BERTのText Embeddingのトークン数とCPU環境での推論速度の関係を実際に実行して調べてみました。
結果のノートブックは以下のリンクです。
https://github.com/tkeshun/bert-token-time-test/blob/main/BERT_TOKEN_time.ipynb
以下に手順を示します。
事前準備
# ライブラリのインストール
pip install torch transformers
# 実行環境の情報の確認
!cat /etc/os-release
-
OS

-
CPU

-
メモリ
使用可能メモリは大体13GBくらいでした
Text Embeddingの実行
だんだん文章の量を増やしながら、推論していきます。
import torch
import time
from transformers import BertTokenizer, BertModel
# 日本語BERTモデルのトークナイザーとモデルの読み込み
tokenizer = BertTokenizer.from_pretrained('cl-tohoku/bert-base-japanese')
model = BertModel.from_pretrained('cl-tohoku/bert-base-japanese')
# 初期の短い日本語テキスト例文
initial_text = "これはサンプルの文章です。"
max_tokens = 512 # BERTのトークン上限数
# トークン数を増やすための例文リスト
example_texts = []
current_text = initial_text
# 512トークンに達するまで例文を生成
while True:
# トークン化とトークン数の計算
inputs = tokenizer(current_text, return_tensors='pt', truncation=False, padding=False)
token_count = inputs['input_ids'].size(1)
# 現在の例文とトークン数を表示
print(f"Text: {current_text[:50]}...") # 長い場合は冒頭部分のみ表示
print(f"Number of tokens: {token_count}")
# トークン数上限に達したら終了
if token_count >= max_tokens:
example_texts.append(current_text) # 最後の例文もリストに追加
break
# 例文をリストに追加して、テキストをさらに長くする
example_texts.append(current_text)
current_text += " " + initial_text # 繰り返してテキストを追加
print(f"\nGenerated {len(example_texts)} example texts with increasing token counts.\n")
# CPUでのエンベディング計算用にモデルを設定
device = torch.device('cpu')
model.to(device)
model.eval()
# 各例文についてエンベディングを計算し、推論時間を測定
for idx, text in enumerate(example_texts):
# トークン化してテンソルに変換
inputs = tokenizer(text, return_tensors='pt', padding=True, truncation=True).to(device)
# 推論時間の計測開始
start_time = time.time()
# エンベディング計算
with torch.no_grad():
outputs = model(**inputs)
cls_embedding = outputs.last_hidden_state[:, 0, :] # [CLS]トークンのエンベディングを取得
# 推論時間の計測終了
end_time = time.time()
inference_time = end_time - start_time
# 結果の表示
print(f"Example {idx+1}: {len(inputs['input_ids'][0])} tokens, CLS Embedding Shape: {cls_embedding.shape}, Inference Time: {inference_time:.4f} seconds")
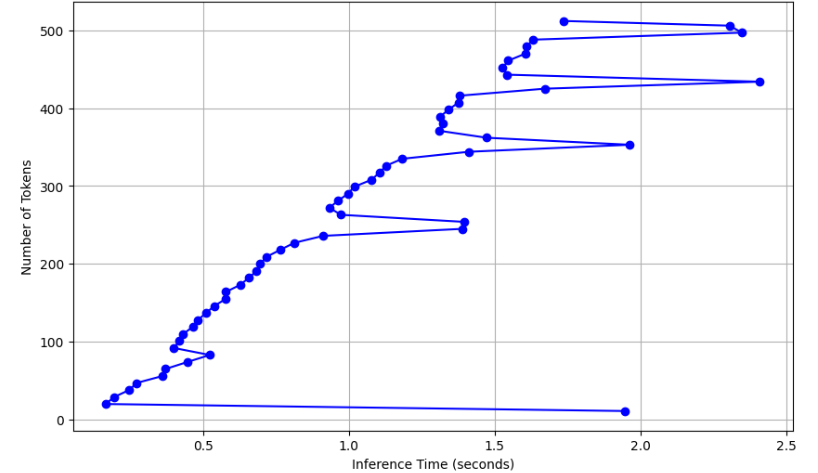
結果
最大に近くなっても、推論時間2秒ほどであり、CPUでもそれなりの処理速度でした。
GPUがないと使い物にならないのかな?と思ってたので意外な結果でした。
短い文章や推論速度がそれほど要求されないのであればCPUでの使用も選択肢に入りそうです。