はじめに
法務省登記所備付地図データ(地図XML)の記事をいくつか投稿しています。
どの町字が任意座標系で位置補正が必要なのかを簡単に知りたいと思っており、いくつかの町字(地番地区)では実際にファイル数ベースで任意座標系の割合を計算してみて方法を探っています。
ここでは、その前段階の練習として、全国の市区町村ごとに、公共座標のXMLファイルの割合をリストしたので、その方法をメモしておきます。
↓こんな感じで、各市区町村の公共座標率をファイル数ベースで計算しました。(筆数ベースではありません)

対象
2023年度の地図XMLファイル
私の環境
Windows PCを使い、解析にはRを使いました。
- Windows 11 home
- R 4.3.2
手順
Step 1: データを眺めて考える
素材は各XMLファイルとその座標系を示したリストになります。先日作ったリストを眺めます。このファイル名の最初の5桁は市区町村コードなので、その5桁ごとに座標系を集計すればよいのではないかと想像します。
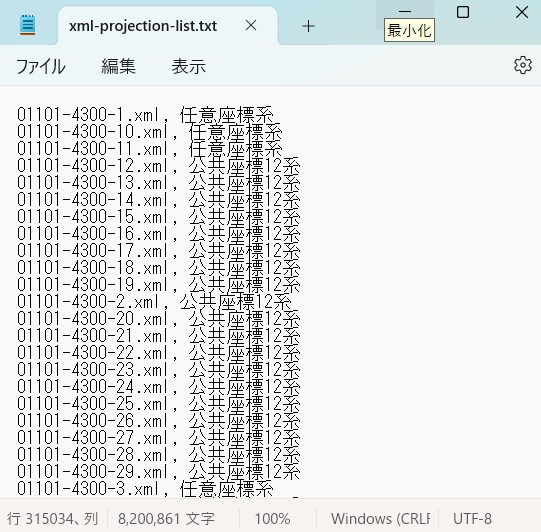
とりあえずそのまま使えそうなので、拡張子をcsvに変えます。
なお、このリストの作り方について書いた先日の記事はこちら↓
Step 2: Rで解析する
Rではgetwd()やsetwd()を使って所定のフォルダに移動します。
今回の処理にはテーブルの操作を行うので、Rのパッケージをいくつかインストールしておきます。
#Step 0: Rの準備(パッケージのインストール)
install.packages('dplyr') #初回のみ)
install.packages('stringr') #初回のみ
library("dplyr") #データベースの操作をするためのパッケージ(filterなど)
library("stringr") #文字列処理のパッケージ
csvファイルを読み込みます。xmlListという変数に代入しておきます。
#Step 1: テーブルの読み込み
xmlList <- read.csv("xml-projection-list.csv",fileEncoding="UTF-8",header=FALSE,colClasses=rep("character",2))

ファイル名は「市区町村コード-法務局コード-ファイルの番号」となっているので、市区町村コードの5桁だけを抜き出します。3列名に新しく追加します。
xmlList[,3] <- substring(xmlList[,1], 1, 5)
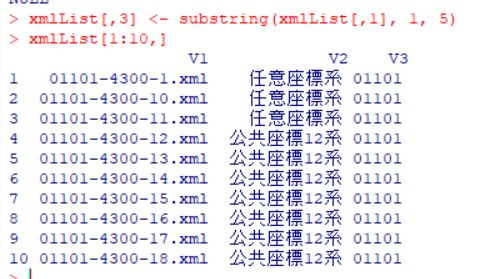
2列目で座標系の前のスペースも読まれているようなので、スペースを削除(置換)します。
xmlList[,2] <- gsub(" ","",xmlList[,2])

次に、市区町村ごとのファイル数を見てみます。
stat1 <-
xmlList %>%
group_by(V3) %>%
summarise(n=n())
print(stat1, n=2100)
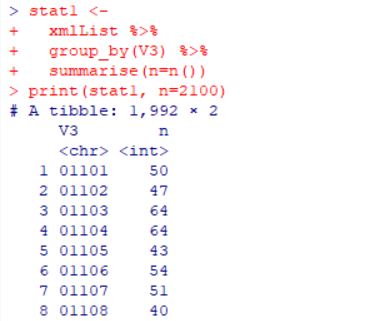
地図XMLファイルのダウンロード単位(市区町村-法務局)は2,005でしたが、市区町村は1,992でしたね。↓
1,992の市区町村ごとに座標系の数を数えます。ただし、ここで数える数はXMLファイルの数をベースにしていますので、筆の数ベースではありません。
# 市区町村ごとに処理する
for (i in 1:nrow(stat1) ){
#変数の初期化
if(exists("target")){rm(target)}
if(exists("stat2")){rm(stat2)}
if(exists("kokyo")){rm(kokyo)}
#市区町村コードを使ってターゲットの市区町村を抜き出す
target <- filter(xmlList, V3 %in% stat1[i,1])
#市区町村ごとに座標系のカウント
stat2 <-
target %>%
group_by(V2) %>%
summarise(n=n())
print(stat2, n=1000)
#公共座標率の計算
if (nrow(stat2[stat2$V2=="任意座標系",]) == 0){
kokyo <- 100
} else {
kokyo <- (nrow(target)-stat2[stat2$V2=="任意座標系",2])/nrow(target) * 100
kokyo <- round(kokyo,2)
}
#出力
write(paste(i,stat1[i,1], paste("ファイル数",nrow(target),sep=": "), paste("公共座標率(%)",kokyo,sep=": "), sep=","),"result.csv", append=TRUE)
}
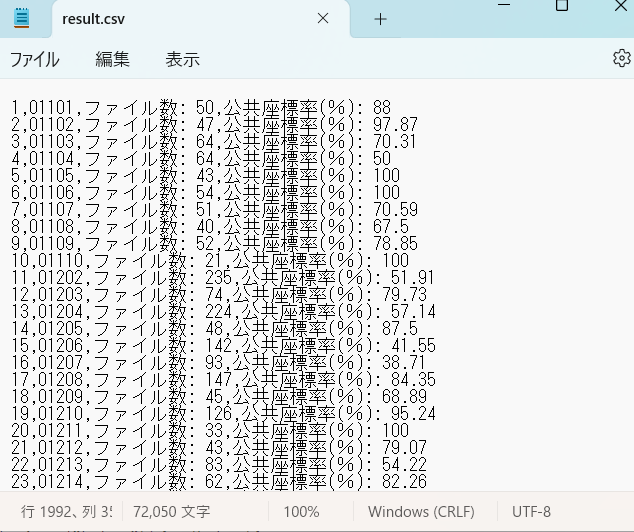
それなりに狙っていたファイルが出ました。2列目が市区町村コードです。
Step 3: 市区町村コードだけではわかりにくいので市区町村名を結合する
ここまででも目的は達成したのですが、コードだとわかりにくいので市区町村コードと市区町村名を結合させます。
法務省の地図XMLはJISの2桁の都道府県コードと3桁の市区町村コードを組み合わせているのですが、それは総務省の全国地方公共団体コードの最初の5桁と共通のところがあります。なので総務省の全国地方公共団体コードを利用します。
全国地方公共団体コードをダウンロードし、全国地方公共団体コードから、左側5桁を抜き出します。エクセルで5桁をとってテキストで出力します。なお、全国地方公共団体コードはJISベースの4桁の市区町村コードに1桁の検証数字をつけたものなので左5桁は地図XMLで使っている市区町村コードと同一になります。

令和6年1月1日に区の再編があった浜松市は新しい区割りでコードがあります。2023年に公開された地図XMLのコードとは一致しないでしょうから注意です。
これらがCSVファイルとして準備できたら、再びRを使ってテーブルを結合します。以下の通り実行すればよいです。left_joinでくっつけます。
result <- read.csv("result.csv",fileEncoding="UTF-8",header=FALSE,colClasses=rep("character",4))
code <- read.csv("code.csv",fileEncoding="UTF-8",header=FALSE,colClasses=rep("character",2))
result2 <- left_join(result,code,by=c("V2"="V1"))
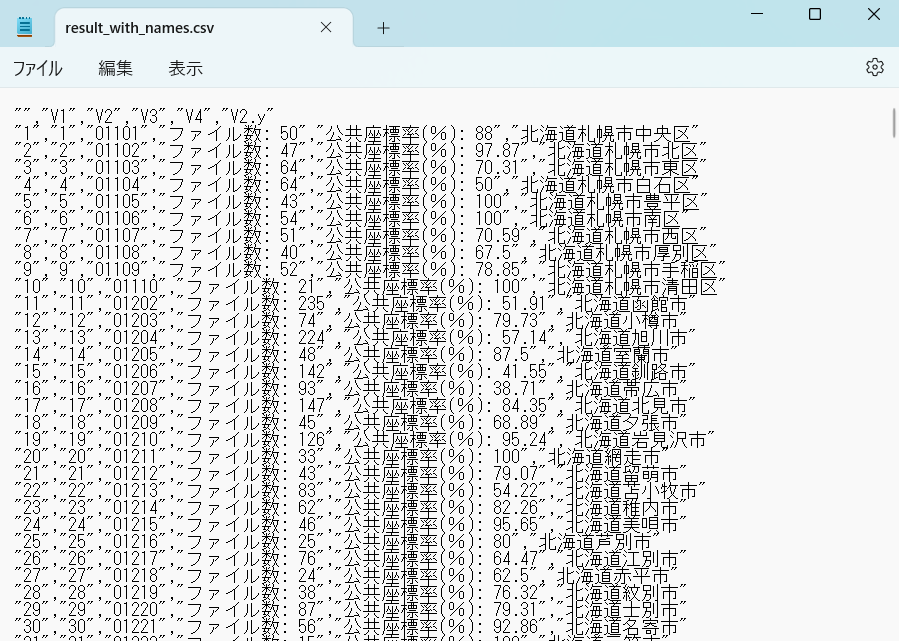
write.csv(result2, file = "./result_with_names.csv")
得られたCSVファイルです。ここでいう公共座標率は地図XMLのファイル数ベースですので注意してください。
まとめ
今回、市区町村別の公共座標率を計算しました(ファイル数ベース)。結果のCSVファイルはこちらに置いてあります。
https://github.com/ubukawa/chizu-xml1/blob/main/kokyo-zahyo-rate_shikuchoson.csv
いくつか市区町村コードが全国地方公共団体コードで見つけられないところがありました。例えば以下の 07309 → 福島県伊達郡飯野町。

合併等で統合された市区町村だと思うのですが、リストをみると地区外のデータなので合併後の市区町村の番号に移動できないのかもしれませんね。
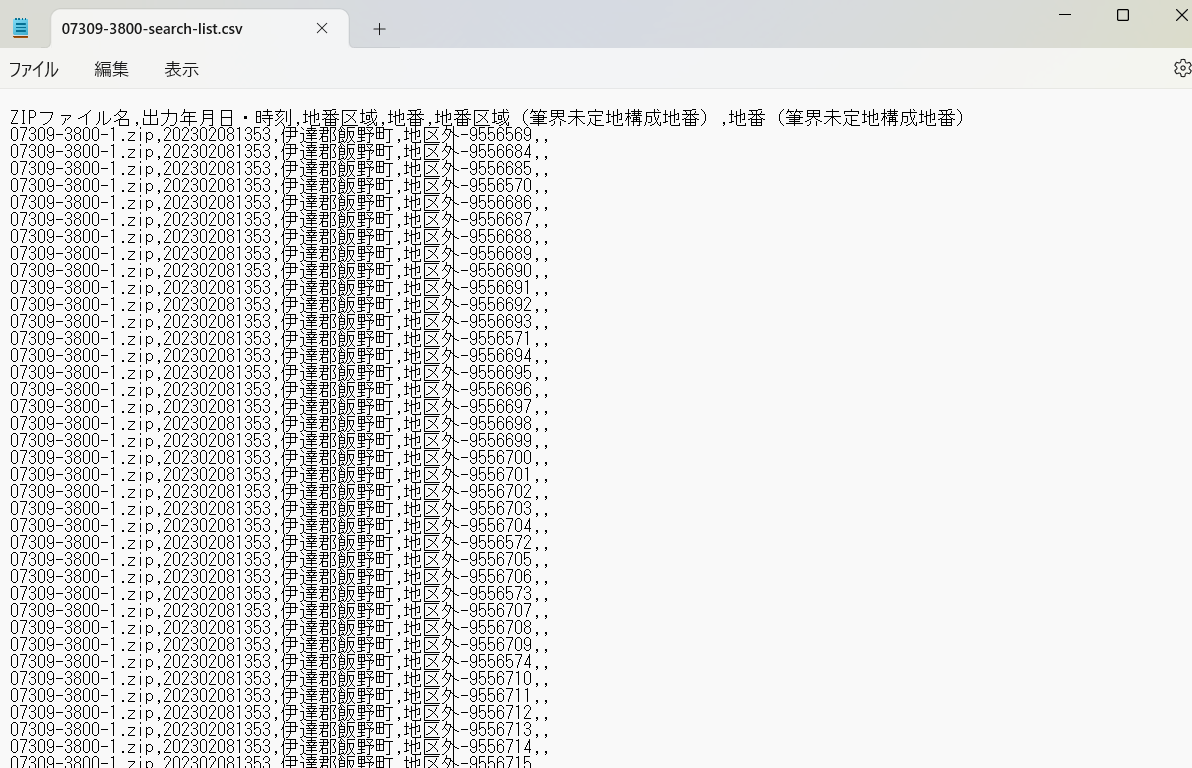
全国地方公共団体コードでは合併等の前の市区町村コードが拾えないことがある点と、地図XMLの市区町村コードには古い市区町村のものもあるということには注意が必要ですね。
なお、今回はファイル数で計算しましたが、各ファイルに含まれる筆数はおそらく出せると思うので、それを使えば筆数ベースでの計算もできるのではないかなと思っています。
参考ページ