近々現場でAzureで機械学習のサービスを構築する機会がありそうなので、Azureについていろいろ調べてみる事にしました。
まずはビジュアルに機械学習モデルを構築できるAzure Machine Learning Studioを試してみました。
Azure Machine Learning Studioとは
次のような点が特徴となります。
- ドラッグ&ドロップで機械学習のモデルが構築できる。
- 構築したモデルをWEB APIから呼び出す事ができる。
- 多数の組み込みの統計機能と関数が用意されている。
Azure Machine Learning StudioはGUIでコーディングレスで機械学習のモデルを構築できるのが売りですが、本格的なプロダクトを開発するために利用されることはあまり想定されていません。
クイックにPoCを行ったり小規模の予測モデルを気軽に作って社内でどんどん共有したり、といったライトなニーズに答えるために用意されているサービスという位置づけでしょう。
本格的なプロダクトレベルの機械学習モデルの開発については、別の「Azure Machine Learning service」というサービスが用意されています。こちらは次の機会に試してみたいと思います。
Microsoft Learn
今回、Microsoft社が用意している以下のMicrosoft Learnに沿ってチュートリアルを進めました。
[Microsoft Azure Machine Learning Studio を使用して Machine Learning の実験を公開する] (https://docs.microsoft.com/ja-jp/learn/paths/publish-experiment-with-ml-studio/)
AzureのMicrosoft Learnはかなり充実していて、バッヂがもらえたりAzureレベルが上がったりと、やる気が続くようよく考えられています。Azureを勉強したいと思ったらMicrosoft Learnでラーニングパスに沿って学習を進めていくのが良いですね。
Azure Machine Learning Studioの利用
ワークスペースの作成
Azure Machine Learning Studioを利用するには、アカウントの作成が必要となります。
以下の3パターンのワークスペースが利用できます。
標準ワークスペース以外であれば無料で試す事ができます。どんなサービスかを試してみる範囲であれば課金が発生することはないでしょう。
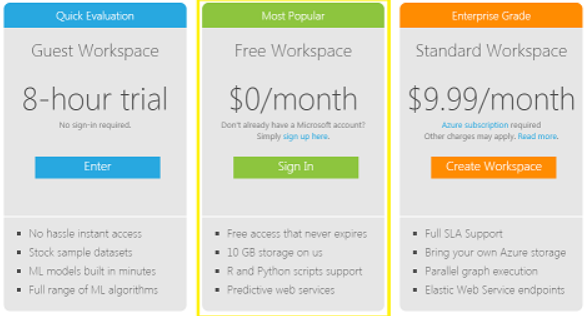
- ゲストワークスペース
- サインインせずに8時間限定で使えるようです。
- 8時間ですべて消えてしまいますが、何も気にせず使えるのが良いですね。
- 無料ワークスペース
- Microsoftのアカウントでサインインして使います。私はこのワークスペースで試してみました。
- 10GBまで無料で利用可能のようです。
- Webサービスも利用できます。
- 標準ワークスペース
- Azureサブスクリプション + 月$9.99ドルの費用がかかります。
- 自分のAzure Storageと連携させることができるようです。
- MicrosoftのSLAが設定されています。
プライシングについて
ここでプライシングについて確認してみましょう。
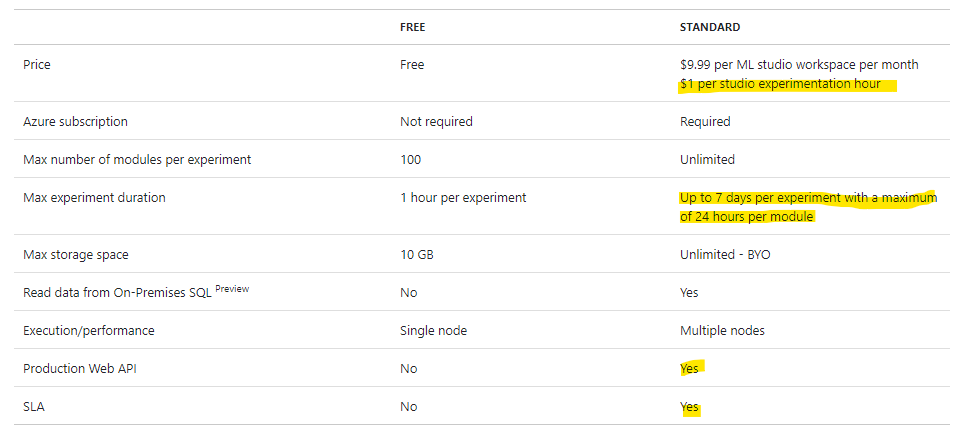
上記のWorkspaceを選択するところで、Enterprise Gradeの標準ワークスペースが$9.99/月となっており、上限$9.99で好きなだけ使えるのかと思ってしまいました。
ところがそんな美味い話ではなく、上記はあくまでワークスペースを維持するための費用で、これに追加で重量課金が発生します。
以下のPriceのページに詳しく重量課金について書かれていました。
ランタイムにかかる重量課金
[Pricing] (https://azure.microsoft.com/en-us/pricing/details/machine-learning-studio/)
さらにWEB APIを利用する場合はその利用料も発生します。
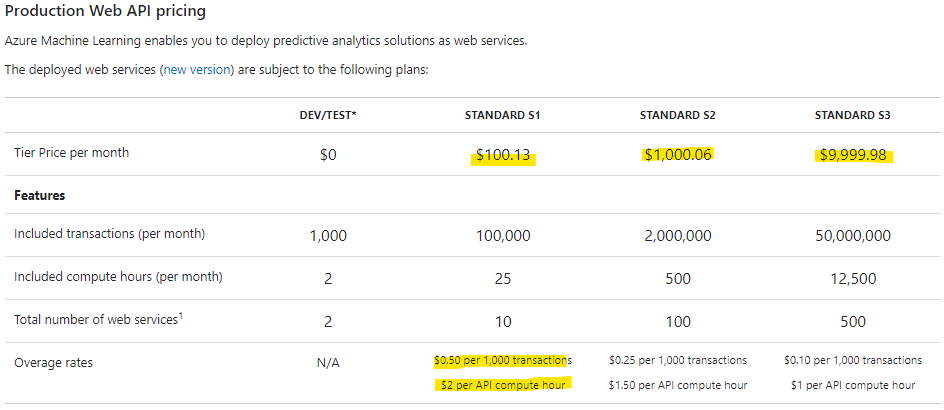
※DEV/TESTは同時接続が2に絞られるようです。
こう見ると、気軽にガンガン学習回して本番環境でWEB APIでどんどん推論させると簡単に月数万円の費用となりそうです。
下手な使い方をすると10万円も超えて来るかもしれません。
24 hours per moduleという制限も長時間の学習が想定される場合は厳しい気がします。
簡単に機械学習を実装してWEB API化できる反面、従量課金は割高な印象を受けました。
あまり時間のかかる学習では利用せず、小規模なデータセットを短時間で動かす用途に絞った方が良さそうです。
実験(Experiment)の作成
プライシングを見て興味が薄れてしまった方も多いかもしれませんが、実装を見ていきたいと思います。
Azureでは学習と推論を合わせて実験(Experiment)と呼んでいるようです。ちょっと違和感ありますね。
学習を「Training Experiment」、推論を「Predictive experiment」と呼び分けています。
データのセットアップ
ラーニングパスで用意されているcsvデータをセットアップしました。
768行、5列のシンプルなデータセットで、ビルのエネルギー効率に関するデータとなります。
Azure Machine Learning StudioでそのCSVファイルをアップロードすると、My Datasetsに表示されます。
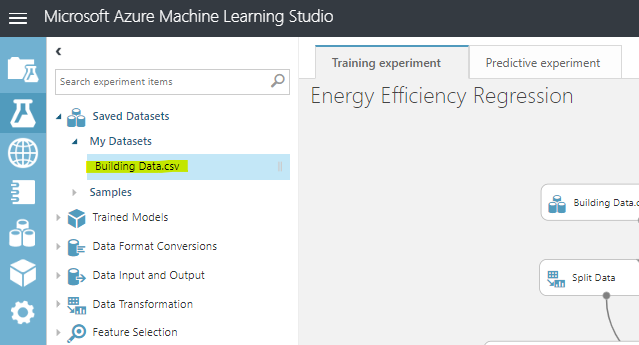
ビジュアルエリアへのパーツ配置
続いて、機械学習に必要なパーツを選択してビジュアルエリアへ配置していきます。
左のツリーをダブルクリックするか、ツリーからビジュアルエリアへドラッグドロップすることでパーツを配置していくことができます。
このコードレスでビジュアルに機械学習モデルを構築していけるところが Azure Machine Learning Studio の最大の売りとなります。
以下の例では、データセット(Building Data.csv)、データ分割(Split Data)、モデル(Decision Forest Regression)、モデルの学習(Train Model)、モデルのスコアリング(Score Model)、モデルの評価(Evaluate Model)のパーツを左側のツリーから選んでビジュアルエリアへ配置しました。
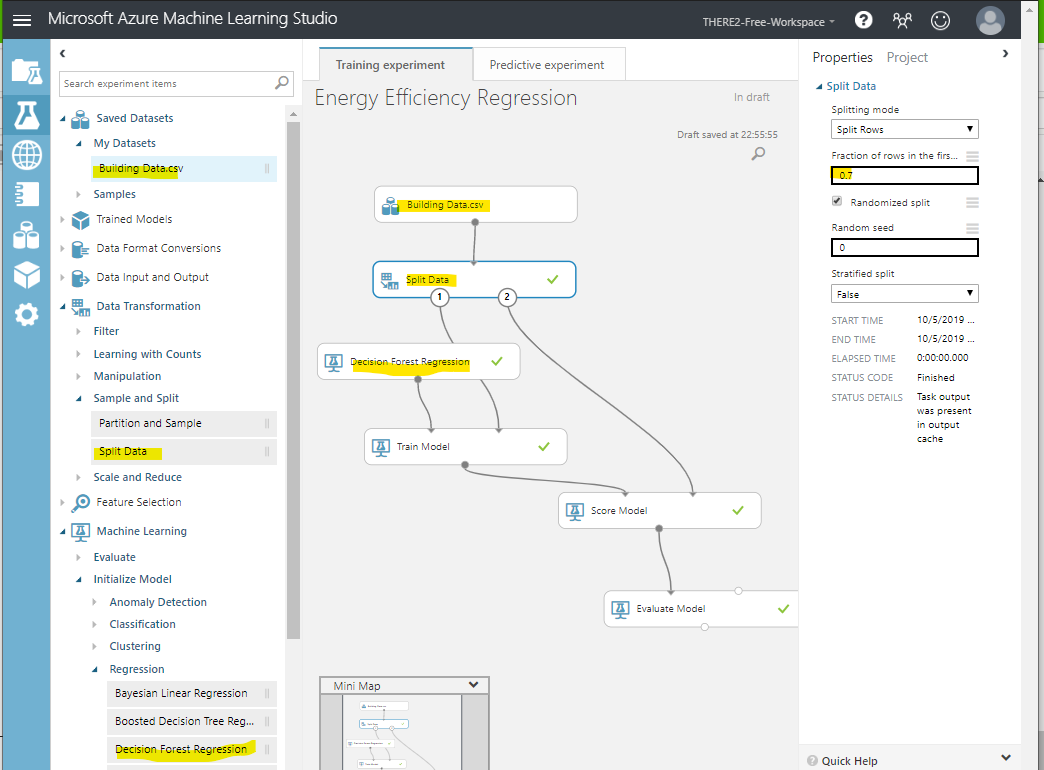
また、個々のパーツをクリックすると、右側のエリアで個々のパーツで必要なパラメータを設定できます。
例えばSplit Dataだと分割割合(7:3など)、ランダム分割するか、ランダムシードの設定、Stratifyするかなどの設定ができます。
Decision Forest RegressionではTreeの数、Max Depthなどのハイパーパラメータを設定できます。
そして各パーツのインプットとアウトプットを繋いでやればモデルが出来上がりとなります。
それぞれのパーツはPandasやNumpy、Scikit-learn等でよくやる処理なので、それらを使いこんでいる人であれば利用は難しくないでしょう。
逆に前処理がモデルに与える影響や、モデルの特徴、ハイパーパラメータの意味を理解していないとGUIになっても手も足も出ないように思います。
Pandas/Numpy/Scikit-learn等のコードを書かずにGUIで設定できる事で、コーディング時のタイプミス等のうっかりミスは防げる事が期待できます。
ただ、機械学習の中で一番難しく時間がかかるのは、どういった前処理やモデルのハイパーパラメータが精度に影響があるか、どう設定すれば精度が上がるのか、といった部分を事を探索していく部分で、このビジュアルツールがその探索を楽にしてくれるわけではありません。
逆にJupyterのようなツールで随時結果をデータやグラフで確認しながらEDAを進めていく、という事がビジュアルのツールだとやりにくい分、こういったツールの使いどころが限られてしまう気がしました。
学習の実行
モデルが構築できたら学習を実行します。
実行は下部のRunボタンをクリックするだけです。
学習の実行結果として学習セット、テストセットに対する精度はどうだったのか、どこかに記録が残っているのかと思いますが私は見つけられませんでした。
あんまり学習・テストの結果を見ながら特徴量エンジニアリングしたりハイパーパラメータの調整したりといった事は想定してないのかもしれません。
デフォルトのパラメータで実行して細かい調整はなし、そこそこの精度が出ればいいよ、という考えでしょうか。
WEBサービスとしてデプロイ
ここは私が一番感動したポイントです。学習済みのモデルで推論を行うためのWEBサービスとしてのデプロイが本当に簡単でした。
学習済み(実行済み)のモデルに対して、画面下部のSET UP WEB SERVICEをクリックするだけでどこからでも呼び出せるWEB APIがデプロイされます。

デプロイが完了すると以下のような画面にAPIキーが表示されます。
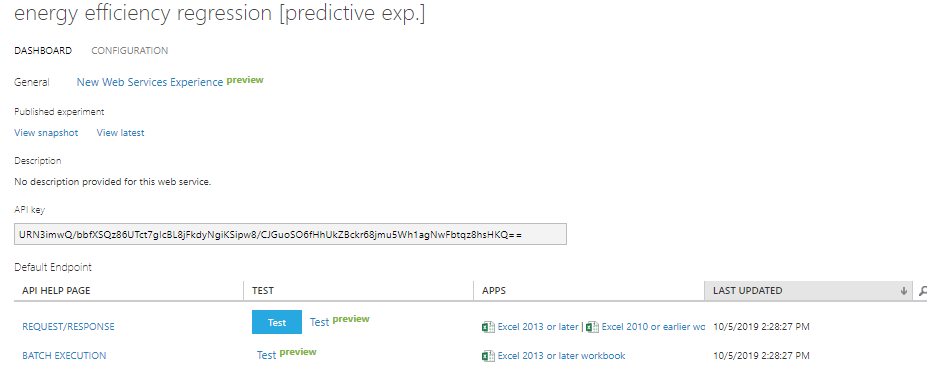
このREQUEST/RESPONSEをクリックするとAPIのURL、Requestのサンプル、Responseのサンプル、C#/Python/RでのAPI呼び出し用のソースコードのスニペットまで出力されるという親切設計でした。
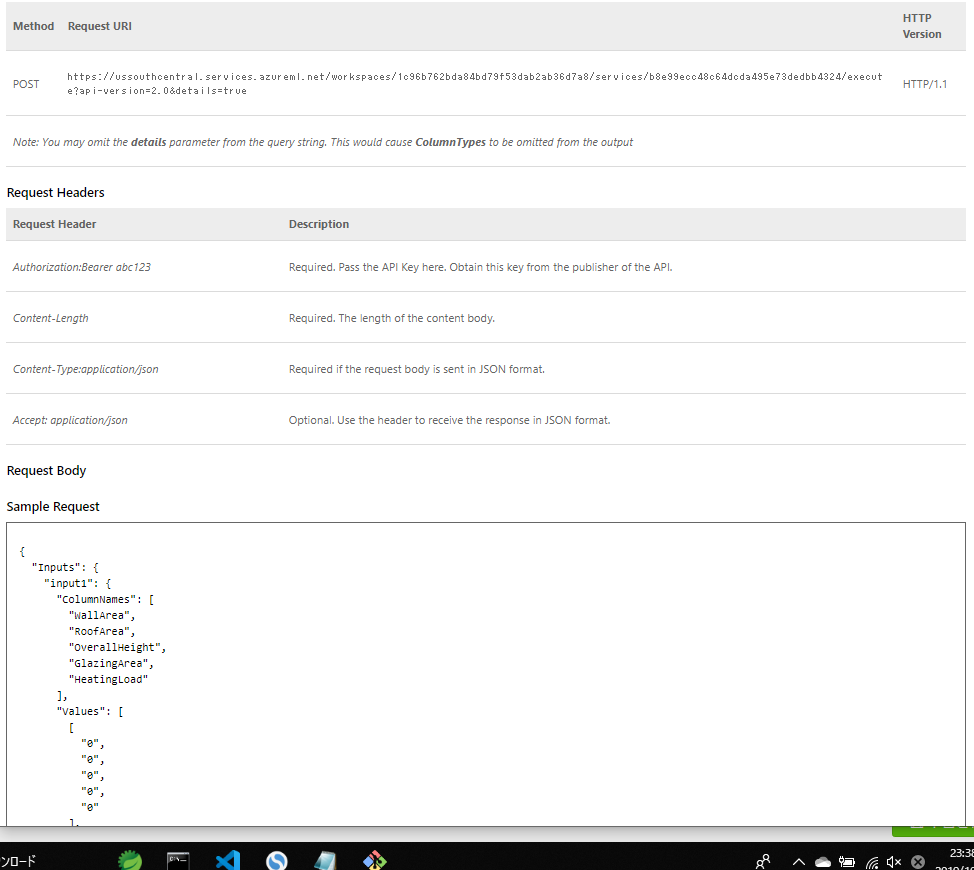
API呼び出しの認証や、負荷に応じたスケールアップ、スケールアウトなどどれぐらい本番用プロダクトとして使いものになるのかは十分に確認できていませんが、社内での利用や可用性がそこまで求められない小規模のサービス等であれば十分実用的でしょう。
まとめ
一通り実装してみての印象は以下の通りです。
深く細部まで調べて書いているわけではなく、一部正しくない部分があるかもしれませんので、その点ご了承ください。
- Pandas, Numpy, Scikit-learnでよくやる処理がGUIのドロップ&ドロップでできる。
- Pandas, Numpy, Scikit-learnの処理に精通していれば習熟は早いが、それぞれの前処理の意味や各学習モデルのパラメータの意味を知っていないといくらGUIで簡単そうに見えても手も足も出ない。
- 前処理や特徴量エンジニアリング、ハイパーパラメータ探索は楽にならない
- WEB API化は恐ろしく簡単。
- 時間のかかる学習や高頻度の推論でハードに使うとかなりコスト高になりそう
少し否定的な書き方はしましたが、今後機械学習の難しい部分を隠蔽してより使いやすく簡単になっていくポテンシャルは感じました。
こういったツールからデータ分析に入っていく人が増えれば、わざわざpythonでコーディングする人はいなくなっていくのかもしれませんね。