背景
気付けば平成も残すところあと2か月(執筆当時2019/3/6)となりました。
これまで、色々な技術やノウハウが開発され、そしてQiitaで紹介されてきました。
でも、普段の調べもの、気付けばいつも新しい記事にばかり注目しています。
(古い記事を参考にすると動かないこともあるので仕方がないですね…)
意識はしていなくても、知識はこれまで長い時間をかけて一つ一つのタグに積み重なってきました。
そこで、改めてその歴史を振り返ってみませんか?
作ったwebアプリ「Konjaku(今昔)Qiita」概要
KonjakuQiita タグから歴史を振り返る
ソースコード
GitHub - Syuparn/KonjakuQiita: Qiitaのタグができた日時を比較できるwebサイト
Qiitaの主要タグの歴史(=そのタグがいつから使われているのか)を一覧にして眺めることができるサービスです。
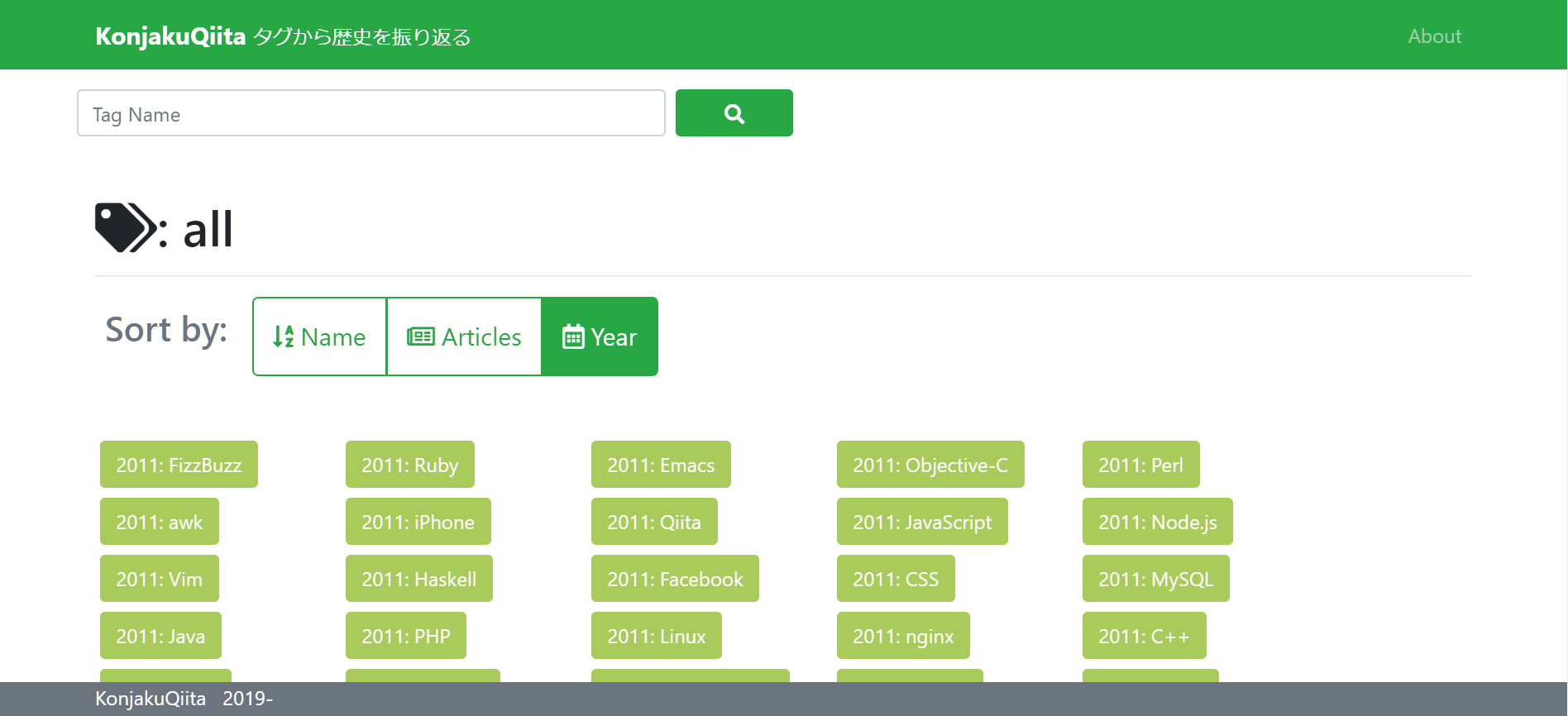
「Ruby」タグは2011年から使われているみたいですね。

一方、「Tensorflow」「深層学習」など、ディープラーニングにまつわるタグは比較的最近作られたものが多いです。
そして、各タグをクリックすると…

そのタグがついた最旧の記事の情報を確認できます。
使った技術
Framework, Libraries
- Sinatra
- ActiveRecord
- Rake
DB
- PostgreSQL
API
- QiitaAPI v2
Server
- Heroku
- UptimeRobot (Herokuのスリープ防ぐ)
UI
- Bootstrap4
- Font Awesome
作った理由
以下の記事
プログラミング歴半年だけど、エンジニアが「知らないことを知る」ためのWEBサービス「Putiita」を作ったよ - Qiita
に触発され、webサービスを作ってみよう!と思い立ちました。二番煎じ。
ちなみに、RailsではなくSinatraを利用したのは、一昨年Railsに挑戦したものの、おまじないが理解できず挫折してしまったからです。
(しかしGemを入れるうちに、気づけばRailsの車輪の再開発に…)
タグ、記事情報取得方法
Qiita APIを用いた取得の流れ
Tagテーブル(タグを格納)とArticleテーブル(記事を格納)を以下のように更新しています。
- 記事数上位700タグの情報(タグ名、記事数)を取得しTagテーブル更新
- Tagテーブル各タグに対し、そのタグがついた記事のうち最も古いものの情報(記事名、いいね数、作成日時等)を取得し、Articleテーブル更新
- 2.で得た最旧記事の作成日時をタグの作成日時としてTagテーブル更新
ちなみに700タグ取得している理由は
- 1日100タグずつフェッチずつすると一週間周期で更新できてきりがいい
- これ以上記事数が少ないタグを調べても属人性が出てしまうのではと感じた(700位のタグは記事数172)
からです。UIが安定したらもう少し増やしてみるかもしれません。
最旧記事の取得
Qiita APIは記事を新しい順に返します。
(需要を考えれば当たり前です…)
ですが、今回欲しいのは一番古い記事です。
そこで、タグ情報の総記事数から最旧記事が含まれるページを逆算しています。
例:
Sinatraの総記事数は379
→ Sinatraタグが付く記事のうち一番古いものは4ページの最後にある(1ページ=100記事の場合)
def fetch_articles(tag_name, page_num)
uri = URI.encode("https://qiita.com/api/v2/items?page=#{page_num}&per_page=#{PER_PAGE}&query=tag:#{tag_name}")
f = open(uri, 'Content-Type' => 'application/json')
JSON.parse(f.read)
end
def update_articles(tag)
num_pages = Tag.find_by(name: tag).num_articles.div(PER_PAGE) + 1
articles = fetch_articles(tag, num_pages)
record_article(tag, articles[-1])
end
問題点:記事一覧の上限は10,000記事
しかし、記事数の多いタグでは上記の方法は使え
ません。Qiita APIが返すのは、クエリの条件に合った最新10,000記事のみです。
そのため、たとえそのタグが付いた記事が10,000以上あっても
https://qiita.com/api/v2/items?page=101&per_page=100&query=tag:Ruby
のようなリクエストには
{"message":"Bad request","type":"bad_request"}
が返ってきてしまいます。
解決策:クエリ"created:<="を使用
そこで、総記事数が10,000以上あるタグに対しては、以下の手順で最旧記事を取得します。

def fetch_articles(tag_name, page_num, before: nil)
uri = URI.encode("https://qiita.com/api/v2/items?page=#{page_num}&per_page=#{PER_PAGE}&query=tag:#{tag_name}")
uri += "+created:<=#{before}" if before
f = open(uri, 'Content-Type' => 'application/json')
JSON.parse(f.read)
end
def update_articles(tag)
num_pages = Tag.find_by(name: tag).num_articles.div(PER_PAGE) + 1
if num_pages <= MAX_PAGES
articles = fetch_articles(tag, num_pages)
record_article(tag, articles[-1])
else
threshold_date = (1..num_pages.div(MAX_PAGES)).to_a.reduce(nil) { |date, _|
articles = fetch_articles(tag, MAX_PAGES, before: date)
articles[-1]['created_at'].match('\d\d\d\d\-\d\d-\d\d')[0]
}
# refrain from page_num == 0
page_num = [num_pages % MAX_PAGES, 1].max
articles = fetch_articles(tag, page_num, before: threshold_date)
record_article(tag, articles[-1])
end
end
(注)10000n番目の記事作成日時に作られた記事を2重計上しているため誤差が発生し、最旧記事は計算上の総記事数よりも後に現れる可能性があります。
そのため、実際には該当記事のページだけでなく次のページも取得しています。
その他はまったところ
"+"を含むタグの処理
URIに含まれる"+"の記号がURI.encode後のspaceとかち合ってしまい、タグ名が正しく送れない(例:"tag:C++"が"tag:C "として扱われてしまう)という問題が起こりました。
しかし、日本語タグも扱うためにはURI.encodeを使わないわけにはいきません。
そのため、タグ名に"+"含まない場合のみencodeし、"+"を含む場合は"%2b"に置換することで対処しています。
(幸いにも記事数上位700タグの中に"+"と非ascii文字を両方含むタグ名はありませんでした。)
def fetch_articles(tag_name, page_num, before: nil)
if tag_name.include?('+')
uri = URI.encode("https://qiita.com/api/v2/items?page=#{page_num}&per_page=#{PER_PAGE}&query=")
# encodeせずに"+"を"%2b"に置換
# もしencodeしたら"%2b"の"%"がさらに"%25"に置換され"%252b"になってしまう
uri += "tag:#{tag_name.gsub(/\+/, '%2b')}"
else
uri = URI.encode("https://qiita.com/api/v2/items?page=#{page_num}&per_page=#{PER_PAGE}&query=tag:#{tag_name}")
end
uri += "+created:<=#{before}" if before
...
end
ごり押しなので、もっと良い方法がありましたらご教授いただけるとありがたいです。
ローカル環境でのPostgreSQL導入
ubuntu16.04でPostgreSQLをインストールしたときに、接続ができずてこずってしまいました。
インストール時には、PostgreSQLの接続権限はpostgresユーザに与えられる(adminでは使えない!)ので、権限を変更する必要があります。
参考:
UbuntuでPostgreSQLを使ってみよう (2) | Let's Postgres
今後の課題
-
コードを綺麗に
特にrakeとerb… -
スマホのレイアウト調整
微妙にタグ同士がくっついてしまいます -
作成日時のfetch失敗したタグの処理
今は応急処置として作成日時2019年のタグ=最旧記事作成日時取得失敗とみなして非表示にしています