この記事は2014/07に別ブログに書いたものをQiitaに転記するものです。情報が古い可能性がありますのでご了承ください。
Kafkaについての概要はこのページが確認しやすい
http://d.hatena.ne.jp/kimutansk/20130520
http://www.slideshare.net/yanaoki/kafka-10346557
概要
複数データソースからデータを受け取り、後続にメッセージとして流すリアルタイム分散メッセージ処理用のキューシステム
採用実績
開発元
キーワードランキング
PV/インプレッション
google analystic
アクセス解析
PV/UU/検索キーワードのリアルタイム集計
キャンペーンのソーシャルメディア反応
CTR(インターネット広告が表示された回数のうち、クリックされた数の割合を表す)
facebookのIN/OUTアクセスログ解析
Twitter analystic
Twitterにてどれだけそのページが呟かれているか
Twitterリンクボタンがどれだけ押されたか
構成図
・Apache Kafkaの内部
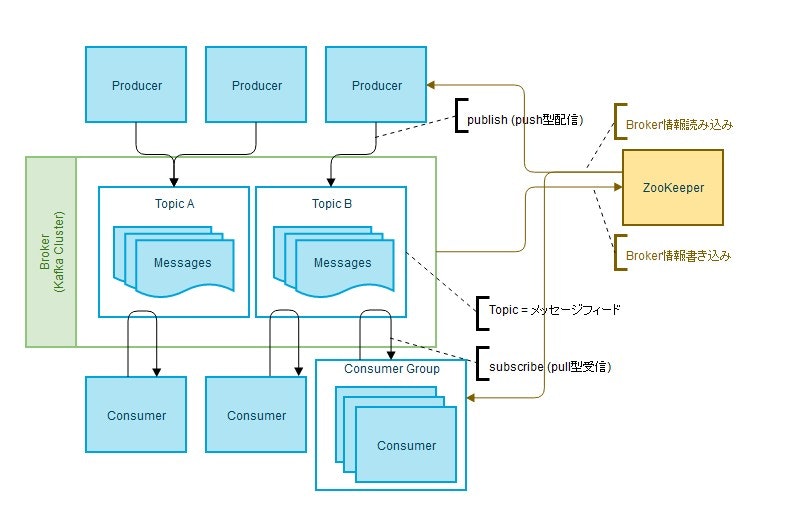
・パーティション - レプリケーション構成(サンプル)
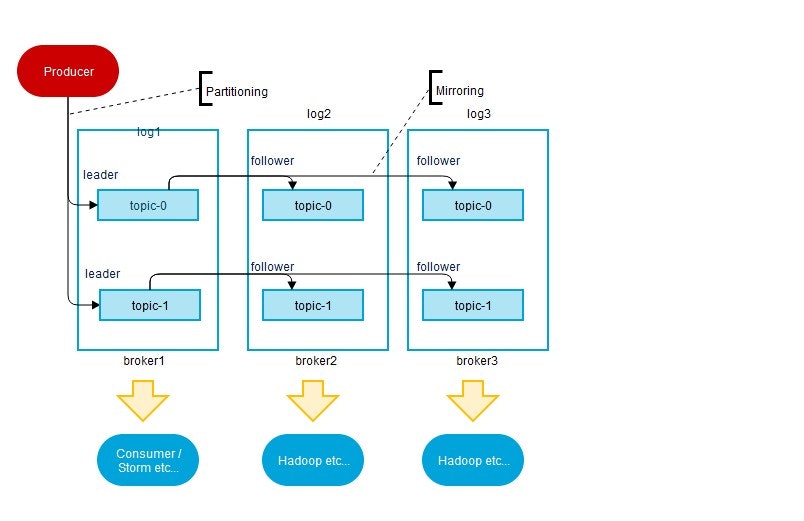
※A Kafka cluster with 3 brokers. 1 topic and 2 partitions,each with 2 replicas.
インストール手順
Zookeeper(-v 3.4.6)のインストール
http://mirror.reverse.net/pub/apache/zookeeper/
バイナリデータをローカルにダウンロードし解凍する。
Kafka(-v 0.8.1.1)のインストール
http://kafka.apache.org/downloads.html
バイナリデータをローカルにダウンロードし解凍する。
動作確認(シングル構成)
ZooKeeperを起動 -> port:2181
cd /home/centos/Downloads/zookeeper-3.4.6
bin/zkServer.sh start conf/zoo.cfg
JMX enabled by default
Using config: conf/zoo.cfg
Starting zookeeper ... STARTED
Kafkaを起動 -> port:9092
cd /home/centos/Downloads/kafka_2.10-0.8.1.1
bin/kafka-server-start.sh config/server.properties
[2014-07-07 01:19:18,168] INFO [Socket Server on Broker 0], Started (kafka.network.SocketServer)
[2014-07-07 01:19:18,283] INFO Will not load MX4J, mx4j-tools.jar is not in the classpath (kafka.utils.Mx4jLoader$)
[2014-07-07 01:19:18,316] INFO 0 successfully elected as leader (kafka.server.ZookeeperLeaderElector)
[2014-07-07 01:19:18,629] INFO Registered broker 0 at path /brokers/ids/0 with address localhost:9092. (kafka.utils.ZkUtils$)
[2014-07-07 01:19:18,631] INFO New leader is 0 (kafka.server.ZookeeperLeaderElector$LeaderChangeListener)
[2014-07-07 01:19:18,652] INFO [Kafka Server 0], started (kafka.server.KafkaServer)
[2014-07-07 01:19:18,851] INFO [ReplicaFetcherManager on broker 0] Removed fetcher for partitions [my-replicated-topic,0],[test,0] (kafka.server.ReplicaFetcherManager)
[2014-07-07 01:19:18,869] INFO Truncating log my-replicated-topic-0 to offset 5. (kafka.log.Log)
[2014-07-07 01:19:18,871] INFO Truncating log test-0 to offset 3. (kafka.log.Log)
[2014-07-07 01:19:18,895] INFO [ReplicaFetcherManager on broker 0] Added fetcher for partitions ArrayBuffer() (kafka.server.ReplicaFetcherManager)
[2014-07-07 01:19:18,936] INFO [ReplicaFetcherManager on broker 0] Removed fetcher for partitions [my-replicated-topic,0],[test,0] (kafka.server.ReplicaFetcherManager)
トピックを作成(※ここでは"test"トピックを作成する)
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
トピックをリストで確認
bin/kafka-topics.sh --list --zookeeper localhost:2181
test
producerにメッセージを発信させる
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
This is a message
This is another message
consumerを追加
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
This is a message
This is another message
動作確認(クラスタ構成)
サーバープロパティを3つ用意(config/server.propertiesをコピー)
broker.id = 1
ポート= 9092
log.dir = /log/kafka1
broker.id = 2
ポート= 9093
log.dir = /log/kafka2
broker.id = 3
ポート= 9094
log.dir = /log/kafka3
サーバーを起動する
bin/kafka-server-start.sh config/server-1.properties
[2014-07-07 00:33:26,348] INFO Awaiting socket connections on 0.0.0.0:9092. (kafka.network.Acceptor)
[2014-07-07 00:33:26,354] INFO [Socket Server on Broker 1], Started (kafka.network.SocketServer)
[2014-07-07 00:33:26,451] INFO Will not load MX4J, mx4j-tools.jar is not in the classpath (kafka.utils.Mx4jLoader$)
[2014-07-07 00:33:26,472] INFO 1 successfully elected as leader (kafka.server.ZookeeperLeaderElector) // <- broker.id=1がリーダーになった
[2014-07-07 00:33:26,801] INFO Registered broker 1 at path /brokers/ids/1 with address localhost:9092. (kafka.utils.ZkUtils$)
[2014-07-07 00:33:26,818] INFO [Kafka Server 1], started (kafka.server.KafkaServer)
[2014-07-07 00:33:26,822] INFO New leader is 1 (kafka.server.ZookeeperLeaderElector$LeaderChangeListener)
[2014-07-07 00:33:26,997] INFO [ReplicaFetcherManager on broker 1] Removed fetcher for partitions [my-replicated-topic,0] (kafka.server.ReplicaFetcherManager)
[2014-07-07 00:33:27,013] INFO Truncating log my-replicated-topic-0 to offset 8. (kafka.log.Log)
[2014-07-07 00:33:27,033] INFO [ReplicaFetcherManager on broker 1] Added fetcher for partitions ArrayBuffer() (kafka.server.ReplicaFetcherManager)
[2014-07-07 00:33:27,064] INFO [ReplicaFetcherManager on broker 1] Removed fetcher for partitions [my-replicated-topic,0] (kafka.server.ReplicaFetcherManager)
[2014-07-07 00:33:29,529] INFO Partition [my-replicated-topic,0] on broker 1: Expanding ISR for partition [my-replicated-topic,0] from 1 to 1,2 (kafka.cluster.Partition)
bin/kafka-server-start.sh config/server-2.properties
[2014-07-07 00:33:28,643] INFO [Socket Server on Broker 2], Started (kafka.network.SocketServer)
[2014-07-07 00:33:28,733] INFO Will not load MX4J, mx4j-tools.jar is not in the classpath (kafka.utils.Mx4jLoader$)
[2014-07-07 00:33:28,779] INFO conflict in /controller data: {"version":1,"brokerid":2,"timestamp":"1404718408740"} stored data: {"version":1,"brokerid":1,"timestamp":"1404718406460"} (kafka.utils.ZkUtils$)
[2014-07-07 00:33:28,904] INFO Registered broker 2 at path /brokers/ids/2 with address localhost:9093. (kafka.utils.ZkUtils$)
[2014-07-07 00:33:28,991] INFO [Kafka Server 2], started (kafka.server.KafkaServer)
[2014-07-07 00:33:29,416] INFO [ReplicaFetcherManager on broker 2] Removed fetcher for partitions [my-replicated-topic,0] (kafka.server.ReplicaFetcherManager)
[2014-07-07 00:33:29,420] INFO Truncating log my-replicated-topic-0 to offset 8. (kafka.log.Log)
[2014-07-07 00:33:29,471] INFO [ReplicaFetcherManager on broker 2] Added fetcher for partitions ArrayBuffer([[my-replicated-topic,0], initOffset 8 to broker id:1,host:localhost,port:9092] ) (kafka.server.ReplicaFetcherManager)
bin/kafka-server-start.sh config/server-3.properties
[2014-07-07 00:33:30,433] INFO Awaiting socket connections on 0.0.0.0:9094. (kafka.network.Acceptor)
[2014-07-07 00:33:30,437] INFO [Socket Server on Broker 3], Started (kafka.network.SocketServer)
[2014-07-07 00:33:30,530] INFO Will not load MX4J, mx4j-tools.jar is not in the classpath (kafka.utils.Mx4jLoader$)
[2014-07-07 00:33:30,560] INFO conflict in /controller data: {"version":1,"brokerid":3,"timestamp":"1404718410540"} stored data: {"version":1,"brokerid":1,"timestamp":"1404718406460"} (kafka.utils.ZkUtils$)
[2014-07-07 00:33:30,631] INFO Registered broker 3 at path /brokers/ids/3 with address localhost:9094. (kafka.utils.ZkUtils$)
[2014-07-07 00:33:30,652] INFO [Kafka Server 3], started (kafka.server.KafkaServer)
トピックを作成する
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 2 --topic my-replicated-topic
ブローカーの状態を確認する
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
Topic: my-replicated-topi Partition: 0 Leader: 1 Replicas: 2,3,1Isr: 1,2,3
Topic: my-replicated-topi Partition: 1 Leader: 1 Replicas: 3,1,2Isr: 1,2,3
クラスタのリーダーを落としてみる
上記状態ではbroker.id=2がリーダーとなっているので、そのプロセスを落とす。
^C
[2014-07-07 01:29:46,791] INFO Closing socket connection to /127.0.0.1. (kafka.network.Processor)
[2014-07-07 01:29:46,810] INFO 3 successfully elected as leader (kafka.server.ZookeeperLeaderElector) // -> broker.id=3がリーダーに選出
[2014-07-07 01:29:47,244] INFO New leader is 3
Javaクライアントの作成
Java - Kafkaを用いて、非同期なタスクキューを作成した。
Producer : 毎秒毎にをtask投げるようにする
Consumer : Producerから受けたtaskを処理する。この時、処理にかかる時間は2秒とする。
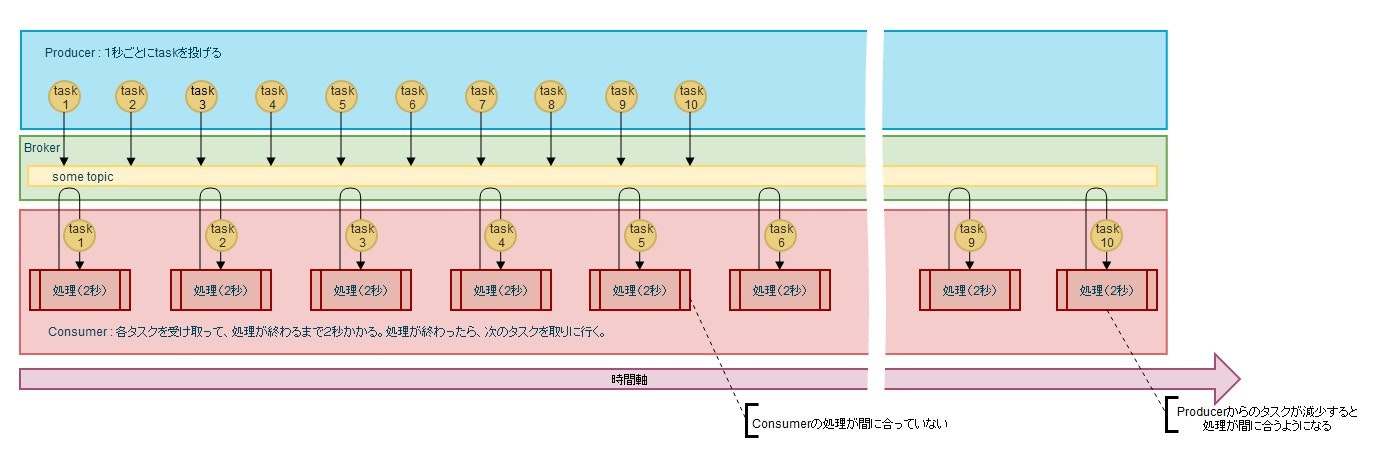
Producerが投げるtaskがConsumerの処理能力を超えた時には、Kafkaがタスクキューとなる。
Consumerの処理能力がProducerが投げるタスクの量をこなせると、処理が間に合うようになる。
このようなProducerとConsumerの挙動をするJavaクライアントを作成した。
https://github.com/n01boy/kafka-client-sample
実行結果
Tue Jul 08 01:09:07 PDT 2014 : task no 1. send from producer
Tue Jul 08 01:09:07 PDT 2014 : message received... : task no 1. 192.168.2.209 Thread : 0
Tue Jul 08 01:09:08 PDT 2014 : task no 2. send from producer
Tue Jul 08 01:09:09 PDT 2014 : task no 3. send from producer
Tue Jul 08 01:09:09 PDT 2014 : message received... : task no 2. 192.168.2.166 Thread : 0
Tue Jul 08 01:09:10 PDT 2014 : task no 4. send from producer
Tue Jul 08 01:09:11 PDT 2014 : message received... : task no 3. 192.168.2.72 Thread : 0
Tue Jul 08 01:09:11 PDT 2014 : task no 5. send from producer
Tue Jul 08 01:09:12 PDT 2014 : task no 6. send from producer
Tue Jul 08 01:09:13 PDT 2014 : message received... : task no 4. 192.168.2.102 Thread : 0
Tue Jul 08 01:09:13 PDT 2014 : task no 7. send from producer
Tue Jul 08 01:09:14 PDT 2014 : task no 8. send from producer
Tue Jul 08 01:09:15 PDT 2014 : message received... : task no 5. 192.168.2.59 Thread : 0
Tue Jul 08 01:09:15 PDT 2014 : task no 9. send from producer
Tue Jul 08 01:09:16 PDT 2014 : task no 10. send from producer
Tue Jul 08 01:09:17 PDT 2014 : message received... : task no 6. 192.168.2.213 Thread : 0
Tue Jul 08 01:09:19 PDT 2014 : message received... : task no 7. 192.168.2.29 Thread : 0
Tue Jul 08 01:09:21 PDT 2014 : message received... : task no 8. 192.168.2.27 Thread : 0
Tue Jul 08 01:09:25 PDT 2014 : message received... : task no 9. 192.168.2.216 Thread : 0
Tue Jul 08 01:09:23 PDT 2014 : message received... : task no 10. 192.168.2.146 Thread : 0
finish!
確実性・スループット向上策
Producerの同期モードか非同期モード
・同期モードだとレプリケーションが多いと遅くなる
ProducerからBrokerにwriteを始めると、log1,log2,log3に書き込みを行い、それが終了することを通知されるまで処理を待つ。
そのためレプリケーションが多い構成では同期モードが遅くなる。
ベンチマークによると3台構成で同期モードは非同期モードに比べるとスループットが6割くらいまで減少する。
非同期モードだとデータ送信の確実性が下がる
非同期モードであると、 Producerはデータを一方的に送るだけ。データの保存に失敗したときはProducerは気づけない。
Brokerの数
トピック数・パーティションが多いとき、ランダムアクセスになりがちなる。
性能を向上させたいときは、ランダムアクセスになりにくいよう、トピック、クラスタを複数ノードに分けるようにする。
Consumerの数
Consumerの数はBrokerの数と同じかそれ以上となるようにする。
Consumerの数を多くするとその分、直線比例的にスループットが向上するので、
producerが送信するメッセージよりconsumerのスループットの量が多くなるよう設定する。
ConsumerGroupの数
同一ConsumerGroup内で複数Consumerを立ち上げると、分散処理が出来るようになる。
複数ノードに跨ったkafkaクラスタを構成した場合
Aggregate Brokerを用いると、複数のサーバーにあるデータを一つのものとしてみることが出来、ネットワーク効率も上がる。
この時、ファイルサイズが大きくなるのでHDD容量には注意が必要でる。
しかしながら、下図のような構成ではBrokerが持つファイルサイズの合計値と同じだけ、Aggregate Brokerもファイルサイズを持つようになるので、
データが一か所にあるように見せる必要がないときは、この構成は必要ない
レコード数が増えたとき
レコード数が増えてファイルサイズが大きくなったとしても、シーケンシャルwrittenのため、
理論的には初めの100MBを記述するときも、1TB書いた後の100MBを書くのも同じスループットで記述することが出来る。
処理速度はO(1)である。
flush動作のタイミング
Brokerが受信したメッセージは一定数および、一定期間毎にファイルに書き出しを行いメモリから削除する。
これはLinuxのI/O管理処理を介して実行している。
この期間を短くするとメッセージの保存の確実性は上がるが、全体的なスループットは下がる傾向にある。
データ量が多い環境では、1日あれば破棄するようにする等の対策が必要。
レコードサイズの大きさによる影響
1レコード(1メッセージ)のサイズ数が大きくなるにつれて、受け入れられるレコードの数は下がる(下図)
しかしながら、レコード数×サイズ数では、1レコードのサイズ数が大きいほうが全体的に保持できるログ容量は大きい
これは1レコードを入れる度に、ロックやCPUの動きが大きいことによる。
まとめると
・Producerの増減は、topicの増減に比例する。
・ConsumerGroupの増減は、topicの増減に比例する。
・ConsumerGroup内のConsumer数は、Consumer側で行う処理がProducerが配信するメッセージの量を上回るようにする。
・Brokerの数はtopicの数やパーティションが増減したときに調整する。
※Zookeeperの使い方も書いたけど、あまり詳しく運用しているわけではないので削除しました。