Apple製のGPUシェーダー言語Metalにて、ループ計算を効率的に行うことができる仕組み「Raster Order Group」について実験してみたのでまとめてみたいと思います。
はじめに
この記事では以下について紹介します。
- Raster Order Groupとは?
- Raster Order Groupの処理の流れ
- 実装における注意点
以下では、Appleが公開しているサンプルコード (リンク) をベースに、コードの中身の簡単な解説と実装時の注意点について説明します。
Raster Order Groupとは?
例えば以下例のように、一番めのテクスチャに対してカーネル計算を行い、その結果を使って次のテクスチャを描画するような場合、従来の方法だとTexture1のカーネル計算の結果を受け取るためには一度結果のデータをGPUからCPUへ転送し、改めてCPUからGPUへ転送するような手順を踏まなければ、計算結果を反映下処理ができませんでした。

 *Apple開発者ページより ([リンク](https://developer.apple.com/documentation/metal/rendering_a_scene_with_deferred_lighting)) より.
*Apple開発者ページより ([リンク](https://developer.apple.com/documentation/metal/rendering_a_scene_with_deferred_lighting)) より.
このような手順を踏むと、上図のように余計な待ち時間が発生することは素より、この実装におけるより大きな問題はCPU-GPU間のデータ転送に小さくないコストが掛かる事にあります。(下図)
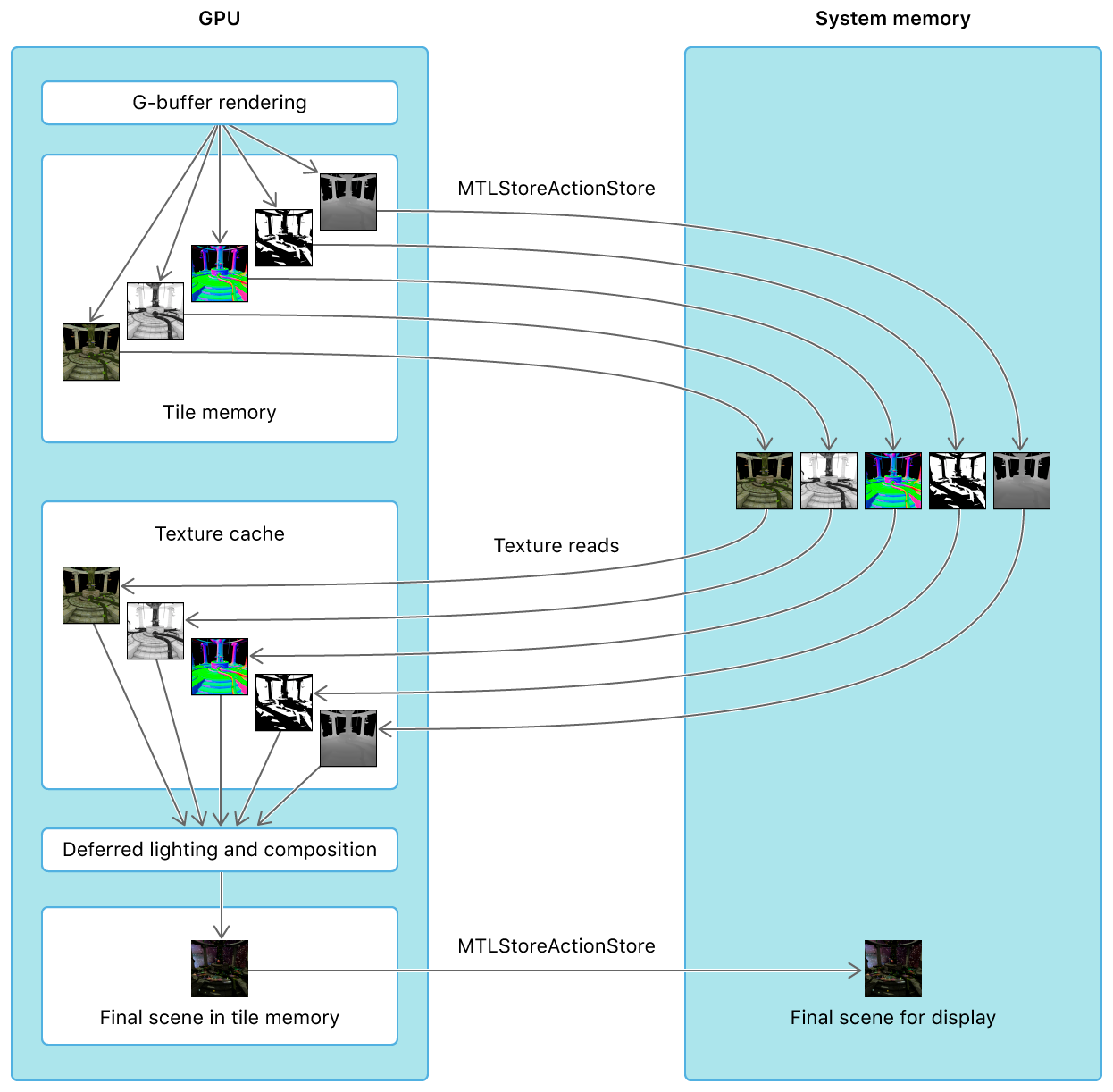
*Apple開発者ページより (同上ページ)
CPUへの無駄なデータ転送を抑制する
そこでこのような計算を実施するための自然な方法として、GPU内部のメモリに一時的に中間状態のbufferを保持しておき、CPU-GPU間のデータ転送に係るオーバーヘッドを極力減らす手法 "Raster Order Group" がMetal2で公開されました。
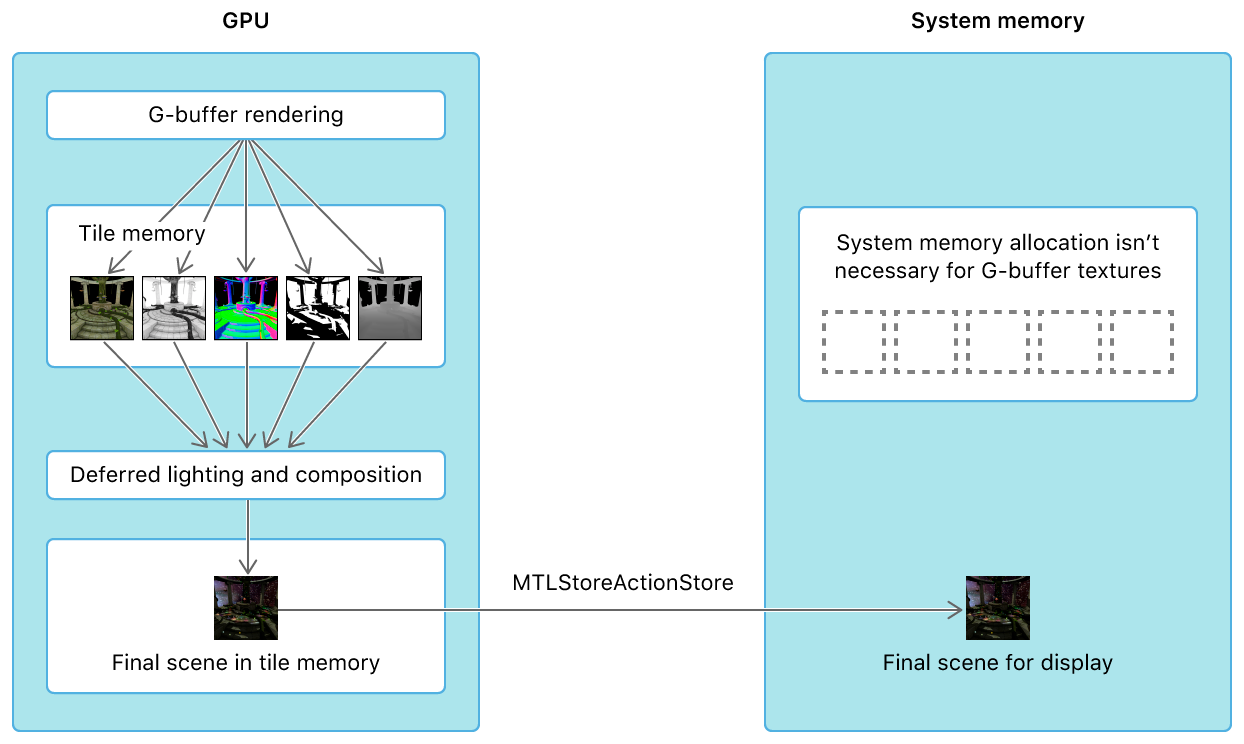
 *Apple開発者ページ (同上ページ)
*Apple開発者ページ (同上ページ)
これと同様の機能は、例えば Unity (HLSL) では GrabPass{} が相当します. 一般的にはマルチパスレンダリングと呼ばれる機能になります.
Raster Order Groupの処理の流れ
基本的に下図のように、MTLTextureオブジェクトを用意してループ計算結果をRead/Writeしながら描画を進めることになります.

textureの設定の仕方は筆者の把握する限り、2通りのやり方があると思います.
-
renderEncoder.setFragmentTexture()でループ描画用の MTLTexture オブジェクトを設置して描画する方法. - 1つは
renderPassDescriptor.colorAttachmentに設置する MTLTexture オブジェクトに描画する方法.
これらに共通する点は、入力に加えて描画のループ回数分だけCPU側で MTLTexture オブジェクトを用意し、ループ計算の度に結果を texture に write するという点です. この texture の Read/Write においては注意点があります.
- 1つのrenderPassDescriptorに対しcolorAttachmentは8つまで. つまり8ループが限界である.
- これはどうやら renderEncoder.setFragmentTexture() を使う場合でも同じで、1度に8ループまでが限度になっているようである.
- 同じtextureに2度書き込むことはできない. よって必ず描画回数分のtextureを用意する必要がある.
- (textureのReadに関する重要な注意点は次節で述べます.)
具体的な実装
1. colorAttachmentを使う方法
ここではApple開発者ページのコードを引用します.
struct GBufferData
{
half4 lighting [[color(AAPLRenderTargetLighting), raster_order_group(AAPLLightingROG)]];
half4 albedo_specular [[color(AAPLRenderTargetAlbedo), raster_order_group(AAPLGBufferROG)]];
half4 normal_shadow [[color(AAPLRenderTargetNormal), raster_order_group(AAPLGBufferROG)]];
float depth [[color(AAPLRenderTargetDepth), raster_order_group(AAPLGBufferROG)]];
};
lightingやalbedo_specularはtexture名で、それぞれに紐づくtextureオブジェクトはrenderPassDescriptorで設定するcolorAttachmentに渡されています.
そして上記のcolor(n)はcolorAttachmentのインデックスを、raster_order_group(n)は本稿の主題であるループ計算のグループを示すインデックスを、それぞれ設定している修飾子です.
raster_order_groupのインデックス値が同じtexture同士は同じタイミング (同じループ) で描画されます.
ちなみにraster_order_groupのインデックスの数値はループ計算の順番とは関係ありません. しかし可読性のため、ループ計算の順番とインデックスの数値を揃えておいた方が無難かもしれません.
以下は入力されたMTLTextureをreadしてraster_order_group指定されたcolorAttachmentへwriteする部分の抜粋です.
fragment GBufferData gbuffer_fragment(ColorInOut in [[ stage_in ]],
constant AAPLUniforms &uniforms [[ buffer(AAPLBufferIndexUniforms) ]],
texture2d<half> baseColorMap [[ texture(AAPLTextureIndexBaseColor) ]],
texture2d<half> normalMap [[ texture(AAPLTextureIndexNormal) ]],
texture2d<half> specularMap [[ texture(AAPLTextureIndexSpecular) ]],
depth2d<float> shadowMap [[ texture(AAPLTextureIndexShadow) ]])
{
(略)
half4 base_color_sample = baseColorMap.sample(linearSampler, in.tex_coord.xy);
half4 normal_sample = normalMap.sample(linearSampler, in.tex_coord.xy);
half specular_contrib = specularMap.sample(linearSampler, in.tex_coord.xy).r;
// Fill in on-chip geometry buffer data
GBufferData gBuffer;
(略)
// Store shadow with albedo in unused fourth channel
gBuffer.albedo_specular = half4(base_color_sample.xyz, specular_contrib);
// Store the specular contribution with the normal in unused fourth channel.
gBuffer.normal_shadow = half4(eye_normal.xyz, shadow_sample);
gBuffer.depth = in.eye_position.z;
(略)
return gBuffer;
colorAttachmentへの書き込みはreturnによって行われます. 複数のcolorAttachment (MTLTexture) へwriteするためには上記のように構造体を用います.
texture2dオブジェクトのbaseColorMapなどはrenderEncoderのsetFragmentTexture()で渡される入力textureです. これを所定の描画を行い、raster_order_groupを指定したGBufferDataの要素に渡します. これをreturnすれば描画順を考慮して出力してくれます.
fragment AccumLightBuffer
deferred_directional_lighting_fragment(QuadInOut in [[ stage_in ]],
constant AAPLUniforms & uniforms [[ buffer(AAPLBufferIndexUniforms) ]],
GBufferData GBuffer)
{
AccumLightBuffer output;
output.lighting =
deferred_directional_lighting_fragment_common(in, uniforms, GBuffer.depth, GBuffer.normal_shadow, GBuffer.albedo_specular);
return output;
}
次ループで先ほど書き込まれたtextureをreadするのは簡単で、fragment関数の入力にGBufferDataを指定して要素にアクセスするだけです.
なおraster_order_group指定されたtextureの描画順ですが、これはrenderEncoderのdraw関数のコール順となります.
_viewRenderPassDescriptor.colorAttachments[AAPLRenderTargetLighting].texture = drawableTexture;
_viewRenderPassDescriptor.depthAttachment.texture = self.view.depthStencilTexture;
_viewRenderPassDescriptor.stencilAttachment.texture = self.view.depthStencilTexture;
id <MTLRenderCommandEncoder> renderEncoder = [commandBuffer renderCommandEncoderWithDescriptor:_viewRenderPassDescriptor];
renderEncoder.label = @"Combined GBuffer & Lighting Pass";
[super drawGBuffer:renderEncoder];
[self drawDirectionalLight:renderEncoder];
[super drawPointLightMask:renderEncoder];
[self drawPointLights:renderEncoder];
[super drawSky:renderEncoder];
[super drawFairies:renderEncoder];
[renderEncoder endEncoding];
コードの詳細は割愛しますが下記のdrawGBuffer等の関数中でrenderEncoder.draw---が呼ばれ描画されています. renderEncoderが生成されてからrenderEncoder.endEncoding()が呼ばれるまでの間にfragment関数を呼ぶ順でループ順が考慮されてraster_order_groupが機能する仕組みです.
2. setFragmentTextureを使う方法
renderEncoder.setFragmentTexture()に渡すtextureへのread/writeでも、shader側の修飾子による指定でraster_order_groupを利用することができます. こちらのApple開発者ページよりコードを引用します.
fragment void blend(texture2d<float, access::read_write>
out[[texture(0), raster_order_group(0)]]) {
float4 newColor = 0.5f;
// the GPU now waits on first access to raster ordered memory
float4 oldColor = out.read(position);
float4 blended = someCustomBlendingFunction(newColor, oldColor);
out.write(blended, position);
}
なおtextureの修飾子にはwriteが必要になりますが、読み込み時に用いることができる .sample() に相当するピクセル間をサブサンプリングしてくれるようなfunctionは、書き込みにおいては(多分)ありません. したがって座標値を正しく指定してwriteする必要がありそうです.
実装における注意点
CPU側の設定
colorAttachmentの設定
_viewRenderPassDescriptor = [MTLRenderPassDescriptor new]; _viewRenderPassDescriptor.colorAttachments[AAPLRenderTargetAlbedo].loadAction = MTLLoadActionDontCare;
_viewRenderPassDescriptor.colorAttachments[AAPLRenderTargetAlbedo].storeAction = MTLStoreActionDontCare;
_viewRenderPassDescriptor.colorAttachments[AAPLRenderTargetNormal].loadAction = MTLLoadActionDontCare;
_viewRenderPassDescriptor.colorAttachments[AAPLRenderTargetNormal].storeAction = MTLStoreActionDontCare;
_viewRenderPassDescriptor.colorAttachments[AAPLRenderTargetDepth].loadAction = MTLLoadActionDontCare;
_viewRenderPassDescriptor.colorAttachments[AAPLRenderTargetDepth].storeAction = MTLStoreActionDontCare;
colorAttachmentのパラメータとして、storeActionにはMTLStoreActionDontCareを指定します. loadActionにも同じものを指定しており、これはraster_order_groupを使用してもしなくても変わりません.
MTLTextureの設定
MTLTextureDescriptor *GBufferTextureDesc = [MTLTextureDescriptor texture2DDescriptorWithPixelFormat:MTLPixelFormatRGBA8Unorm_sRGB width:size.width height:size.height mipmapped:NO];
GBufferTextureDesc.textureType = MTLTextureType2D;
GBufferTextureDesc.usage |= MTLTextureUsageRenderTarget;
GBufferTextureDesc.storageMode = storageMode; // !ここは MTLStorageModeMemoryless を指定!
Raster Order Groupの書き込み用MTLTextureの生成において、textureDescriptorには .memorylessを指定する必要があるようです. memorylessはCPU側のメモリを使わないという意味らしい.
ループ途中のtexture読み込み時の注意
Raster Order Groupを使用する際の最大の注意点と言っても良いかもしれません. 実はRaster Order Groupは非常に使いにくい一面があります. ループ途中のtextureはkernel計算等で必要な周囲の画素を読み込むことが (`20/May時点で) できません.
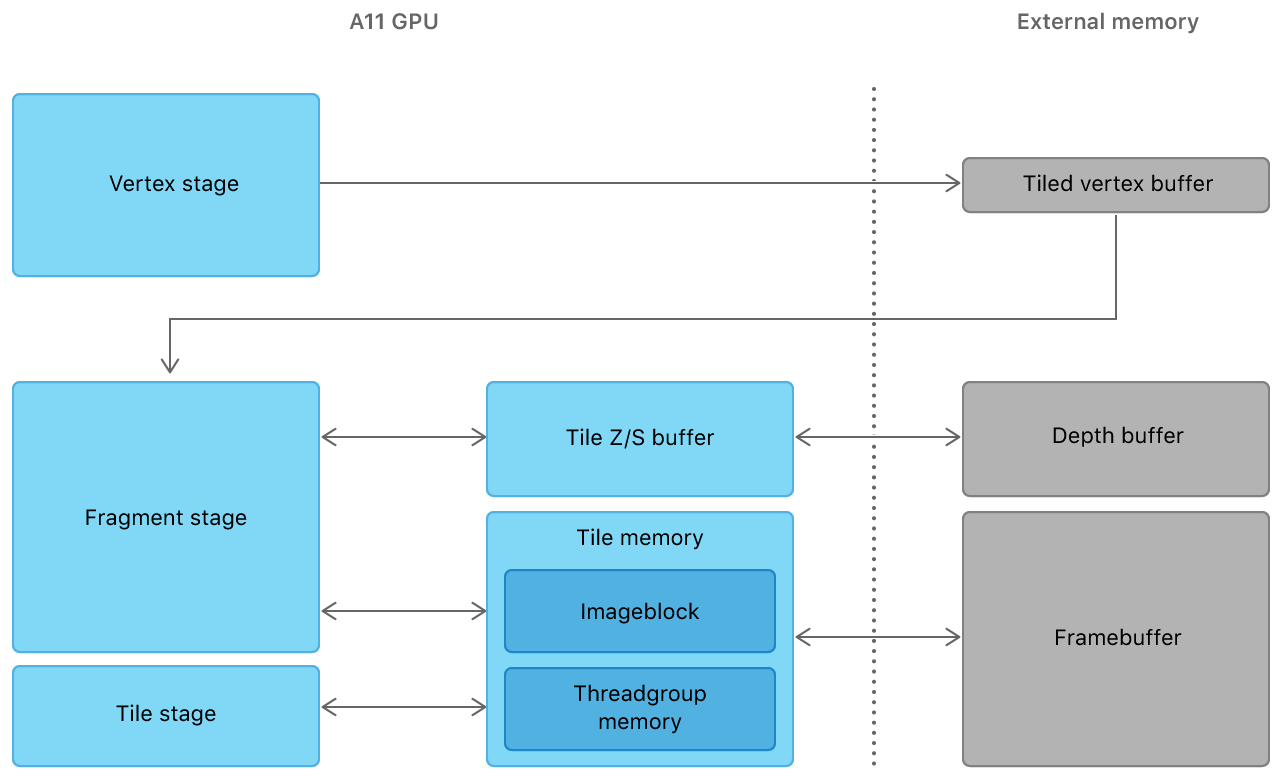
これはraster_order_groupループ途中のtextureはGPUの "Tile Memory" という仕組みを活用する一時メモリ領域に格納されるからです. Tile Memoryは、画素を一定サイズのブロックに分けてGPU描画を効率化する仕組みであり、どのメーカーのGPUでもよく使われる類の工夫のようです.
各タイルの描画は非同期であり、早く計算が完了したら随時次のタイルの計算に移行します. すなわちraster_order_groupのループ計算はタイル単位で非同期であることに気を付けねばなりません. この非同期計算を所謂awaitするような機能は、筆者がざっと探したところありませんでした.
(ただしMetalにはNeural Networkを効率化する機能が多数実装されており、kernel計算をループで同期的に処理する手段も用意されているはずです. これについてはいずれ調べてみたいと思います.)
おわりに
いかがでしたでしょうか?
ご参考になれば幸いです!
改善方法やご意見などあれば、どしどしコメント下さい!