そろそろKubernetes を触りたいと思い、技術検証をすることにしました。
触るだけでは面白くないので、FastAPI + Whisper でAPIを構築し、それをDocker化し、Kubernetes にしていこうというプロジェクトです。
ちなみに、このAPIをKubernetes で動かすのは、技術選定としては明らかなオーバーエンジニアリングで、現場でやると怒られるので注意。
目的
- Kubernetes を触ってみたい
- Docker化が実務で必要になった
- 自分の技術引き出しを増やしたい
- SREらしくコストに超気を付ける
想定フェーズ
- ローカルで動作確認
- Docker化して移植検証(← この記事ではここまで)
- Kubernetes化して、スケーリング検証
使用技術
| 項目 | 技術 |
|---|---|
| 音声認識 | Whisper (OpenAI) |
| Webフレームワーク | FastAPI |
| コンテナ | Docker |
| 開発環境 | WSL2 |
| 神の声 | ChatGPT |
構成
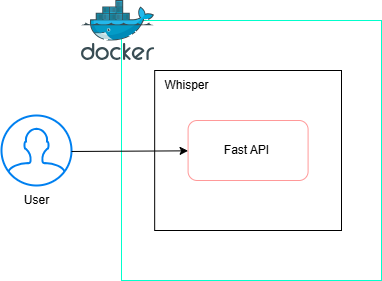
API
[音声ファイル] → FastAPI (/transcribe) → Whisper → [文字起こし結果(JSON)]
ローカル検証(FastAPI + Whisper)
こちら昔、Whisper で会議文字起こしを自作した時のコードを流用。
main.py
from fastapi import FastAPI, File, UploadFile
import whisper
import tempfile
import os
app = FastAPI()
model = whisper.load_model("base")
@app.post("/transcribe")
async def transcribe(file: UploadFile = File(...)):
with tempfile.NamedTemporaryFile(delete=False, suffix=".wav") as tmp:
tmp.write(await file.read())
tmp_path = tmp.name
result = model.transcribe(tmp_path)
os.remove(tmp_path)
return {"text": result["text"]}
インストール
VScode であれば、.venv は自動で認識してくれるはず。
python3 -m venv .venv
source .venv/bin/activate
pip install fastapi uvicorn openai-whisper python-multipart
sudo apt install ffmpeg # Whisperに必要
起動&テスト
uvicorn app.main:app --reload
→ http://localhost:8000/docs にアクセス
→ /transcribe に .mp3 or .wav をアップロードで確認!
🐳 Docker化
Dockerfile
とりあえず、最小構成でDocker化。
FROM python:3.9-slim
RUN apt-get update && apt-get install -y ffmpeg
WORKDIR /app
COPY app/ app/
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
EXPOSE 8000
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000"]
requirements.txt
fastapi
uvicorn
openai-whisper
python-multipart
docker build & run
docker build -t whisper-api .
docker run -p 8000:8000 whisper-api
詰まったエラーとそこから得た教訓
1. OSError: Input/output error(pip install中に謎のエラー)
pip install whisper したら、なんか "input/output error" とか言われて停止
原因:
WSL上で /mnt/c/...(つまりWindows側のCドライブ)で作業してた。
気づき:
WSL内での開発は「Linuxのファイルシステム内(例: ~/<自分のプロジェクト>)」でやる。
Windows領域だと、pipがファイル展開しきれず落ちやすい。特にPyTorch系はサイズでかいしツラい。
初歩的だが、完全に忘れていた。
2. RuntimeError: python-multipart が無いって怒られる
FastAPIの /transcribe 叩いたら500エラー
原因:
FastAPIで UploadFile を受け取るには、裏で python-multipart ってライブラリが必要らしい。知らんかった。
学び:
pip install python-multipart で解決。
普段開発のPythonは使わないので、知らんかったわ。
3. cloud-init がDockerビルドで邪魔をする
docker build したら、cloud-init==24.4 で「Pythonのバージョンが合いません」エラー。
原因:
pip freeze > requirements.txt で、仮想環境に入ってた cloud-init も一緒に入ってしまった。
教訓:
pip freeze は便利だけど、Dockerビルド前には requirements.txt を ちゃんと見直す こと!
そもそも必要最低限だけでいい。実務でやったら怒られる。
現時点の成果と今後
完了したこと
- Whisper + FastAPIによる文字起こしAPI構築
- ローカル確認 → Dockerコンテナ化
- 必要な依存・構成管理が明確化
🔜 次にやること
- Kubernetes YAML化(Deployment, Service)
- HPAによる自動スケーリング検証
- cert-managerでのHTTPS化
- GitHub公開 + ポートフォリオ整備
まとめ
この検証を通して、音声認識APIの構築だけでなく、
- Docker化は意外と理解しやすい
- しかしDockerビルド時の依存トラブルある
実務でも、改善を考えるきっかけになりそうな学びがあったと思う。
あとは、自分が実務で気づくかですかね。
次回ついにKubernetes化!!!