もくじ
本記事について
RMSLEについて図的にイメージする。
KaggleのBike Sharing Demandに関する作成記事の補足で記載した。
Kaggleのコンペに挑戦したところ、評価値がRMSLEであった。
恥ずかしながらRMSLEについては聞いたことがなかった。
機械学習モデル精度の目標値を定めたいが、「RMSLE = c なら精度はどの程度」というRMSLE値と精度との結びつけができなかった。
ウェブで調べてもRMSLE値については定性的な記載があるのみであった。
基礎的なところなのでもう少し理解したいと思い記事を作成した。
Kaggleコンペの本編は以下リンク。
https://qiita.com/SumMae/items/f0f221735f94c06c609e
RMSLE
RMSLE = 「Root Mean Squaered Logarithmic Error」の略。
RMSLEの式、概要
RMSLE \ = \ \sqrt{\frac{1}{n}\sum^n_{i=1}\Bigl(log (p_i+1) - log(a_i +1)\Bigr)^2}
- n : データ数
- $p_i$: 予測値
- $a_i$: 真値(実際の値、観測値)
- $log$: 自然対数
RMSEの2乗の中身がルートになったもの。
予測値や真値が0のときにlog(0)は定義できないので、logの中身に1予め1を足している、というイメージ。
一方、この1の項のせいで単純な比率にならない感があり嫌な感じ。
$p_i$、$a_i$と、1の大きさの比率に依ってきそう。
式を眺めていると「傾きっぽいな」という気がする。
詳細は追って記載。
対比:RMSE
良く知られているものから考えて比較する。
RMSE = 「Root Mean Squaered Error」の略。
RMSLEのlogじゃない版。
誤差の基本。
RMSE \ = \ \sqrt{\frac{1}{n}\sum^n_{i=1}\Bigl(p_i - a_i \Bigr)^2}
- n : データ数
- $p_i$: 予測値
- $a_i$: 真値(実際の値、観測値)
式から分かる通り、残差二乗和の平均の平方根。
「良く知られている」と述べたが、
分散を求める際、類似の式が出てくる(分散の場合、$a_i$が平均値に置き換わる)。
物理実験や交流を扱う電気、音・振動分野でよく使う(RMSの名で、理論値または平均値と実験値の残差2乗和の平均として)。
RMSEの図的イメージ
「RMSEは切片」、というイメージ。
横軸に$a_i$(真値)、縦軸に$p_i$(予測値)を取ってプロットするとイメージしやすい。
真値と予測値が一致するとき、傾き1、切片0の直線を描く(図中の赤実線)。
誤差があるとき、その差は図中の赤点線として表現される。

式を見て考えてみる。
RMSE \ = \ \sqrt{\frac{1}{n}\sum^n_{i=1}\Bigl(p_i - a_i \Bigr)^2}
式を日本語に翻訳してみる。
1点ずつに分けて考えると、各点iに於ける$(p_i-a_i)$が上の図の縦赤点線。
この差の値を2乗すると、$(p_i-a_i)^2$。
全点に対して考えて、これの総和が $\sum^n_{i=1}(p_i - a_i)^2$ 、
点の総数で割る(=平均を取る)と $\frac{1}{n}\sum^n_{i=1}(p_i - a_i)^2$ 、
平方根を取ることで2乗した分の次元を元に戻すと、$\sqrt{\frac{1}{n}\sum^n_{i=1}(p_i - a_i )^2} = RMSE$ 。
ばらつき具合を評価している感じが分かる。
RMSがある数cに収まる点はどういう点群か考える。
\begin{align}
\sqrt{\frac{1}{n}\sum^n_{i=1}(p_i - a_i)^2} &= c \\
\frac{1}{n}\sum^n_{i=1}(p_i - a_i)^2 &= c^2 \\
\sum^n_{i=1}(p_i - a_i)^2 &= n*c^2
\end{align}
乱暴に言うと、「$(p_i-a_i)^2$ をn個足したもの」と、「$c^2$をn個足したもの」が等しいときにRMSE=cとなる。
つまり、平均して$(p_i-a_i)^2$ が$c^2$に等しいというのが「RMSE = c」の目安。
より簡略化したイメージで符号を考慮しない場合、$(p_i-a_i)$ が$c$に等しい、となる。
(実際には各点のバラつきを含めて2乗値を平均した結果が$c^2$に等しい、ということなので厳密さに欠けるが、イメージのためご容赦願いたい)
横軸を$a_i$、縦軸を$p_i$に取った図を描く。
赤点線を$(p_i-a_i)^2 = c^2$の線とする。
バラつきの平均が赤塗のエリア内に収まれば$RMSE \leqq c$となる。
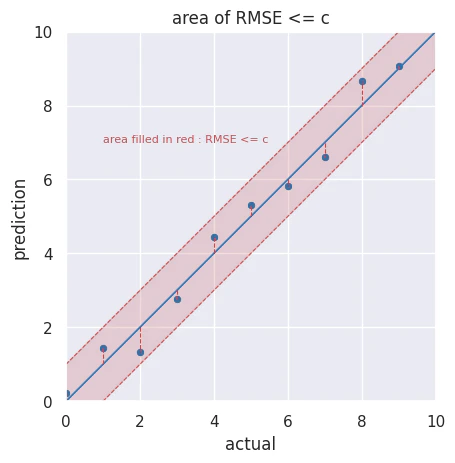
「RMSEは切片」、というイメージ。
目標設定で「RMSEがc以下を目指す」という場合、おおよそのイメージとして「予測値 vs 真値」の散布図が平均して切片が±c、傾きが1の領域内に集まればよいこととなる。
RMSLEの図的イメージ
本題に戻る。
「RMSLEは傾き(角度)」、というイメージ。
式変形、log同士の引き算はlog内の割り算に相当、というところから始める。
RMSLEが或る値cになるとする。
RMSLE \ = \ \sqrt{\frac{1}{n}\sum^n_{i=1}\Bigl(log (p_i+1) - log(a_i +1)\Bigr)^2} = c
\begin{align}
\frac{1}{n}\sum^n_{i=1}\Bigl(log(p_i + 1) - log(a_i +1)\Bigr)^2 &= c^2 \\
\sum^n_{i=1}\Bigl(log(p_i + 1) - log(a_i +1)\Bigr)^2 &= n*c^2 \\
\sum^n_{i=1}\Bigl(log\frac{p_i + 1}{a_i +1}\Bigr)^2 &= n*c^2 \\
\end{align}
ここでまたズルをして、n個の$\Bigl(log\frac{p_i + 1}{a_i +1}\Bigr)^2$の値とn個の$c^2$の値が等しい、と考えて$\sum$とnを取り外してしまう。
両辺2乗なのでこれも外す。
\begin{align}
log(p_i +1 / a_i +1) &= \pm c \\
\exp(\pm c) &= (p_i+1) / (a_i+1) \\
p_i &= (a_i +1)\exp(\pm c) - 1 \\
\end{align}
RMSLE値がc以下になるのは、$p_i$が平均して
(a_i +1)\exp(- c) - 1 \leqq p_i \leqq (a_i +1)\exp(+ c) - 1
の領域に分布するとき。
ただし、RMSLEはもともとlogの中身が$a_i +1$であったので、真数条件より$a_i + 1 >0$という条件が付く。
RMSEの図的イメージでも行ったように、今回も横軸を真値($a_i$)、縦軸を予測値($p_i$)として図を描く。
横軸が$a_i$なので、切片が$exp(\pm c) -1$で、傾きが定数$\exp(\pm c)$の2本の直線が描ける。
($(a_i +1)\exp(\pm c) - 1$ を展開して、 $a_i*\exp(\pm c) + \exp(\pm c) +1$)
この2本の直線の内側が$RMSLE \leqq c$の平均範囲の目安となる。
$|c|\leqq1$としたときの図を描く。

「RMSLEは傾き(角度)」、というイメージ。
ウェブで「RMSLE」検索すると出てくるキーワードが数値的に理解できる。
- 「比率で見るため、目的変数の取り得る範囲が広い場合に有効」 → 確かに、傾き(角度)で見ているので比率であり差分ではない
- 「予測値が低い場合に大きめのペナルティを課す」 → 例えば図の$a_i = 200$の値を見ると、マイナス側誤差は-127(-63%)程度、プラス側誤差は+345(+171%)となり、プラス側の許容が大きい
$a_i=200$のときに$\pm x$の誤差が乗った場合のRMSLE値を図示しておく。

青線は「200+誤差」、オレンジ色線は「200-誤差」のときのRMSLE値。
マイナス側に誤差が乗ったほうがRMSLE値は大きくなる(ペナルティを大きく課す)。
目標としてRMSLE値をどの値にしようか?というのは角度を考えることになるのだが、なんだか分かりにくい。
「プラス側の誤差を30%程度で」、と考えると、$p_i = a_i * 1.3$。
a_i*1.3$ = $(a_i +1)\exp(+ c) - 1 となるなので、
\begin{align}
(a_i +1)\exp(+ c) - 1 &= a_i*1.3 \\
\exp(+c) = \frac{a_i*1.3+1}{a_i+1} \\
c=log(\frac{a_i*1.3+1}{a_i+1}) \\
\end{align}
+1の項があるせいで若干$a_i$に依ってしまう。
$a_i$が1より十分大きいと考えて+1を無視してしまうと、
\begin{align}
c &= log(\frac{a_i*1.3+1}{a_i+1}) \\
&\sim log(\frac{a_i*1.3}{a_i}) \\
&= log(1.3) \\
&\fallingdotseq 0.262
\end{align}
マイナス側30%とすると、同様にして
\begin{align}
c &= log(\frac{a_i*0.7+1}{a_i+1}) \\
c &\sim -log(\frac{a_i*0.7}{a_i}) \\
&= -log(0.7) \\
&\fallingdotseq 0.357
\end{align}
プラス側30%の誤差でRMSLE値は約0.262。
マイナス側30%の誤差でRMSLE値は約0.357。
KaggleのBike Sharing Demandにて、1位のスコアは0.33756。
プラス側目安+40%、マイナス側目安-30%。
あまり精度良くないように思える。
ちょっと予測の難しい案件の模様。
その理由も具体的にBike Sharing Demandのデータを分析していると理解できる。
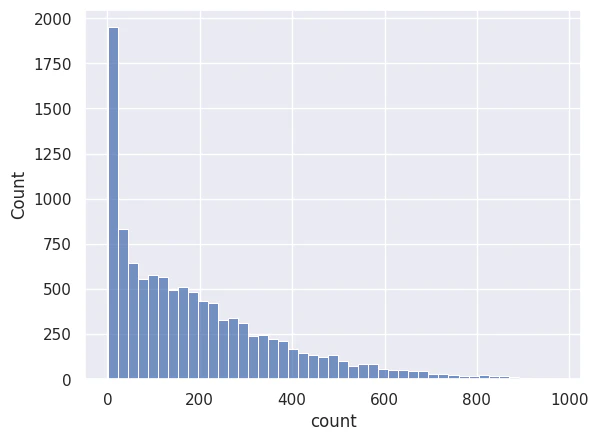
ゼロ付近に値が集中している為、RMSLEでは±1程度の誤差が敏感に値を悪くする。
以下のヒストグラムは、当該コンペの目的変数「count」の分布。
次の章では、値が小さい領域でのRMSLE値について追記することにする。
真値の小さいエリアでペナルティ大
比率で見ている故のこと。
真値が1の個所で予測が1ズレると、RMSLEの値は2倍の誤差として評価される。
図的に見てみる。
横軸に真値を取り、縦軸に$(log(pred.+1) - log(actual + 1))^2$値(RMSLE算出の為の、各点の値)を取る。
予測値が真値から或る量の誤差を持つときのグラフを描く。
「或る量の誤差」を色分けして複数表示する。
- 青 :予測値(pred.)が実際の値(actual)より1小さい場合
- 橙 :予測値(pred.)が実際の値(actual)より3小さい場合
- 緑 : 予測値(pred.)が実際の値(actual)より5小さい場合
- 赤 : 予測値(pred.)が実際の値(actual)より30%小さい場合
- 紫 : 予測値(pred.)が実際の値(actual)より30%大きい場合
横軸:actual値、縦軸:$(log(pred.+1) - log(actual + 1))^2$値
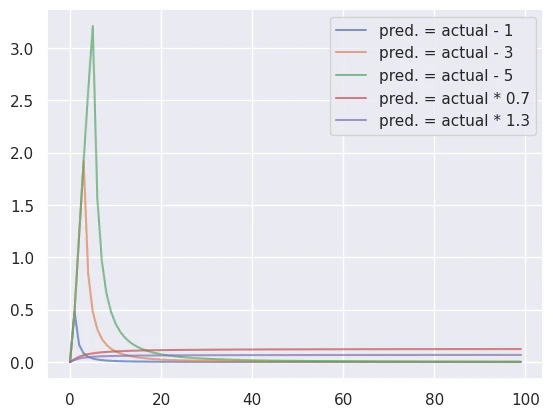
ただし、RMSLEではlogの中身が0より大きいという制約があるので、0付近の値は値無しの扱いとなる。
グラフ左端の最初の立ち上がりから有効な値と見ていただきたい。
真値の小さい領域(横軸<10のあたり)で値が1や2ずれると、その点で$(log(pred.+1) - log(actual + 1))^2$ の誤差はかなり大きく評価されることになる。
少し話が飛躍してしまうが、予測モデル作成中にこの現象が感覚と異なったので紹介する。
モデル精度確認のために横軸に真値、縦軸に予測値をプロットして散布図を描いた。
真値=予測値ならy=xの直線に散布図が並ぶ。
誤差が大きいとy=xの直線から外れる。
バラつきの大きい結果を得たので、どの点でモデルが再現できていないかを知りたくなり、誤差の大きい点上位100個を赤く記した。
$(log(pred.+1) - log(actual + 1))^2$、top100を赤塗り
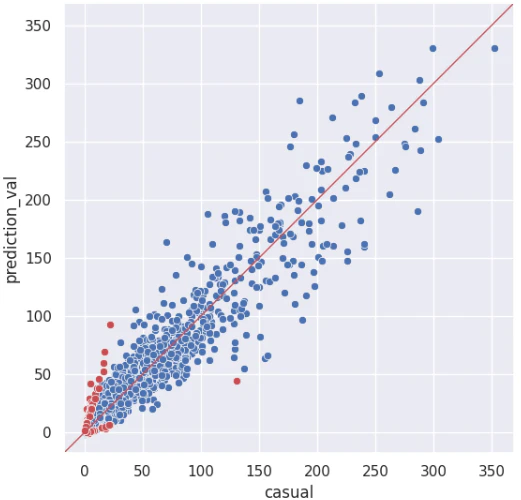
y=xを示す赤色直線から離れた(まばらに散らばった)点がいくつもあるのに、誤差量の大きい点は原点付近の、しかも赤色直線に比較的近いと視認してしまう点となった。
誤差をRMSLEではなくRMSEに準じて同様に誤差上位100点を赤くすると以下となった。
$(pred. - actual)^2$、top100を赤塗り

RMS準拠の$(pred. - actual)^2$値のほうが誤差を表示する際の感覚に近い。
RMSLEでは誤差の印象がかなり異なるので、モデルの評価値が悪い場合、またRMSLE値を改善したい場合にに考えるべきアプローチは物理実験での感覚と異なると知っておきたい。
一般に、物理実験時の誤差は「互いに独立であり且つ同一の正規分布に従う」という暗黙の前提のような認知バイアスを持っていると思う。
機械学習モデルでも最小二乗法を用いるものについては同様の前提を考慮していると認識している。
これらはRMSEに準拠した(切片的な)イメージでの誤差でありRMSLEに於ける角度的なイメージではない。
最尤度での推定を行うモデルでは、条件設定に確率分布を仮定するのでこの限りではないと思う。
結び
なかなか詳細を語られていない(ウェブ検索しても詳細は出てこない)RMSLE。
logが出てくると図的理解、絶対値の意味する量の理解に対して及び腰になりがちだが、なんとなくイメージはできた。
図的にイメージすると個性的であった。
- RMSLEはlogを取る為、比率で誤差を見る
- 予測値 vs 真値 の散布図に於いて、RMSEは切片的、RMSLEは傾き(角度)的なイメージ
- 真値より小さい側への予測でよりペナルティが大きい
- 真値が小さい領域での誤差がRMSLE値に大きく響く
- 図的にイメージすると一般的な感覚(少なくとも著者の持つ感覚)の誤差と性格が異なることが分かる