はじめに
- 私は自動運転の認識技術について調べ始めてまだ日が浅いので間違った理解がたくさんあると思いますが指摘していただけると嬉しいです。
議論したいこと
- 自動運転でカメラなどのセンサーで収集した情報を機械学習の技術を使って処理する手法の特徴や違いについて議論したいと思います。これより後はこの処理を**「認識技術」**と呼ぶこととします。
- 認識技術には**"object detection(物体検知)","semantic segmentation","instance segmentation","panoptic segmentation"**の四種類があります(解説は後述します)。これら四つの認識技術の違いを議論して、自動運転に最も適したものはどれかを考えたいと思います。
- 本記事の議論ではこれらの技術が**「完璧に動作した未来においてどれだけ有用か」について議論したいと思います。つまり機械学習技術を議論する際にありがちな精度、速度、データセットについては完璧なものが研究されて、用意されているということを仮定して有用性を議論するということです。このような仮定を置く理由は今行っている機械学習の基礎研究が高い水準の性能を持った技術を生み出せたとして、「本当に役に立つものになるか?」**ということに疑問を持ったためです。
結論
- 忙しい人向け
- 都会の車や歩行者が行きかう場所ではobject detectionが必須、田舎道や建物内に入って運転するなどのどのような環境でも動かしたい要望があればsemantic segmentation。
- instance segmentationは自動運転ではobject detectionとほぼ一緒の性質。panoptic segmentationは最強、ただし技術的に困難。
認識技術の解説
Object detection

- 上の画像はカメラで撮影された画像にobject detectionを適用した出力です。object detectionはカメラに写っている物体をボックスで囲って、ボックス内の物体が何であるかを認識する技術です。この画像では車、人間、自転車、トラック、信号機がボックスで囲われていることが分かります。
- このような車、人間などの**「それが何であるか」ということを専門用語でsemantics(セマンティクス)と呼びます。object detectionは「どのようなsemanticsが、どの位置にあるか」をボックスを使って表現している**ということになります。
- Object detectionの技術で注目すべきことはinstance(インスタンス)を認識していることです。画像の右側に注目すると車の一つ一つがボックスで囲われています。このような**「一つ一つ分離できる物体」を専門用語でinstanceと呼びます。このようにinstanceを認識することで、前の時刻で取得された画像からintanceを追跡することができ物体を追跡することができます。つまりinstanceを認識できることは物体追跡ができる**ことを意味します。
Semantic segmentation

- 上の画像は左の画像がカメラで撮影された画像で、右がsemantic segmentationを適用した出力です。semantic segmentationは画像のピクセル一つ一つのsemanticsを認識する技術です。つまり画像全体をsematicsごとに領域分割(segmentation)していることになります。上の画像ではsematic segmentationの結果を色を塗り分けることで可視化しており、車は青色に、道路は紫色に、人間は赤色に塗られていることが分かります。
- Semantic segmentationはobject detectionと同様にsemanticsの位置を認識していますが、出力がボックスではなくピクセル単位となるのでより**「高精度の物体の位置情報を得る」**ことができます。
- Semantic segmentationはobject detectionと異なり**「instanceを認識できません」。下の画像では多数の人を認識していますがすべての人が赤色で塗りつぶされており一人一人の人間を認識していないです。前述したようにinstanceを認識できないということは物体追跡ができない**ということを意味します。
- Semantic segmentationとobject detectionの違いは道路や建物などの**「数えられない領域を認識できる」ということです。object detectionのボックスの出力で道路を認識させると画像のほとんどをボックスで囲んでしまい意味のない情報になってしまいます。しかしsemantic segmentationはどこまでの領域が道路で、歩道で、建物で、森林であるかを分割することができその境界線を明確にすることができます。このような道路、建物などの数えられない領域を専門用語で"stuff"と呼び、逆に車、人などの数えられる物体を"thing"**と呼びます。つまりsemantic segmentationは"thing"と"stuff"のsemanticsを両方認識することができ、object detectionは"thing"のsemanticsのみしか認識できないということです。
Instance segmentation & Panoptic segmentation
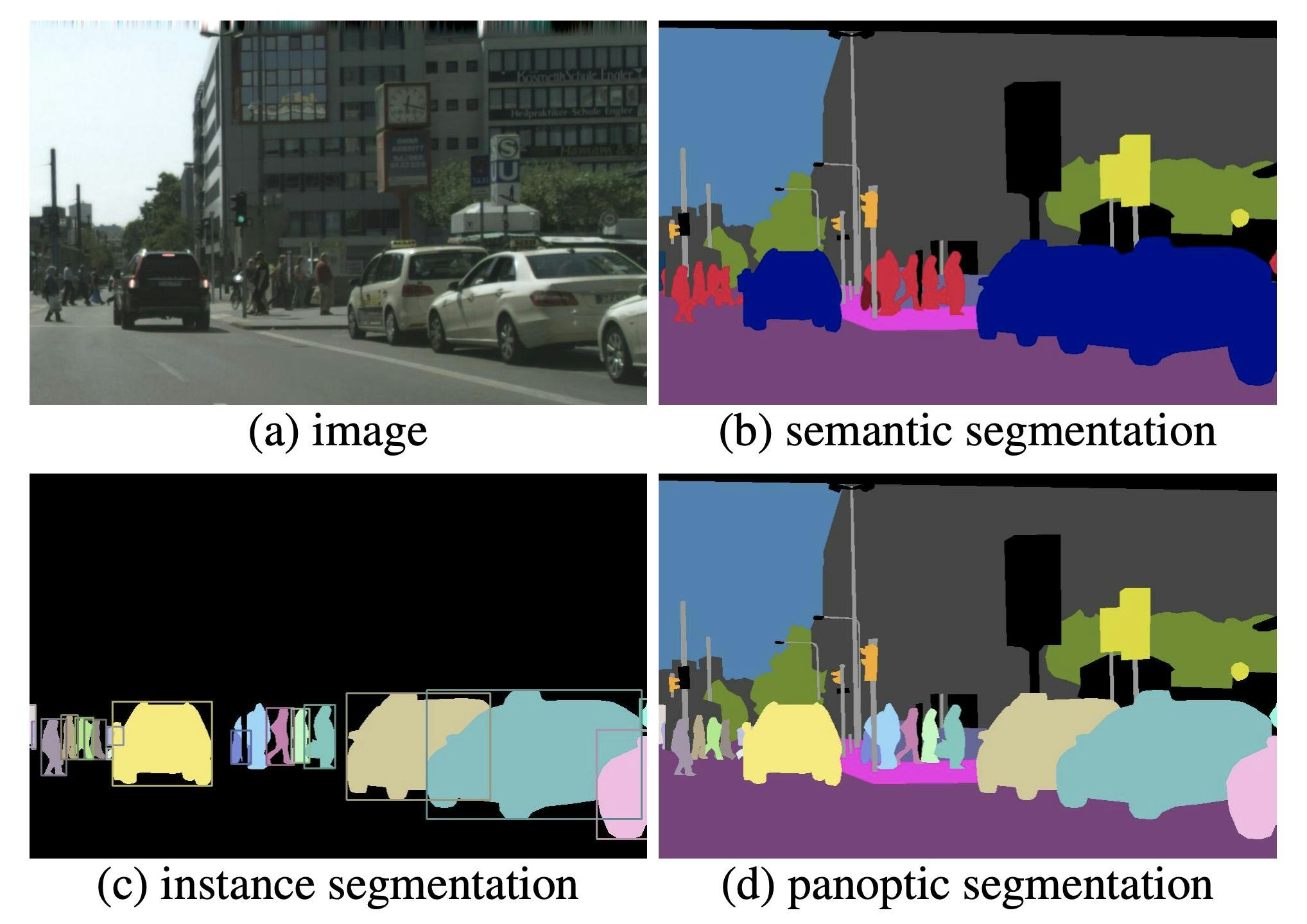
- 上の画像は左上の画像がカメラで撮影された画像であり、右上が前述のsemantic segmentationを適用した出力で、左下がinstance segmentationを適用した出力、右下がpanoptic segmentationを適用した出力です。
- 左下のinstance segmentationはobject detectionで認識された"thing"のsemanticsとinstanceがあるボックスにおいて、どの領域が物体であるかを領域分割した結果を出力しています。つまりobject detectionではボックスという境界線が明確でない荒い出力だったのが、instance segmentationではピクセル単位の領域という細かい出力ができるということです。object detection & segmentationと言えます。
- 右下のpanoptic segmentationはinstance segmentationの結果にsemantic segmentationで認識できていた"stuff"のsemanticsの領域を加えたものになります。つまり完全なsemantic & instance segmentationということになります。
認識できることできないこと
- これまで解説した四つの認識技術と**「instanceが認識できる」、「ピクセル単位の細かい領域の認識ができる(fine segmentation)」、「thing semantics」、「stuff semantics」**について表にまとめます。
| Object detection | Semantic segmentation | instance segmentation | panoptic segmentation | |
|---|---|---|---|---|
| instance | YES | NO | YES | YES |
| fine segmentation | NO | YES | YES | YES |
| thing semantics | YES | YES | YES | YES |
| stuff semantics | NO | YES | NO | YES |
どの技術が優れているか
- 上の表を見るとpanoptic segmentationが最も優れた技術であることは一目でわかります。しかしこの技術は今回議論しない精度、速度、データセットなどの実用的な問題があるため困難な技術であると言われています。
- Panoptic segmentation以外の三つの技術に関して、それぞれの技術で問題となる運転シーンを思考実験することで優位性を洗い出します。
Object detection
Stuff semanticsが認識できない
- stuff semanticsが認識できないことが問題となるような運転シーンは**「複雑なstuff領域がある環境」や「stuff領域内での高精度な車両制御が必要な場合」**です。このような環境の最たる例はあぜ道や林道です。また都会では大学構内などの様々な道路状況がある環境です。


- 上の画像の環境ではどこが道路で、どこがあぜ道で、どこが田んぼであるかを認識することがかなり重要となります。この環境は複雑な"stuff"のsemanticsに加えて道が細いためにギリギリの車両制御が求められます。そのため明確な境界線を認識する必要があります。
- 下の画像はある有名大学の構内の画像です。これもイチョウの落ち葉があるなど複雑な"stuff"のsemanticsがある環境である環境であり、どこが道であるかはルールベースの手法では認識することが困難です。
Fine segmentationができない
- "stuff"のsemanticsについては上で議論しているために、ここでは"thing"のsemanticsについて議論します。
- 細かい物体の領域を認識できるために狭い路地での車や歩行者などの回避に役に立つということが考えられますが、これは違うと考えています。なぜなら世の中の多くの物体は四角形をしているためボックスで表現するだけで障害物回避のための情報として十分であるためです。また測距センサーを使うなどのもっと単純な方法で解決することができます。
- むしろFine segmentationが無いと困難な状況は**「変形する大物体(thing)を通過する必要がある場合」**です。このような状況の最たる例がゲートの通過であると考えています。これはゲートという物体をボックスで囲ったとしても開閉の状態遷移を認識できないためです(開いてるるゲートと閉じているゲートを別に認識するれば解決すればよいが、あくまでobject detectionはsemanticsを認識する技術である)。しかしsegmentationの結果があればゲートが開いている際にゲートの領域が車両が通過する領域内にはないことを認識することができます。


- 上のようなゲートがある際に画像中央をボックスで囲ったとしても、ゲートが開いていて通過できる状態かを認識することはできません。しかしsegmentationを行うことでゲートがどの領域にあるかを認識して回避することができます。
- 測距センサーを使って目の前の領域に障害物がなくなれば進むというルールを作ればいいという反論が考えられますが下のような形のような測距センサーが使えなさそうな多様なゲートがあり、単純な制御では難しいという問題があります。
Semantic segmentation
instanceを認識できない
- instanceの認識は前述の通り物体追跡をおこなう際に重要となります。物体追跡ができれば未来予測ができます。このような未来予測が特に必要となる場面は**「自分以外の物体が多数あり、複雑な動きをする環境」**です。つまり車などの"thing"のsemanticsについてinstanceが複数存在して、なおかつそれらが互いに独立な動きをしているときです。このような環境の最たる例が混雑する交差点での車両の動きや高速道路でのレーンチェンジです。


- 上下の画像とも多数の車が存在してなおかつ直進したり曲がったりとそれぞれ独立した動きをしていることが分かります。semanticsの位置が分かっていればその領域を避けて自動運転車を制御すればよいように感じられますが、このように動的な環境では他の車が次の時間にどの位置にいるかを予測しなければ反応が間に合わないことがあります。そのためにはinstanceを認識してそれらを独立して追跡して予測する必要があります。
Instance segmentation
- Instance segmentationは"stuff"のsemanticsが認識できないため前述のobject detectionで述べたものと同じ欠点があります。
まとめ
- これまでの議論からobject detectionとsemantic segmentationはそれぞれに欠点があり、うまく動作することができない環境があることがわかりました。そのため自動運転を動作させる環境によって最適な技術を選択する必要があります。
- Object detectionは都会の交差点などの複雑な動きをする物体がたくさんある環境や、高速道路などの高速に動く物体が多数ある環境で有用です。逆にSemantic segmentationは田舎道や建物内の道など道路環境が複雑で整備されていない道やゲートなどの変形する大物体を通過する際に有用です。
- Instance segmentationはゲートなどの変形する大物体を通過することができ、Panoptic segmentationはあらゆる環境を認識することができます。
- 実際には今回議論を避けた精度、速度、データセットや実装の容易さなどの実用的な理由でinstance segmentationやpanoptic segmentationが自動運転に搭載された例は聞いたことが無く、object detectionのみやobject detection+semantic segmentationのシステムが多いです。
余談
- 現在自動運転は高級セダンに搭載するのが主流で都会とか高速道路を走らせたいというのがユーザーの要望なのでビジネス的にはobject detectionをチューナップしていくのが正しいが、自動運転の社会的な意義として公共交通機関がない田舎のお年寄りの足にするという話はそれだけでは実現できなそうという感想を持ちました。