TD;LD
・SEO対策をちゃんとせずにSPA化に踏み切った直後、Google検索流入が120万人/月もいたのが60万/月まで下がりました。
GoogleAnalyticsで毎週5〜10%ずつユーザーが減っていく恐怖がありつつ、
会社自体がバタバタしていたので対策が後手に回り3ヶ月放置してしまいました。
その間、全くなにもできなかったわけではなく、WEBフレームワーク(Django)が吐き出すHTMLで対策していたのですが、SEO評価がどんどん下がっていくので本腰入れてDynamicRenderingを入れることにしました。
・弊社サービス全てで使えるようにしたので、今後はSEOを心配することが減りそうです。
特に弊社サービスは画像を多く使い、Twitterでシェアしてもらうことも多いのでOGPも必須です。
開発背景
弊社ではDjango + jQueryを用いた開発を数年続けていましたが、
ユーザー体験の向上を行うために2018年夏頃から徐々にVuejsを使った開発を行い、部分適用という形でページごとにjQueryを使う代わりにVuejsに書き換えるということをしてきました。
ある程度慣れてきたこともあり、APIも揃ってきたので2019年7月にフルでSPA化することにしました。
とはいえ、たくさんの人に弊社サービスを知ってもらいたいという想いのもと、SEO対策やOGP対応は必須課題でした。
開発はNuxtを使わず、vue-cliで作っていたので、SSR(ServerSideRendering)はできません。
コードに変更を加えず、ラップする形でSEO対策をしたいと思ったときにDynamicRenderingが候補に上がりました。
DynamicRenderingとは
Vuejsで作ったSPAページをGoogleBotやTwitterBotなどに対応させる方法の1つ。
ヘッドレスブラウザ(ブラウザを表示無しでHTML/JSだけ解釈させる)を使って、HTMLを生成させます。
(ヘッドレスブラウザの他の用途としては自動テストに使ったりします)
DynamicRenderingについてはGoogleドキュメントにも詳細情報があります。
https://developers.google.com/search/docs/guides/dynamic-rendering
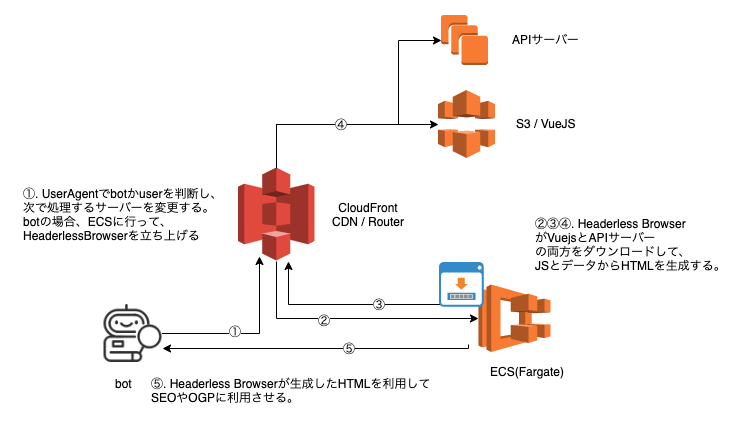
動作イメージ
①一般ユーザーならSPAとして提供するが、botからのアクセスならば静的なHTMLを返却するために、UserAgentでbot判定
②botならばヘッドレスブラウザを起動する。
③同じURL内容をヘッドレスブラウザ内にHTMLをレンダリングさせる。
④HTMLを生成するためにJS、データが必要な場合にはAPIにアクセスする。
⑤ヘッドレスブラウザ上でHTMLを生成しきったら、botに静的なHTMLとして返却する。
ヘッドレスブラウザにはGoogleChromeのpuppeteerを、動作環境ではrendertronを利用しました。
https://github.com/GoogleChrome/puppeteer
https://github.com/GoogleChrome/rendertron
技術選定の経緯
DynamicRenderingする上で、様々なパターンを試してみた。
- AWS Lambda@Edge + ServerlessChrome
- AWS Lambda
- Puppeteerを使ったNodejs自作サーバー
- Rendertron
1. AWS Lambda@Edge
HeadlessChrome自体が40MB以上あるので、CDNエッジサーバーでHeadlessChromeを動かすのは動作やコストで不安があった。
https://www.npmjs.com/package/@serverless-chrome/lambda
2. AWS Lambda
Puppeteer(HeadlessChrome)の起動に2秒ほど掛かっており、Lambdaでキャッシュ化することが難しかった。
const browser = await puppeteer.launch(); ← ここで2秒かかる
この2秒を減少させるためにはbrowserインスタンスを開放しないようにしなければならないと考えた。
Lambda上でglobal変数をおいて、browserインスタンスを保持するようにしていたが、ログを見ていると4アクセスくらいでリフレッシュされるので諦めた。
3. Puppeteerを使ったNodejs自作サーバー
Expressを使って、NodejsサーバーをEC2上に立ててみた。
途中からLRUCacheとか作っていたらRendertronと同じになってきたので、Rendertronに切り替えた。
4. Rendertron
Rendertronは信頼性が高いOSSであるのでこれをベースに開発を行った。
LazyLoad UserAgent判定 MFI対応 のためカスタマイズしたコードを持つことにした。
RendertronはGCP上でデプロイするのは簡単そうだが、AWS上で使うにはサーバー管理が大変そうだった。
そこは、Docker + Fargateを使うことで回避した。
カスタマイズした場所:https://github.com/torico-tokyo/rendertron/compare/c0d47e15700b3e6fc1cf35f009f5a545e45361f6...master
パフォーマンス
GoogleBotは5~6秒間くらいでレスポンスが返却されないとクロールを中断してしまいます。
AWS Lambdaでも実装できたのですが、5秒以上かかることが多々あり、タイムアウトしていました。
Rendertron + Fargateで平均1.7秒くらいで返却できるようにしたのでOKとしました。
更にCloudFrontでのキャッシュやRendertronのメモリキャッシュも実装しています。
具体的な実装
※前提としてAWSを使っています。ご了承ください。GCPの方が実装早そうです。
※CloudFrontの管理はServerlessを使うとめちゃ便利です。 https://serverless.com/
※②③については弊社CTOの記事が丁寧です。こちらも是非見てください。https://tech.torico-corp.com/blog/cloudfront-switch-origin-bot-user-agent/
① Rendertron を Docker上で動作
Dockerfileを作っておきましたので、こちらを参照してください。
https://github.com/torico-tokyo/rendertron-docker/
↑Dockerを起動するためにAWS Fargateを今回は使いました。
②Botかどうかを判定する
Bot判定はCloudFrontで行います。
Lambda@Edgeファンクションを北米バージニアで作成し、CloudFrontのDefault(*)に Viewer Request として登録
'use strict';
/*
Cloudfront の Viewer Request 用のファンクション。
Google Bot からのアクセスの場合、Httpヘッダの bot-user-agent = "1" を設定する。
この後、CloudFront のビヘイビアで bot-user-agent のヘッダーを通し、
さらに Origin Request のLambda で、bot-user-agent を判断し、
Originを切り替える
*/
const bots = [
'Twitterbot',
'facebookexternalhit',
'Facebot',
'AdsBot-Google',
'Bingbot',
'LineBot',
'http://www.google.com/webmasters/tools/richsnippets', // ld-json
'compatible; Google-Structured-Data', // ld-json
'Googlebot',
];
const mediaSuffix = [
'.jpg',
'.css',
'.svg',
'.js',
'.png',
'.ico',
'.xml',
'.txt',
'.woff2',
'.map',
'.json',
'.html',
];
exports.handler = (event, context, callback) => {
const request = event.Records[0].cf.request;
const isBot = bots.some(v => {
return request.headers['user-agent'][0].value.includes(v)
});
const isMedia = mediaSuffix.some(v => {
return request.uri.endsWith(v);
});
if (isBot && !isMedia) {
request.headers['bot-user-agent'] = [
{
'key': 'bot-user-agent',
'value': '1'
}
];
}
callback(null, request);
};
③botだった場合、接続先ORIGINを変更する。
Lambda@Edgeファンクションを北米バージニアで作成し、CloudFrontのDefault(*)に Origin Request として登録
・DIMAIN_NAMEにはHeadlessブラウザがいるサーバー
・PREFIXは /render/https://{リクエストドメイン}/{path} としておく。
ここはrendertronの仕様に合わせておきます。
PREFIXとか環境変数化したかったんですけど、Lambda@Edgeだと環境変数はできないっぽい。
'use strict';
/*
* bot-user-agent の HTTPリクエストヘッダがあったら、
* オリジンを書き換える。
*/
const DOMAIN_NAME = "render.example.com"; // ①で作成したrendertronサーバーのドメイン
const PREFIX = "/render/https://www.XXXXXXXX.com"; // DynamicRenderingしたいSPAサービスのドメイン
exports.handler = (event, context, callback) => {
const request = event.Records[0].cf.request;
const cond1 = 'bot-user-agent' in request.headers;
const cond2 = 'custom' in request.origin;
if (cond1 && cond2) {
const prevUri = request.uri;
request.origin.custom.domainName = DOMAIN_NAME;
request.headers['host'] = [{key: 'host', value: DOMAIN_NAME}];
request.origin.custom.port = 80;
request.origin.custom.protocol = 'http';
request.uri = encodeURI(PREFIX + request.uri);
console.log(`url rewrite: ${prevUri} -> ${request.uri}`);
}
callback(null, request);
};
以上で完了です。
躓いた点
rendertronがChromeを動作させている時、CPU数が2だと止まってしまうことが多々ありました。
rendertron内部でkoaというフレームワークを内部的に使っているそうなのですが、koaのイベントループが詰まってしまうのかなと思います。
実行環境のCPU数は4以上がオススメだと思います。
検証
Search console / 構造化データテストツール / Twitter card validatorでチェックして問題なければOKです。
DynamicRenderingって必要?
将来的にはGoogleBotが進化して不要になっていく技術かもしれませんが、2019年末段階だと有効だと思います。
githubのissueではSEOのためにやらなきゃという人の意見が多かったような気がします。
▼こちらも良かったら!
vue-metaを用いたOGPやJSON-LD用のメタタグ生成:https://qiita.com/T0000N/items/b53ce2ad670e4c966ae8