rayとは
- Python用の分散処理実行フレームワーク
- 分散処理について詳しくなくても使いやすい(らしい)
- 複数のマシン(クラスタ)で分散処理を行える
- クラスタはHead nodeとWorker nodeからなる
DrirverやWoerker、Object storeなどは後述。

プログラミングモデル
(よくわからないが、)Rayの差別化ポイントは「actor 」と「task-parallel programming abstraction」にあるらしい。
Ray provides both an actor and a task-parallel programming abstraction. This unification differentiates Ray from related systems like CIEL, which only provides a task-parallel abstraction, and from Orleans [14] or Akka [1], which primarily provide an actor abstraction
-
Ray API
- RayのAPIは以下の通り

- RayのAPIは以下の通り
-
Tasks
- Worker上でRemote functionを実行すること(これだけだと意味不明)
- 以下のコードの
f.remote(a, b)がTaskを指している - クラスタ内のあるマシンで実行される関数のこと
@ray.remote
def f(a, b):
return a+b
a = 3
b = 4
result = f.remote(a, b)
A task represents the execution of a remote function on a stateless worker. When a remote function is invoked, a future representing the result of the task is returned immediately. Futures can be retrieved using ray.get() and passed as arguments into other remote functions without waiting for their result. This allows the user to express parallelism while capturing data dependencies.
Remote functions operate on immutable objects and are expected to be stateless and side-effect free: their outputs are determined solely by their inputs. This implies idempotence, which simplifies fault tolerance through
function re-execution on failure.
-
Actors
- ステートフルな計算処理のこと(これだけじゃ全然わからん)
- 各アクターは、リモートで呼び出すことができ、シリアルに実行されるメソッドを公開する(うーん、わからん)
- 以下のコードの
actor = Actor.remote()の部分でActorをインスタンシエイトしてる。Actorはこのインスタンス化されたactorを指している - メソッドの実行はリモートで実行される点でTaskに似ているが、ステートフルなwoker上(*1)で実行される
(*1) 以降で出てくるWokerの定義と齟齬あり。Workerはステートレスなプロセスと定義されていることから、上の文章が意味しているところはメソッドがステートフルな「プロセス」で実行されるということだと思われる。
@ray.remote
class Actor():
def f(self, a, b):
return a+b
actor = Actor.remote()
a = 3
b = 4
result = actor.f.remote(a, b)
An actor represents a stateful computation. Each actor exposes methods that can be invoked remotely and are executed serially. A method execution is similar to a task, in that it executes remotely and returns a future, but differs in that it executes on a stateful worker. A handle to an actor can be passed to other actors or tasks, making it possible for them to invoke methods on that actor.
-
Tasks vs. Actors

アーキテクチャ

アプリケーションレイヤ
-
Driver
- ユーザプログラムを実行するプロセス
A process executing the user program.
-
Worker
- Taskを実行するステートレスなプロセス
- 複数のTaskにわたってステートを維持できない
- Driverや他のWorkerによって呼び出される
A stateless process that executes tasks (remote functions) invoked by a driver or another worker. Workers are started automatically and assigned tasks by the system layer. When a remote function is declared, the function is automatically published to all workers. A worker executes tasks serially, with no local state maintained across tasks.
-
Actor
- 公開するメソッドのみを実行するステートフルプロセス
- Workerとは異なり、DriverやWorkerにより明示的にインスタンシエイトされる
A stateful process that executes, when invoked, only the methods it exposes. Unlike a worker, an actor is explicitly instantiated by a worker or a driver. Like workers, actors execute methods serially, except that each method depends on the state resulting from the previous method execution.
システムレイヤ
TaskはボトムアップでDriverやWorkerからLocal SchedulerにSubmitされ、必要な場合にはさらにGlobal Schedulerに転送される。Global Schedulerに転送されることはそれほど多くない。
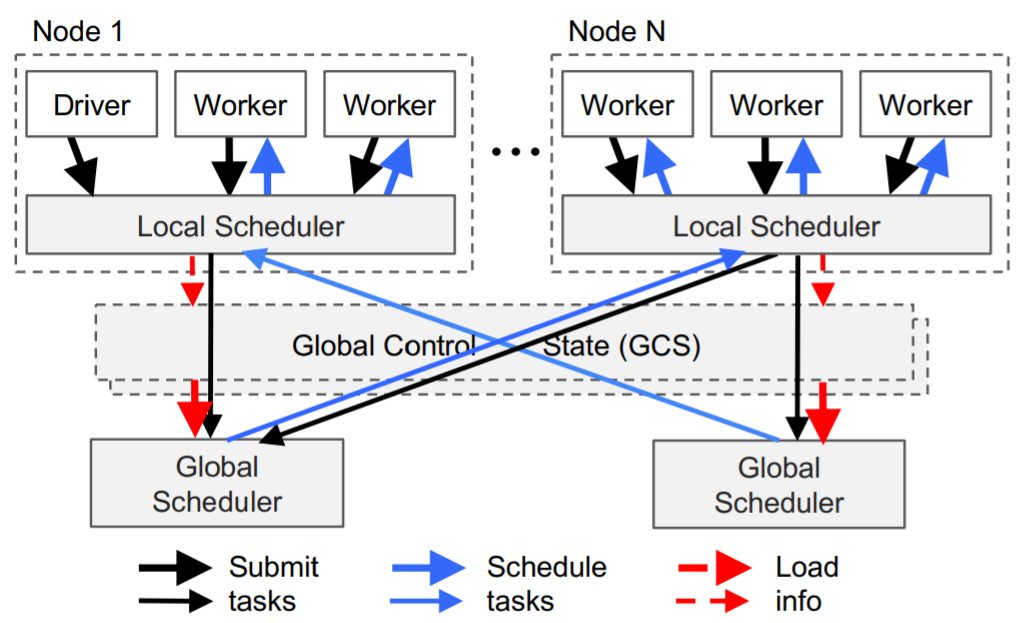
-
Global Control Store (GCS)
The primary reason for the GCS and its design is to maintain fault tolerance and low latency for a system that can dynamically spawn millions of tasks per second. -
Distributed Scheduler
- 毎秒数百万のタスクを動的にスケジュールできる
- SparkやCIEL、Dryadyはせいぜい数十ms程度のレイテンシ
- 基本的にはローカルノードでTaskの処理を行う
- オーバーロードした場、またはGPU等のTask固有の要件を満たさない場合には、リモートノードで処理を行う。
- リモートノードの選定は、(i) Taskがリモートノードでキューされる時間、および(ii) Taskをリモートノードに渡すのにかかる時間の2つの情報をもとに行う。
As discussed in Section 2, Ray needs to dynamically schedule millions of tasks per second, tasks which may take as little as a few milliseconds. None of the cluster schedulers we are aware of meet these requirements. Most cluster computing frameworks, such as Spark [64], CIEL [40], and Dryad [28] implement a centralized scheduler, which can provide locality but at latencies in the tens of ms. Distributed schedulers such as work stealing [12], Sparrow [45] and Canary [47] can achieve high scale, but they either don’t consider data locality [12], or assume tasks belong to independent jobs [45], or assume the computation graph is known [47].
To satisfy the above requirements, we design a twolevel hierarchical scheduler consisting of a global scheduler and per-node local schedulers. To avoid overloading the global scheduler, the tasks created at a node are submitted first to the node’s local scheduler. A local scheduler schedules tasks locally unless the node is overloaded (i.e., its local task queue exceeds a predefined threshold), or it cannot satisfy a task’s requirements (e.g., lacks a GPU). If a local scheduler decides not to schedule a task locally, it forwards it to the global scheduler. Since this scheduler attempts to schedule tasks locally first (i.e., at the leaves of the scheduling hierarchy), we call it a bottomup scheduler.
The global scheduler considers each node’s load and task’s constraints to make scheduling decisions. More precisely, the global scheduler identifies the set of nodes that have enough resources of the type requested by the task,
and of these nodes selects the node which provides the lowest estimated waiting time. At a given node, this time is the sum of (i) the estimated time the task will be queued at that node (i.e., task queue size times average task execution), and (ii) the estimated transfer time of task’s remote inputs (i.e., total size of remote inputs divided by average bandwidth). The global scheduler gets the queue size at each node and the node resource availability via heartbeats, and the location of the task’s inputs and their sizes from GCS. - 毎秒数百万のタスクを動的にスケジュールできる
-
In-Memory Distributed Object Store
- Taskやステートレス処理の入出力を保管する
- Object Storeは各ノードの共有メモリ上に存在すること、同じノード上で稼働しているTask間でゼロコピーデータ共有ができる
- Taskの入力がローカルノード上に無い場合、入力はローカルのObject Storeに複製される
- 複製によって、高頻度アクセスデータによるボトルネックが解消される。また、ローカルメモリ上でのデータの読み書きなので実行時間が最小化される。
To minimize task latency, we implement an in-memory distributed storage system to store the inputs and outputs of every task, or stateless computation. On each node, we implement the object store via shared memory. This allows zero-copy data sharing between tasks running on the same node. As a data format, we use Apache Arrow [2]. If a task’s inputs are not local, the inputs are replicated to the local object store before execution. Also, a task writes its outputs to the local object store. Replication eliminates the potential bottleneck due to hot data objects and minimizes task execution time as a task only reads/writes data from/to the local memory. This increases throughput for computation-bound workloads, a profile shared by many AI applications. For low latency, we keep objects entirely in memory and evict them as needed to disk using an LRU policy
処理の流れ
Taskの実行
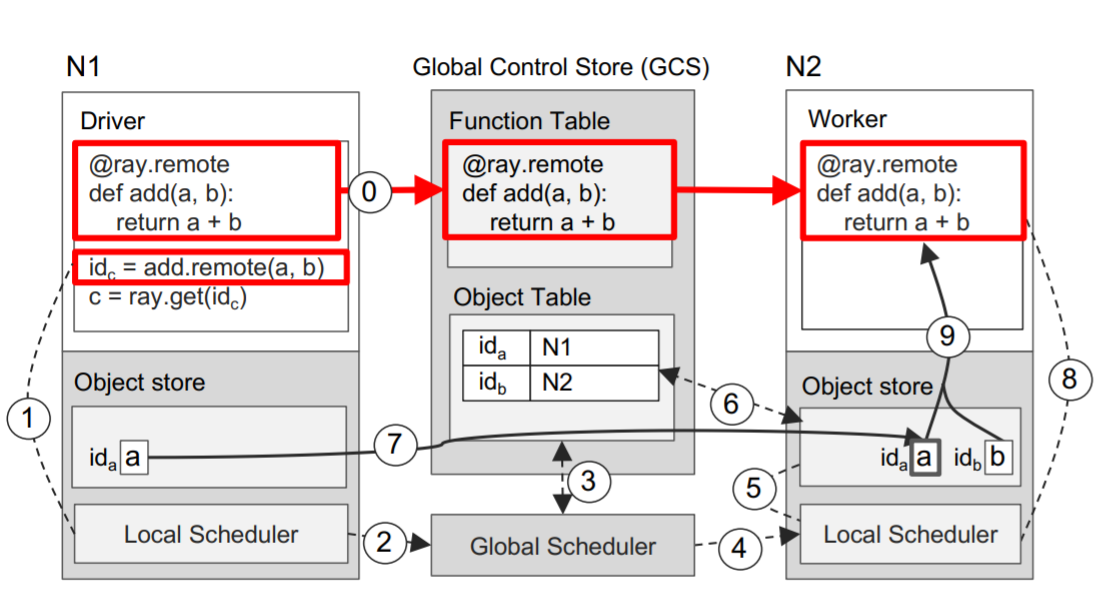
- ⓪ DriverがRemote function **add()**をGCSのFunction Tableに登録し、それをすべてのWorkerに配布する。
- ① Driverが関数演算処理**add(a, b)**をLocal SchedulerにSubmitする。
- ② ノードN1のLocal Schedulerが関数演算処理add(a, b) (= Task)
をGlobal Schedulerに転送する。 - ③ Global Schedulerが関数演算処理**add(a, b)**の引数をGCSのObject Tableで探す。
- ④ そして、引数bが保管されているノードN2のLocal SchedulerにTaskを渡す。
- ⑤ ノードN2のLocal SchedulerがLocal Object Store内に関数演算処理**add(a, b)**の引数がストアされているかチェックする。
- ⑥ ノードN2のLocal Object StoreがObject aを補完していないので、GCSのObject Tableにaの保管場所を確認しにいく。
- ⑦ Object aがN1に保管されていることを確認し、N2のLocal Object Store内にObject aを複製する。
- ⑧ 関数演算処理add(a, b)の引数がすべてN2のLocal Object Store内に保管されているので、N2のLocal SchedulerがWorkerを呼び出す。
- ⑨ Wokerが引数を取得する
Taskの結果取得
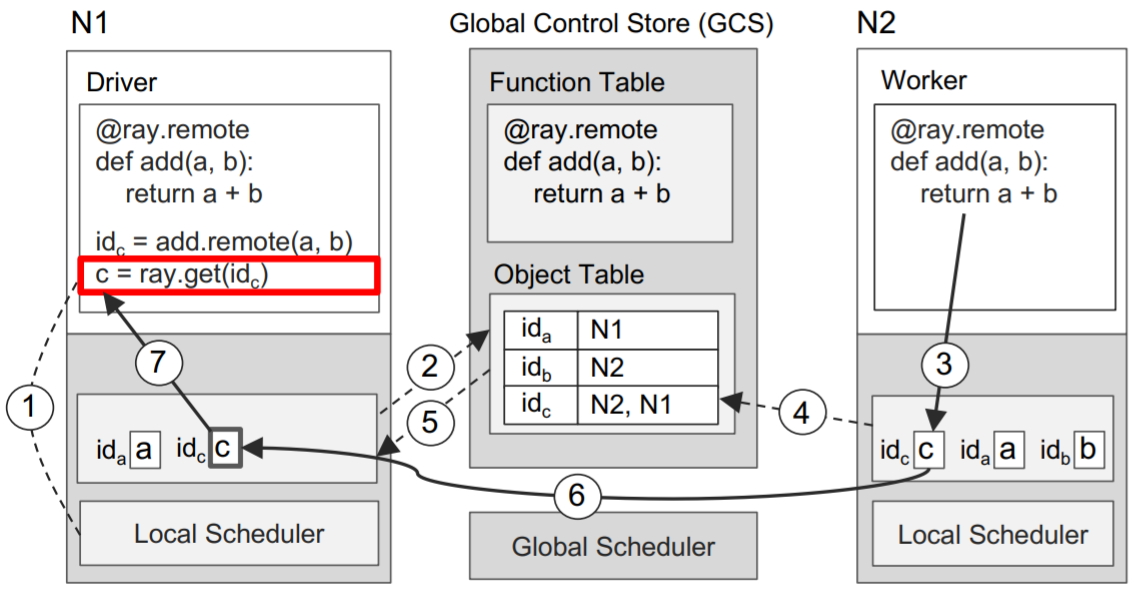
- ① **ray.get()**の実行によって、DriverがLocal Object Storeにvalue cが存在するかidを元にチェックする。
- ② Local Object Storeに値cが存在しないため、居場所をGCSのObjet Tableに確認しにいく。この時点でcのエントリ(=id)が存在していない、つまりcがまだ作成されていない。そこで、N1のLocal Object StoreがObject Tableにコールバックを登録する。コールバックはcのエントリが作成されたタイミングで実行される。
- ③ その間にN2ではadd(a, b)の処理が完了し、Local Object Storeに結果cを保管する。
- ④ そして、N2のLocal Object StoreがcのエントリをGCSに加える。
- ⑤ GCSがN1のLocal Object Storeにコールバックをトリガーする。つまり、cのエントリが登録されたことを知らせる。
- ⑥ N1のLocal Object Storeが値cを複製する。
- ⑦ 値cを**ray.get()**に返す。
Ray clusterの構築方法
以下の3種類の構築方法がある。
-
ローカルマシン
ローカルKubernetesでRay cluster模擬 -
Cloud provider
AWS EC2、AWS EKS -
オンプレ上のKubernetes
スキップ
独自用語
RayのDocumentで何を指しているのかわからない単語があったので、単語の定義が記載されているものは抜粋し、定義が見つからないものは自身の解釈を記載しました。Ray関連のドキュメントで度々目にするCloud providerは一般的な用語らしく、AWSやGCP、Azureを指しています。
Actor
An actor represents a stateful computation. Each actor exposes methods that can be invoked remotely and are executed serially. A method execution is similar to a task, in that it executes remotely and returns a future, but differs in that it executes on a stateful worker. A handle to an actor can be passed to other actors or tasks, making it possible for them to invoke methods on that actor.

AsyncActor
Please note that running blocking ray.get or ray.wait inside async actor method is not allowed, because ray.get will block the execution of the event loop.
Dependencies, or Environment(定義)
Anything outside of the Ray script that your application needs to run, including files, packages, and environment variables.
Job(定義)
A period of execution between connecting to a cluster with ray.init() and disconnecting by calling ray.shutdown() or exiting the Ray script.
意訳:ray.init()でクラスターに接続してからray.shutdown()で接続解除するまでの実行期間のこと。
Namespace(定義)
A namespace is a logical grouping of jobs and named actors. When an actor is named, its name must be unique within the namespace.
# using ray client
ray.init("ray://<head_node_host>:10001", namespace="world")
# Will print the information about "world" namespace.
print(ray.get_runtime_context().namespace)
-
Anonymous namespaces(定義)
- When a namespace is not specified, Ray will place your job in an anonymous namespace. In an anonymous namespace, your job will have its own namespace and will not have access to actors in other namespaces.
意訳:JobにnamespaceをつけないことをAnonymous namespaceと呼ぶ。Anonymous namespaceであってもRayがUUIDを使用して勝手にjobにnamespaceをつけている。
- When a namespace is not specified, Ray will place your job in an anonymous namespace. In an anonymous namespace, your job will have its own namespace and will not have access to actors in other namespaces.
Node(解釈)
Rayの分散処理を実行するマシンのこと。AWS上にRay clusterを構築する場合にはマシンはEC2を指す。一方、Kubernetes上にRay clusterを構築する場合にはマシンはPodを指す。i.e. Node = Rayの分散処理を実行するEC2 / Kubernetes Pod
Pool
Ray Application(定義)
A program including a Ray script that calls ray.init() and uses Ray tasks or actors.
Ray cluster(解釈)
Rayの分散処理を実行するマシン群のこと
Remote Class(解釈)
An actor represents a stateful computation. Each actor exposes methods that can be invoked remotely and are executed serially. A method execution is similar to a task, in that it executes remotely and returns a future, but
differs in that it executes on a stateful worker. A handle to an actor can be passed to other actors or tasks, making it possible for them to invoke methods on that actor.
Node上で実行されるPythonクラスのこと。Actorと同じ。
Remote function(定義)
A task represents the execution of a remote function on a stateless worker. When a remote function is invoked, a future representing the result of the task is returned immediately.
Node上で実行されるPython関数のこと。(定義)
A task represents the execution of a remote function on a stateless worker. When a remote function is invoked, a future representing the result of the task is returned immediately.
Node上で実行されるPython関数のこと。Taskと同じ。ステートレス。と同じ。ステートレス。
Remote object
- Objects are immutable, and can be accessed from anywhere on the cluster, as they are stored in the cluster shared memory.
- 不変なので、値を更新するとObject referenceが新しく作られる。
num_list = [ 23, 42, 93 ]
obj_ref = ray.put(num_list)
ray.get(obj_ref)
- メモリがどのようにallocateされるかはオブジェクトによって左右される。
- 以下の図のように小さいオブジェクトであれば、Worker(Processみたいなもの?)のin-process storeに保存される。
- 一方、大きなオブジェクトであれば、Node内の(Distributed) Object storeに保存される。

- Objcect storeは各ノードに1つ
ray.get()をした時のステップ
- Resolving a large object. The object x is initially created on Node 2, e.g., because the task that returned the value ran on that node. This shows the steps when the owner (the caller of the task) calls ray.get:
-
- Lookup object’s locations at the owner.
-
- Select a location and send a request for a copy of the object.
-
- Receive the object.
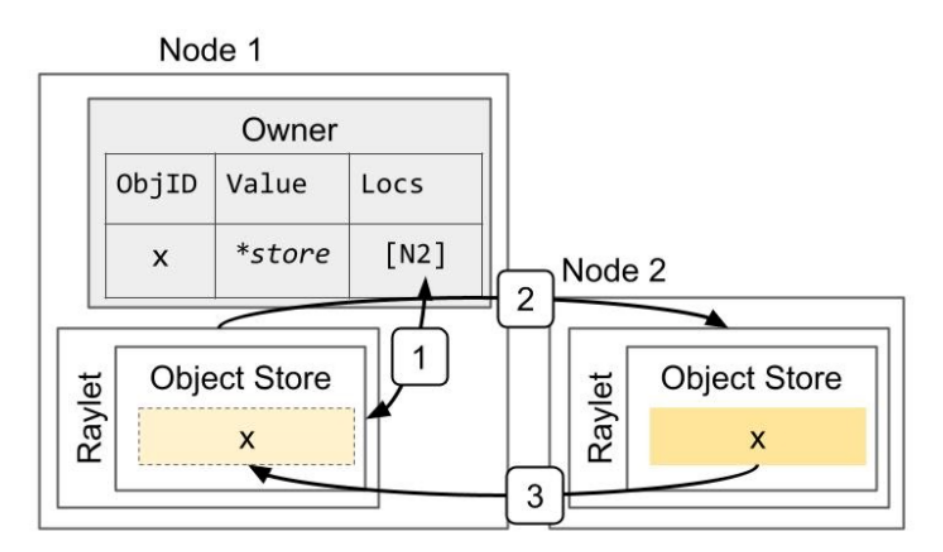
- Receive the object.
Task(定義)
A task represents the execution of a remote function on a stateless worker. When a remote function is invoked, a future representing the result of the task is returned immediately.
Node上で実行されるPython関数のこと。Taskと同じ。ステートレス。
Threaded Actors、AsyncIO for Actors(定義)
Within a single actor process, it is possible to execute concurrent threads.
Ray offers two types of concurrency within an actor:
- async execution (AsyncIO for Actors)
- threading (Threaded Actors)
Keep in mind that the Python’s Global Interpreter Lock (GIL) will only allow one thread of Python code running at once.
→ 下記の引用の通り、Pythonでは単一スレッドしか稼働しない。
そもそもPythonという言語には複数の実装が存在します。最も広く使われているのがC言語で実装されたCPythonで、おそらくPythonの言語特性が説明されているときには、暗黙的にこのCPythonを指しているはずです。
(中略)
では本題に戻ってGILの説明に入りますが、大まかに言うと「複数スレッド下でもロックを持つ単一スレッドでしかバイトコードが実行できず、その他のスレッドは待機状態になる」ことです。ロックは定間隔で開放され、新たにロックを獲得した別スレッドがプログラムを実行します。
This means if you are just parallelizing Python code, you won’t get true parallelism. If you calls Numpy, Cython, Tensorflow, or PyTorch code, these libraries will release the GIL when calling into C/C++ functions.
→ 下記の引用の通り、Pythonの内部機能を使用しない処理 i.e. Numpy, Cython, Tensorflow, or PyTorch を利用する場合は、GILをリリースしてCやC++の関数を呼ぶので並列化できるということ。
「それじゃあPythonでマルチスレッドにしても意味がないのでは」と思えるかもしれないが、石本氏は「Pythonの内部機能を使用しない処理ならGILを保持する必要がない」と言う。例えばPythonの演算にはGILが必要になるが、print()やファイルの入出力などOSやアプリケーションに関連する処理ならGILは必要ない。そのためPythonの演算とほかの処理は並行にできる。
Neither the Threaded Actors nor AsyncIO for Actors model will allow you to bypass the GIL.
→ ここが重要。Threaded Actors、AsyncIO for ActorsどちらでもGILを避けることはできない。
参考
-
Ray Core Tutorialの動画 ★わかりやすいのでおススメ
https://www.anyscale.com/events/2021/06/24/ray-core-tutorial -
Ray Tutorial GitHub
- Rayに関するBerkeleyの論文 ★情報量ナンバーワン!