0.はじめに
時には数百行もあるようなデータフレームを扱うことがあります。
しかも、そのうち必要なデータは一部でしかない、というのはよくあることです。
必要なデータだけ取り出せたらとても便利ですよね。
そんな大きなデータを扱うとき以外にも、グループごとに平均値を計算したり、t検定をかけたりするときにも抽出作業が必要になったりします。
今回はデータフレームから必要なデータを取り出す作業をやってみたいと思います。
【前回の記事はこちら】
0-1. 初めて登場する関数・演算子
subset(データフレーム名,条件)- データフレームから条件を満たすデータを抽出します。
- A
&B - AかつB
- A
|B - AまたはB
1. 前回までの復習と前準備
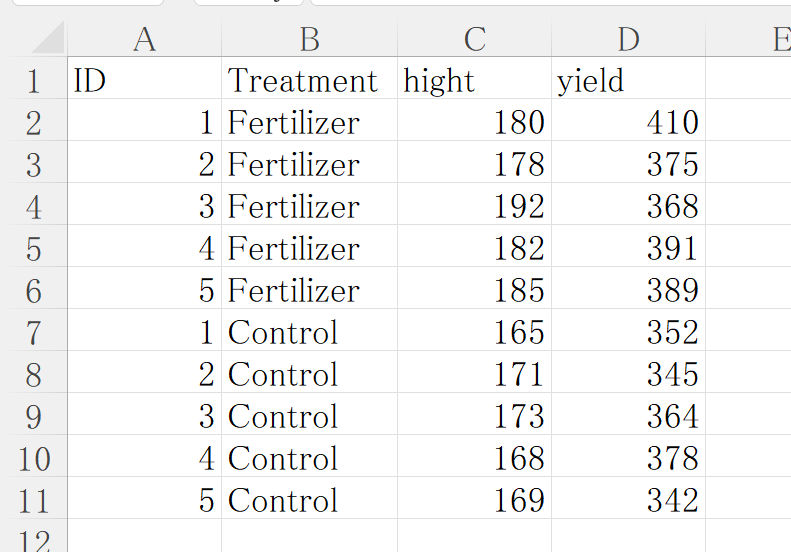
抽出は前回の練習データをちょっとパワーアップさせた練習データを使ってやってみましょう。前回はデータ項目が背丈だけでしたが今回は収量を追加しました。
Excelからのデータの読み込みの復習を兼ねて、よろしければマネして打ち込んで読み込ませてみてください。
# ワーキングディレクトリの設定
> setwd("C:/Users/Surku/Desktop/R")
# データの読み込み
> df<-read.table("トウモロコシ.csv",header = TRUE,sep=",")
> df
ID Treatment hight yield
1 1 Fertilizer 180 410
2 2 Fertilizer 178 375
3 3 Fertilizer 192 368
4 4 Fertilizer 182 391
5 5 Fertilizer 185 389
6 1 Control 165 352
7 2 Control 171 345
8 3 Control 173 364
9 4 Control 168 378
10 5 Control 169 342
このデータについておさらいしますと、トウモロコシを肥料あり区となし区で育て、1区5株、測定項目は背丈と収量という架空実験のデータです。
データフレームには2列目に処理(肥料があるかないか)、3列目に背丈のデータが入っています。
特に2列目のTreatmentは背丈や収量のデータがFertilizerなのかControlなのかのグループを指定する重要な列で、統計用語でいえば要因に当たります。
※要因って何だっけ?な人は第1回へ
せっかくなので、2列目のデータ型をfactorにしておきましょう。
これから行う抽出や平均値の計算のためにmustというわけではないのですが、ゆくゆく必要になるのでやっておきます。
流れは、
1.データフレームの2列目だけを取り出し(第3回で登場)
2.factorに変換し(第1回で登場)
3.再度データフレームに代入し上書きする
の3段階です。
# 2列目だけ取り出す
> df[,2]
[1] "Fertilizer" "Fertilizer" "Fertilizer" "Fertilizer" "Fertilizer"
[6] "Control" "Control" "Control" "Control" "Control"
# factorに変換
> as.factor(df[,2])
[1] Fertilizer Fertilizer Fertilizer Fertilizer Fertilizer Control
[7] Control Control Control Control
Levels: Control Fertilizer
# 代入し上書き
> df[,2]<-as.factor(df[,2])
# ほんとにfactorか確認
> class(df[,2])
[1] "factor"
2. subset()で抽出
抽出はsubset()関数を用いて行います。第1引数にデータフレームの変数名を、第2引数に条件を指定すると、条件を満たす行のみ抽出することができます。
第1引数には先ほど読み込んだdfを指定します。第2因数にいろいろな条件を入れて試してみましょう。
2-1. 完全に一致するものを抽出
TreatmentがControlなものだけを抽出してみましょう。
完全に一致することを示す演算子は==でした。
※忘れてしまった人は第2回へ
条件を「dfの2列目がControlと等しい」と指定してあげると、Fertilizerがすべて除外されてControlだけになります。
> subset(df,df[,2]=="Control")
ID Treatment height yield
6 1 Control 165 352
7 2 Control 171 345
8 3 Control 173 364
9 4 Control 168 378
10 5 Control 169 342
2-2. 大小比較で抽出
数字の大小で抽出することも可能です。例えば3列目のhightが180より大きいことを示すには、「より大きい」を表す>を使います。
> subset(df,df[,3]>180)
ID Treatment hight yield
3 3 Fertilizer 192 368
4 4 Fertilizer 182 391
5 5 Fertilizer 185 389
「以下」を表すためには、イコールを加えた<=を用います。次は4列目のyieldが375以下を抽出してみます。
> subset(df,df[,4]<=375)
ID Treatment height yield
2 2 Fertilizer 178 375
3 3 Fertilizer 192 368
6 1 Control 165 352
7 2 Control 171 345
8 3 Control 173 364
10 5 Control 169 342
2-3. 複数の条件指定で抽出
単一の条件ではなく、いくつか条件を組み合わせたいときがしばしば生じます。
かつを表すには&を、またはを表すには|を用います。
または、の演算子のキーがどこにあるのかわかりにくいのですが、Backspaceキーのとなりにいるので確認してみてください。
# hightが170より大きいかつyieldが350より大きい
> subset(df,df[,3]>170&df[,4]>350)
ID Treatment height yield
1 1 Fertilizer 180 410
2 2 Fertilizer 178 375
3 3 Fertilizer 192 368
4 4 Fertilizer 182 391
5 5 Fertilizer 185 389
8 3 Control 173 364
# TreatmentがFertilizerまたはyieldが350より大きい
> subset(df,df[,2]=="Fertilizer"|df[,4]>350)
ID Treatment height yield
1 1 Fertilizer 180 410
2 2 Fertilizer 178 375
3 3 Fertilizer 192 368
4 4 Fertilizer 182 391
5 5 Fertilizer 185 389
6 1 Control 165 352
8 3 Control 173 364
9 4 Control 168 378
3. 次回