中学数学の知識で作るDeepLearning
高校数学を履修していないので中学数学までの知識しかないですが、機械学習に興味があったので
ゼロから作るDeep Learning――Pythonで学ぶディープラーニングの理論と実装 を読んでみました。以下「本書」と呼ぶ事にします。
事前準備と参考資料
Pythonの実行環境はanaconda+Jupyter Notebookを使用しました。
三章までは事前知識が中学数学でも以下を参考にする事で理解できると思います。
行列等線形代について
ヨビノリたくみさん
微分の概念や微分法について
Try IT(トライイット)
高校数学の基礎
長岡先生の授業が聞ける高校数学の教科書
ネイピア数について
鈴木貫太郎さん
学生時代に比べると勉強方法が格段に進化しているのに驚きました。特に学習系のYouTuber様には頭が上がりません。ありがとうございました。
たくみさんの
「世界は微分で記述され、積分で読む」
との名言は中学生二年生の心を持ち続けている私のテンションを上げてくれました。
1章 Python入門
Pythonの基本的な操作について学びます。
本書は機械学習でよく使用されるTensorFlowやscikit-learn等のフレームワークを使用せず、NumPyとMatplotlibのライブラリを使用してニューラルネットワークを構築します。
NumPyは行列等を効率よく計算でき、Matplotlibを使う事で関数のグラフの描画ができるので視覚的に関数の処理を理解できます。
python使用する文法やメソッドはこの章で優しめに説明してくれるので事前準備は必要ないかと思います。ここで紹介していないメソッドがあっても、都度補足説明をしてくれます。優しいですね。
2章 パーセプトロン
パーセプトロンとは複数の信号を入力として受け取り、一つの信号を出力します。ニューラルネットワークを構築基礎になっている為、パーセプトロンを理解する事で次の章からのニューラルネットワークについて理解しやすくなります。
信号の受け取りといっても、計算自体は場合分けをした多変数関数なので数式で表すと
y=\left\{
\begin{array}{ll}
0 (w_1x_1+w_2x_2 \leqq\theta )\\
1 (w_1x_1+w_2x_2 >\theta )
\end{array}
\right.
こうなります。
xは入力信号、wは重みを表します。それぞれの添え字はインデックスになります、$\theta$は閾値となります。入力値と重みの積の結果の総和が閾値を超えればyが1を出力します。
これだと閾値のみが変数ではなくて気持ち悪いですねので、こうしましょう。
バイアスを足し算する事で閾値を調節できるようになりました。
y=\left\{
\begin{array}{ll}
0 (b+w_1x_1+w_2x_2 \leqq0 )\\
1 (b+w_1x_1+w_2x_2 >0 )
\end{array}
\right.
このパーセプトロンを使って論理回路を考えてみます。入力値がどちらも1の場合のみ閾値を超える論理回路を作りたい場合論理回路が考えられますでしょうか。
真理値表だとこんな論理回路になります。

この論理回路をANDゲートと呼び、コードで実装するとこうなります
def AND(x1,x2):
x=np.array([x1,x2]) #入力値を格納
w=np.array([0.5,0.5])#重みを格納
b=-0.7 #閾値を調節するバイアスの値を設定
tmp=np.sum(w*x)+b #入力値*重み+バイアス処理
if tmp <= 0:
return 0
else:
return 1
AND(1,1)
# 出力
1
これで先ほどの論理回路を実現するパーセプトロンを作成する事ができました。
他にも重みを調節する事で
・NANDゲート(入力のどちらも0。NotANDの意味)
・ORゲート(入力のどちらが1もしくはどちらも1)
といった論理回路を作成できます。
しかし、単層のパーセプトロンで表現できない論理回路もあって、XORゲート(入力のどちらかが1)は表現できません。単層でダメなら層を重ねましょう。図で書くとこうなります。
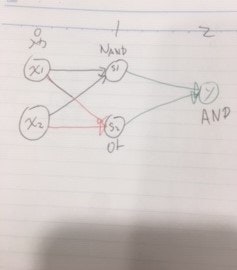
層を重ねる事で複雑な問題に対応する事が分かりました。
しかし、現実の問題に出力が2種類しかない問題は多くありません。
例えば、入力値が身長と体重を入力して洋服のサイズ予測の確率を予測するモデルを構築したい場合、そのまま次の層に渡してしまうと計算がやりくそうです。
そこで、活性化関数を使う事でパーセプトロンの出力を調節する事が出来ます。
3章 ニューラルネットワーク
パーセプトロンの計算結果を関数で変換しましょう。変換する関数を活性化関数と呼びます。$h(a)$が活性化関数です。
a=b+w_{1}x_{1}+w_{2}x_{2}\\
\\
y=h(a)
今回の活性化関数はシグモイド関数を使います。シグモイド関数は非線形関数で入力に対し、0から1までの値を出力します。数式ではこうなります
f(x) = \frac{1}{1+e^{-x}} \ \
数式は覚えにくいのでMatplotlibで描画します
import numpy as np
import matplotlib.pylab as plt
def sigmoid(x):
return 1/(1+np.exp(-x))
x=np.arange(-10.0,10.0,0.1) #arange関数の引数は(start, stop, step)
y=sigmoid(x)
plt.plot(x,y)
plt.ylim(-0.1,1.1)
plt.show()
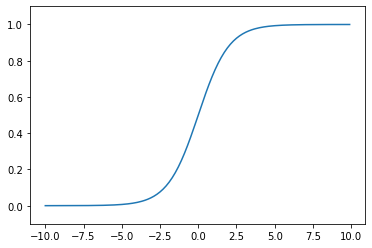
matplotlibを使えばすぐにグラフを描画してくれるので、関数のイメージがつきにくい時はおすすめです。
しかしこのグラフ疑問点が・・・。あれ?本書ではシグモイド関数は
どんなに入力信号の値が小さくても、またどんなに入力信号の値が大きくても、出力信号の値を0から1の間に押し込める
と説明していますが、出力が1になる値が出現しています。シグモイド関数の定義から1や0はあり得ないので調べてみると
機械学習のPython との出会い
から引用
NumPy での実数演算は,精度が有限桁の浮動小数点を用いて行っているため,絶対値が大きすぎるオーバーフローや,小さすぎるアンダーフローといった浮動小数点エラーを生じます. そのため,意図したとおりの計算結果を得ることができません. こうした問題を避けるため,浮動小数点演算の制限を意識して数値計算プログラムを実装する必要があります.
と説明がある通りNumPyの仕様のようです。
活性化関数を使う事で次の層に値を渡しやすくなりました。
また、活性化関数を使う事でパーセプトロンからニューラルネットワークと呼び方が変わるのが一般的なようです。
ニューラルネットワークではニューロンの数が膨大になる為、一つ一つ関数を作成していたら作業量が大変になります。そこで行列の演算を使用し効率的にパラメーターを計算していきましょう。
多次元配列の計算
ここから先は行列の演算の理解が必要になります。行列の演算についてはヨビノリたくみさんの動画がおすすめです。
線形代数学
なぜ行列の演算を使うかというと、例えばこんなニューラルネットワークを作りたいとします。
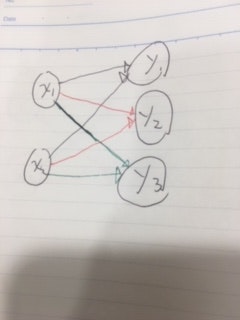
入力値に重みを掛け算した単純なニューラルネットワークです。
行列の積を使わず実装します。(もっと良い書き方はあるはず)
import numpy as np
def y1(x1,x2):
x=np.array([x1,x2]) #入力値を格納
w1=np.array([2,3])#重みを格納
y1tmp=np.sum(w1*x) #入力値*重み
return y1tmp
def y2(x1,x2):
x=np.array([x1,x2])
w2=np.array([5,2])
y2tmp=np.sum(w2*x)
return y2tmp
def y3(x1,x2):
x=np.array([x1,x2])
w3=np.array([3,4])
y3tmp=np.sum(w3*x)
return y3tmp
print(y1(3,4))#18
print(y2(3,4))#23
print(y3(3,4))#25
はい。結構面倒です。そこで行列の積を使えば。
x1=3
x2=4
import numpy as np
X=np.array([x1,x2]) #入力層の配列を生成
W=np.array([[2,5,3],[3,2,4]]) #二次元配列(行列の事)を生成。行列は大文字で表現する。
print(W)
# 出力
# [[2 5 3] #一列目がy1に二列目がy2に・・・とそのぞれの重みに対応します
# [3 2 4]]
Y=np.dot(X,W)
print(Y)
# 出力
# [18 23 25] #y1,y2,y3の出力結果
行列の積の性質を利用して簡単に書く事が出来ました。これで出力層が増えてもW行列の列数を増やせばよいだけです。
これでニューラルネットワークの入力と出力と重みの実装が出来たので0~9までの手書き文字の数字を認識するモデルを作ってみます。出力層には0~9の数字を予測する確率の出力が必要になりますので、出力関数ソフトマックス関数を使います。
ソフトマックス関数は数式で表すと
y_{k} = \frac{exp(a_{k})}{\sum_{i=1}^{n}exp(a_{i})} \ \
出力した値の配列の総和が1になるので分類問題で確率を求める際に使います。文字認識の場合はそれぞれの数字に対しての確率を出力する事が出来ます。
手書き文字の認識のデータセットはMNISTを使います。機械学習のHello Worldみたいなもんです。
手書き文字の画像の学習用データが6000とその正解ラベル。検証用が10000とその正解ラベルが入っています。
画像の一つのデータは24*24の784の配列なので入力層は784、隠れ層は2でニューロンの数は50,100で設定します。出力層は0~9までの10となります。
def softmax(x):
x = x - np.max(x) # オーバーフロー対策
return np.exp(x) / np.sum(np.exp(x))
def sigmoid(x):
return 1 / (1 + np.exp(-x))
まずは活性化関数を定義します
import sys, os
sys.path.append(os.pardir) # 親ディレクトリのファイルをインポートするための設定
import numpy as np
import pickle
from dataset.mnist import load_mnist
# xが画像データ、tが正解ラベル
def get_data():
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False)
return x_test, t_test
# MINSTデータセットの読み込み。引数は、255のデータを0~1までに変更(学習コストを下げる為)、一次元配列に変更、OneHot表現を避ける
with open("sample_weight.pkl", 'rb') as f:
network = pickle.load(f)
# 事前の学習済みデータ確認
print(len(network['W1']))
print(len(network['W2']))
print(len(network['W3']))
# 出力
# 784
# 50
# 100
次にMNISTのデータセットを読み込みます。次の関数定義でも使うのですが、今回はニューロンの数が多いので事前にsample_weight.pklから学習済みのパラメーターを使います。printで中身の要素数を確認します。
それぞれ各層のニューロン数に対応しているのが分かります。
# 事前に保存されている学習済みのパラメーターを読み込み。
# ディクショナリ型で保存されている
def init_network():
with open("sample_weight.pkl", 'rb') as f:
network = pickle.load(f)
return network
def predict(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']#重みを設定
b1, b2, b3 = network['b1'], network['b2'], network['b3']#バイアスを設定
a1 = np.dot(x, W1) + b1#隠れ層へのパラメーターの計算
z1 = sigmoid(a1) #シグモイド関数で出力
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = softmax(a3)#ソフトマックス関数で出力。10の値が出力される
return y
学習済みデータを格納する関数と
ニューラルネットワークの計算を行う関数を定義します
x, t = get_data() #MINSTデータを代入
network = init_network() #学習済みデータを代入
accuracy_cnt = 0 #精度の初期化
for i in range(len(x)): #forループで学習済みデータを計算
y = predict(network, x[i]) #出力結果をyに格納
p= np.argmax(y) # 最も確率の高い要素のインデックスを取得
if p == t[i]: #テストラベルと一致してたら精度に1を足す
accuracy_cnt += 1
print("Accuracy:" + str(float(accuracy_cnt) / len(x))) #精度を計算
# 出力
# Accuracy:0.9352
計算を行うと93%の精度が出ました。これはあらかじめ学習済みのデータを使いましたので次の章では学習の方法について記事を書いていきます