現場で使える!TensorFlow開発入門の内容を自分用にメモります.
最低限のMulti-Layer Perceptron(MLP)とTensorFlowの知識は仮定.
Convolutional Neural Network(CNN)とは?
普通のDNNとの違いは入力である画像データの性質を利用して,パラメータの数を削減していること!パラメータ数を減らすために畳み込み層を,画像の小さな位置変化に対する頑健性を確保するためにプーリング層を使い,これらを繰り返すのが特徴です.
この記事ではCNNの概要をまとめつつ,Kerasでコードを書き,なんとなくCNNができるようになります.
流れは以下の感じ.
- 使うデータの説明
- 畳み込み層の説明
- プーリング層の説明
- その他諸々の層の説明
- モデルの訓練
使用データ(CIFAR-10)
使うデータはCIFAR-10と呼ばれる60000枚のの画像データですわ.
- 50000枚の訓練用データと10000枚のテスト用データに分割されてる
- 各画像は10個のクラスラベルに分類されてる(動物と乗り物)
- Kerasに標準装備されてる
このデータセットをインポートして適当に整形しましょう.
from tensorflow.python.keras.datesets import cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
こんな感じでデータが取れます.中身のデータを
print("x_train.shape:",x_train.shape)
print("y_train.shape:",y_train.shape)
print("x_test.shape:",x_test.shape)
print("y_test.shape:",y_test.shape)
というコードで確認すると
x_train.shape: (50000, 32, 32, 3)
y_train.shape: (50000, 1)
x_test.shape: (10000, 32, 32, 3)
y_test.shape: (10000, 1)
という出力が出るです.モデルが取り扱いやすいサイズにデータを整形するために,正規化とラベルの1-hotベクトル化をしときます.
from tensorflow.python.keras.utils import to_categorical
# 特徴量の正規化
x_train = x_train / 255.
x_test = x_test / 255.
# クラスラベルの1-hotベクトル化
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
この後KerasのSequential APIを使っていろんな層を追加していくので,以下のコードでモデル構築の準備をしておきます.
from tensorflow.python.keras.models import Sequential
model = Sequential()
畳み込み層
畳み込み層は画像に対してフィルタ(カーネル)を適用していき,画像の特徴量を抽出する役目を担います.推定が必要になるパラメータ数を画像のサイズではなくフィルタのサイズに依存するようなります.したがって,普通のMLPを適用するのと違い,画像のサイズが大きくなってもフィルタのサイズが増えるわけではないので,入力画像のサイズに対してパラメータ数が増えません.
畳み込み層の仕組み
で,具体的に何をしているかということを下図で説明します.
入力データである画像が
| 0 | 1 | 1 | 0 | 1 |
|---|---|---|---|---|
| 0 | 0 | 1 | 1 | 0 |
| 0 | 0 | 1 | 1 | 1 |
| 0 | 1 | 0 | 0 | 0 |
| 1 | 0 | 1 | 1 | 0 |
| となっていて,フィルタが |
| 0 | 1 | 0 |
|---|---|---|
| -1 | 0 | 1 |
| 0 | -1 | 0 |
| となっているとします. | ||
| この入力データとフィルタを使って特徴マップを作成します. | ||
| 特徴マップとは入力データの中でフィルタを動かしたときに畳み込み計算の値を並べた行列です.このとき,フィルタを動かすピクセル数をストライドといいます.たとえば,上記フィルタをストライド=1で入力データに対して特徴マップを作ったときどうなるかというと,まずは入力データの左上部分の |
| 0 | 1 | 1 |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 0 | 1 |
| に対して畳み込み計算すると,各要素の積 |
| 0x0=0 | 1x1=1 | 1x0=0 |
|---|---|---|
| 0x-1=0 | 0x0=0 | 1x1=1 |
| 0x0=0 | 0x-1=0 | 1x0=0 |
| と計算できて,これら要素の和は2になります.なので出来上がる特徴マップは |
| 2 | ||
|---|---|---|
| と言う形になっていることがわかります. この調子でストライド=1で特徴マップを計算していくと |
| 2 | 1 | -2 |
|---|---|---|
| 0 | 2 | 1 |
| 0 | -1 | 0 |
| となります.畳み込み層ではこんな感じで入力サイズが大きくなっても特徴マップのサイズが大きくなるだけでフィルタのサイズが変わるわけではないので,パラメータが増えません. |
畳み込み層を追加するコード
KerasのSequential APIのmodel.addでConv2Dレイヤーを使えば冒頭のモデルに畳み込み層を追加できます.
from tensorflow.python.keras.layers import Conv2D
model.add(
Conv2D(
filters=32,
input_shape=(32, 32, 3),
kernel_size=(3, 3),
strides=(1, 1),
padding='same',
activation='relu'
)
)
Conv2Dのオプションは以下の感じです.
-
filters:出力チャンネル数 -
input_shape:入力データのサイズ -
kernel_size:フィルタ(=カーネル)のサイズ数.3x3とか5x5とか奇数正方にすることが多め -
strides:前述のストライドの幅(フィルタを動かすピクセル数) -
padding:データの端の取り扱い方の指定.入力データの周囲を0で埋める(ゼロパディング)したいときは'same'を指定,ゼロパディングしたくないときは'valid'を指定 -
activation:活性化関数
もいっちょ畳み込み層を追加しときます.
model.add(
Conv2D(
filters=32,
kernel_size=(3, 3),
strides=(1, 1),
padding='same',
activation='relu'
)
)
プーリング層
画像を縮小するような層のことで,小さな位置変化に対して頑健にするような役目を持つ層です.
プーリング層にはいくつか種類がありますが,最もよく使われるマックスプーリングでは入力データを小さな領域に分割し,各領域の最大値を取ってくることでデータを縮小します.
たとえば,入力データ:
| 1 | -1 | -2 | 1 |
|---|---|---|---|
| -2 | 2 | 2 | -2 |
| 1 | 0 | 2 | 1 |
| 0 | -1 | -2 | -2 |
| に対してマックスプーリングを適用すると,2x2の4つの領域に分割して各2x2の行列の最大値をとることで |
| 2 | 2 |
|---|---|
| 1 | 2 |
| という結果になります.こうしてデータが縮小されることで,計算コストが軽減されることに加え,各領域内の位置の違いを無視するため,モデルが小さな位置変化に対して頑健になります. |
プーリング層を追加するコード
マックスプーリングをする層はMaxPoolin2Dを使うことで追加できます.ここでは2x2のマックスプーリング層を追加してます.コードは以下の感じです.
from tensorflow.python.keras.layers import MaxPooling2D
model.add(MaxPooling2D(pool_size=(2,2)))
ドロップアウト層の追加
ドロップアウト層なんてものを追加することでネットワークの自由度を抑え,モデルの頑健性を高めることができます.原理としては,自由度を抑えることで過学習を防ぐことになります.
行われるのはネットワーク内の一部のユニットを無効するだけです.入力値から一定比率(rate)分だけランダムに選択されたユニットに対する入力値を強制的に0にして,ユニットを無効化しています.
注意点は過度にドロップアウトすると学習不足や学習速度の低下につながる可能性あることです.
イメージはこんな感じ.

KerasではDropoutレイヤーを追加することで実行できます.
from tensorflow.python.keras.layers import Dropout
model.add(Dropout(0.25))
もいっちょ畳み込み層・プーリング層・ドロップアウト層を追加
最後に全結合層を追加しますが,その前に畳み込み層とプーリング層を追加しときます.深層学習では層を積み重ねるごとに表現力が高まることが知られているので.
model.add(
Conv2D(
filters=64,
kernel_size=(3, 3),
strides=(1, 1),
padding='same',
activation='relu'
)
)
model.add(
Conv2D(
filters=64,
kernel_size=(3, 3),
strides=(1, 1),
padding='same',
activation='relu'
)
)
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
全結合層の追加
全結合層は2次元テンソルしか受け取れません.プーリング層の出力は4次元テンソルになっているので,2次元テンソルに展開してくれるFlattenレイヤーをはさんで全結合層を追加します.Flattenレイヤーの追加は以下のコードです.
from tensorflow.python.keras.layers import Flatten
model.add(Flatten())
全結合層は以下の感じです.
from tensorflow.python.keras.layers import Dense
model.add(Dense(units=512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(units=10, activation='softmax'))
モデルの訓練
モデルができたのでmodel.compileして訓練をしましょう.
from tensorflow.python.keras.callbacks import TensorBoard
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
tsb=TensorBoard(log_dir='./logs')
history_adam=model.fit(
x_train,
y_train,
batch_size=32,
epochs=20,
validation_split=0.2,
callbacks=[tsb]
)
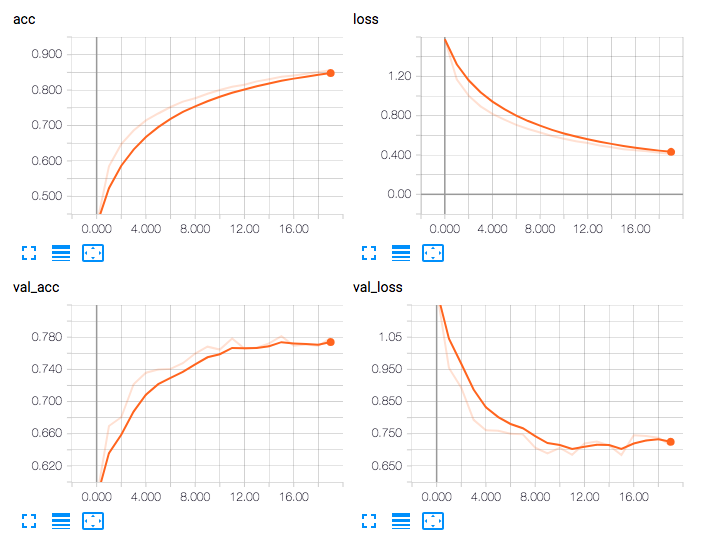
結果をTensorBoardで確認すると下の感じ.