挨拶
こんにちはAirion株式会社の大熊と申します。
弊社では最先端のAI活用を活用した研究開発を日々行っており、専門家として他の方にAI活用のアドバイスを行うことも多いのですが、そんな中でよく聞くのが、どのAIを使ったら良いのか分からない という話です。
ここ一年、OpenAIやGoogle等を中心として、ものすごい勢いで新しいAIモデル・サービスが登場しており、専門家ではない方がそれらを把握して最適な選択肢を選ぶのはかなり困難です。
そこで弊社ではスマートAIラボという、社内活用や自社サービスでAIを実装したい企業向けに、数あるAIモデルを精度・コストなどの面から比較し、最適なAIモデルを提案する伴走型支援ソリューションを開始しました。
今回はその紹介も兼ねて、昨日のOpenAI DEVDAYにて大型アップデートが入ったOpenAIのAPIの中からいくつか選んで精度・性能を検証してみました。

TTS (Text-to-speech)
最初にご紹介するのは、音声合成AIのTTS(Text-to-Speech)である。
今回リリースされたTTSモデルには二種類あり、
- tts-1: リアルタイムアプリケーション向けの低レイテンシだが比較的低品質な音声合成モデル
- tts-1-hd: より高品質な音声合成モデル
と説明されている。
ここでは、これらのモデルにどの程度の差があるのか検証し、以下の表に「音声」と「生成にかかった時間」を示す。
| tts-1 | tts-1-hd | Amazon Polly(参考) |
|---|---|---|
| 2.71s | 3.56s | --- |
| 音声 | 音声 | 音声 |
| $0.015 / 1K characters | $0.030 / 1K characters | --- |
上記の表より、多少tts-1-hdの方が安定感のあるテンポではあるものの、音声の品質に大きな差は無く、参考として示したAmazon Pollyより人間に近い音声となっている。
実務においては、料金が倍違うのでtts-1を用いることをお勧めするが、金額はあまり気にならない場合や、少しでも高い精度が必要な場合はtts-1-hdを視野に入れても良いと思われる。
また、リアルタイム音声合成が必要な場合は、レイテンシがより小さいtts-1一択である。
Image Generation
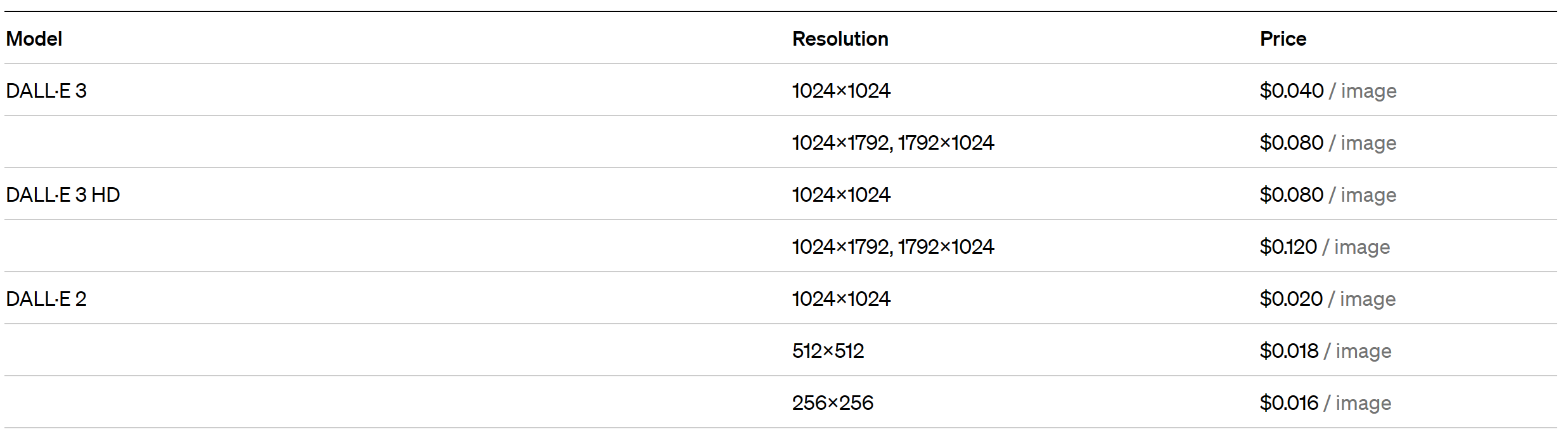
ついにDALL-E3がAPI経由で使えるようになったので、DALL-E2との比較を行ってみた。
プロンプトはとりあえず、
"A cat with feathers on its back playing the piano"(ピアノを弾く背中に羽の生えた猫)
を用いたが、左がDALL-E2、右がDALL-E3 (DALL-E3 HD) と、圧倒的にDALL-E3が優れていることがわかる。

まず、プロンプトの解釈力が違う。DALL-E2では「ピアノを弾く」が「ピアノに乗る」になったり「背中に羽の生えた」が「背中を向けた猫と隣にある羽」みたいな感じになってしまっているが、DALL-E3では入力プロンプトに忠実な出力が得られている。
また、左右の画像はどちらも1024x1024の解像度だが、DALL-E3 の方が画質が格段に優れている。
従って、価格こそ(解像度1024x1024で)E3はE2の2倍だが、E3の方が圧倒的にクオリティが高いので、積極的にE3を使っていくべきだと思う。
※ E2は自然言語の解釈も失敗しやすいので、何度かやり直すうちに結局E3よりもコストがかかってしまった、、、なんてことも起きうる。
ちなみに、E3とE3 HDの差はE2とE3の差と比べると小さいので、基本的にはE3を使っておけば良いと自分は考えている。
Whisper
こちらはAPIではないが、今回のアップデートと同時に音声認識モデルのWhisperのバージョン3(V3)がGithubで公開されたので、こちらの使用感も試してみた。
具体的には、新しく出たバージョンの中で最も大きいモデルである"large-v3"を一つ前のバージョンの"large-v2"と比較した。
なお、用いたデータはオープンソースのデータセットであるCommon Voiceの、Common Voice Delta Segment 15.0の日本語データである。
以下がその結果であるが、今回私が検証した範囲ではv2とv3の間に大きな差は見られなかった。
※ CER (character error rate)、WER (word error rate)で、エラー率なので小さい方が良い。
| (mean/median) | CER ↓ | WER ↓ |
|---|---|---|
| large-v2 | 0.480 / 0.215 | 0.579 / 0.455 |
| large-v3 | 0.464 / 0.209 | 0.673 / 0.500 |
また、V3は現時点ではAPI化されておらず、動かす為にはGPUマシンを自ら用意してサーバーを構築する必要があるので、実務においては公開されているWhisper APIを用いる事をお勧めする。
最後に
今回は、新しくなったOpenAIのAPIの精度を検証しましたが、今後このような検証を数多く行いますので、宜しくお願いします。
また、スマートAIラボにご興味のある方は、弊社のPRをご覧ください。
https://prtimes.jp/main/html/rd/p/000000003.000118893.html