目的
- 対象:0,1の2値問題で、1が起こる確率を求める
「分類問題」の例でロジスティック回帰が登場する。
実際に求めているものは「1」の生起確率%。
その後、「50%以上なら1」、「50%未満なら0」等の閾値分けで分類している。
回帰直線の式を用いる。
回帰直線では求める値の範囲が$-\infty \lt y \lt \infty$。
一方、求めたいものは確率であり、その範囲は0~1。
この範囲のギャップを埋めるために、「ロジット変換」を行う。
ロジット変換後の変数に対して回帰を行い、これを逆変換「ロジスティック変換」することで確率を得る。
よって、「ロジスティック回帰」という名称。
ロジスティック回帰特徴
- 目的変数:0 or 1の2値(天気予報の晴れ・雨など)
- 出力:1となる「確率」を算出する(雨の降る確率など)
- リンク関数:ロジット関数
- 推定法:最尤推定法 (最小二乗法ではない)
- 尤度に用いる関数:ベルヌーイ分布 (パラメータ「p」は説明変数Xにより変動する)
ロジット変換について注力した記事をよく見かけるが、これは目的変数が[0,1]の2値であるのを回帰式に対応付けする「リンク関数」部の説明。
回帰全容を理解するには、尤度関数にベルヌーイ分布を仮定し、最尤推定によりパラメータ推定を行うこと、確率へ対応付けるためにロジスティック変換をすることなどの要素がある。
各操作間の関係を理解することで全体の理解をしたい。
学習方針
以下を順に理解する
- 最初に:結果を見てみる
- ===詳細===
- ロジット変換(リンク関数)
- 尤度関数(ベルヌーイ分布)
- 最尤推定
- 回帰式から計算する値を確認
- 計算していく
- 実際のコード(疑似データより)
最初に:結果を見てみる
以下のグラフの示す、「y=1である確率」を求める。
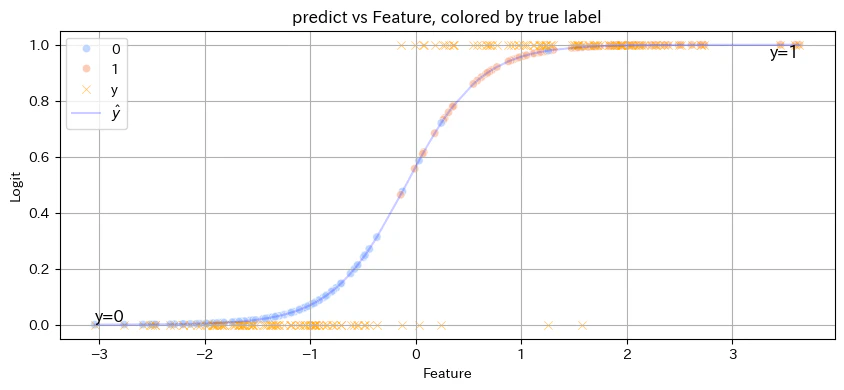
- y : 観測値。目的変数。0 or 1。例:天気予報で雨を1、晴れを0とする
- $\hat{y}$ : 予測値。y=1である確率。例:雨の降る確率
- Feature:説明変数の値を1次元へ単純化して表示
元データ:観測値 $y\in{ \{ 0,1\} }$ 、そのときの説明変数 X (Feature)
予測データ:y=1である確率 $\hat{y}$
このように、 y= 0 or 1 の2値を取る問題に対して、y=1 となる確率を予測するのがロジスティック回帰。
===詳細===
ロジット変換(リンク関数)
0 or 1 の2値問題に対して、説明変数から 1 である確率を予測したい。
これに回帰を用いたい。
線形結合、つまり以下の式で表現したい。
- 観測データの目的変数部:y
- 観測データの説明変数部:X
y = \beta X + b \tag{1}
しかし、観測値(目的変数)y は 0 or 1。
y \in \{{0, 1}\} \tag{2}
立式したが、y について整合性が取れない状況になる。
| yについて | 式(1) | 式(2) |
|---|---|---|
| 量 | 連続 | 2値 |
| 範囲 | $-\infty \lt y \lt \infty$ | 0 or 1 |
この不整合を、ひと工夫により解消する。
→ 「リンク関数」 を使用する(ロジット変換)。
発想1:予測値 y^ の連続化 → 確率化
予測する値を $\hat y$ とする。
まず、0 or 1 の2値だと回帰に落とし込みにくいので、$\hat y$ を連続値として扱うことを考える。
「1をとる確率$\hat y$%」を予測対象とすれば連続値として扱える。
つまり、推定する範囲を $ 0 \lt \hat y \lt 1$ とする。
| 観測データ(y) | 予測する値($\hat y$) | |
|---|---|---|
| 値 | $y \in{\{0,1\}} $ | $0 \lt \hat y \lt 1$ |
| 意味 | YesかNoかの2値 | Yesである確率 |
確率:$\hat y = P(Y=1)$
求める値を 「$p$」や「$\hat p$」と書く記事が多いようだが、
この後に続く操作中に、今求めている値は何なのか見失いやすく、かつベルヌーイ分布のパラメータ標記から、無意識にpは点推定される1つの値、という先入観を持ちやすく混乱をきたす。
予測対象であること、説明変数$x_i$により$\hat{y_i}$の値も変わることを強調するため、ここでは$p$は用いずに$\hat y$と書くことにする。
$\hat y$ は確率を示しており、$\hat y_i = P(y_i=1)$ である。
発想2: y^の範囲拡大
<目的・目標>
$\hat y$ は0~1の範囲を取る。
回帰式の範囲は$-\infty \lt \hat y^* \lt \infty$
変数変換により $-\infty \lt \hat y^* \lt \infty$ となる$\hat y^* $を作りたい。
そうすれば、回帰から $\hat y^* $ の予測値を得られ、
$\hat y^*$ を逆変換すれば 0~1 の確率を示す $\hat y$ が得られる。
<1.オッズ>
名前だけ紹介。
成功/失敗の比率を「オッズ」(odds)と呼ぶ。
odds = \frac{P(Y=1)}{P(Y=0)}
現在 P(Y=1) を $\hat y$ と表現しているので、
odds = \frac{\hat y}{1-\hat y}
$0 \lt \hat y \lt 1$ なので、以下のグラフがoddsの値になる。
範囲が $0 \lt odds \lt +\infty$ になっていることが分かる。
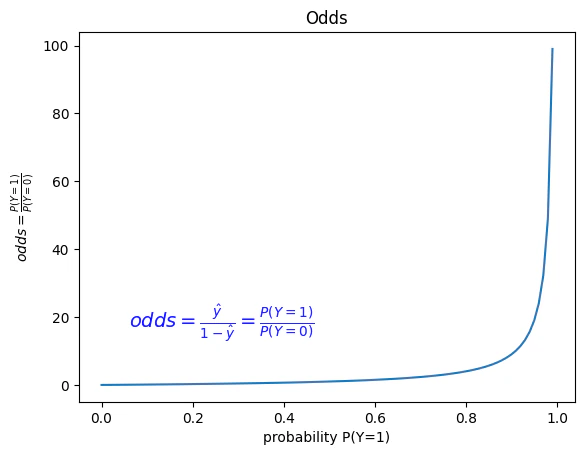
あとはマイナス側も$-\infty$まで拡張したい。
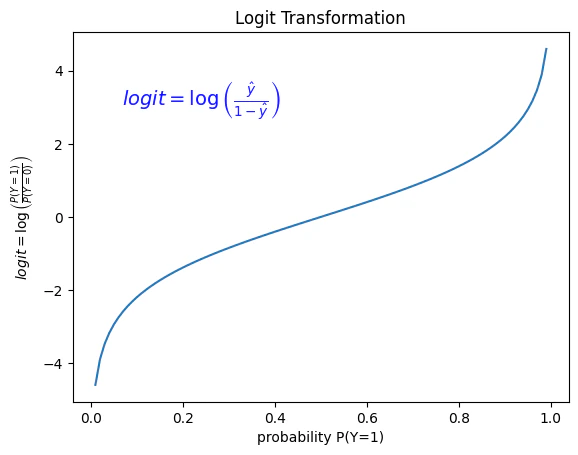
<2.ロジット変換>
オッズの対数を取る。
logit = log(odds) = log{\frac{\hat{y}}{1-\hat y}} = log{\frac{P(Y=1)}{P(Y=0)}}
変数yの対数オッズを取るこの操作を、「ロジット変換」 と呼ぶ。
ロジット変換した $\hat y$ を、$\hat y^* $と書いておく。
$\hat y^* $ は $-\infty \lt \hat y^* \lt \infty $ の範囲を取る。
| 観測データの目的変数(y) | 予測する値($\hat y$) | ロジット変換($\hat y^*$) | |
|---|---|---|---|
| 値 | $y \in{0,1} $ | $0 \lt \hat y \lt 1$ | $-\infty \lt \hat y^* \lt \infty$ |
| 意味 | YesかNoかの2値 | Yesを取る確率 | $\hat y$の対数オッズ |
ロジット変換まとめ
観測データを以下線形モデルで回帰計算したい。つまり、以下立式をしたい。
y = \beta X + b \tag{1}
しかし、観測値 y は 0 or 1 の2値
y \in {\{0, 1\}} \tag{2}
式(1)、式(2)でyの範囲が異なってしまうので、うまくモデル化する工夫をしたい。
ロジット変換して、 予測する「確率」 $\hat y$ を $log(\frac{\hat{y} }{1-\hat{y} }) $ とすることで、
予測対象の範囲が $-\infty \lt log(\frac{\hat{y} }{1-\hat{y}}) \lt \infty$ にできた。
このロジット変換した $\hat y$ を、 $\hat{y}^*$ とする。
各式の関係を整理。
\begin{align}
y &\in{\{0,1\}} \\
0 \lt &\hat{y} \lt 1 \\
-\infty \lt &\hat{y}^* \lt \infty \\
\\
\hat{y}^* &= \beta X + b \\
\hat y^* &= log\left(\frac{\hat{y}}{1-\hat{y}}\right)
\end{align}
回帰するのは、$\hat y^* = log(\frac{\hat{y}}{1-\hat{y}}) = \beta X + b $ の部分になる。
これで説明変数の回帰により確率を予測できる($ \hat{y}^*$ を逆変換(ロジスティック変換)すると確率になる)。
リンク関数
一般化線形回帰で使用される、「予測したい分布の期待値」と説明変数の線形和(線形予測子)とをつなげる関数。変数変換。
ロジスティック回帰でいうロジット変換に相当。
ロジスティック回帰で扱う事象はベルヌーイ分布に従い、ベルヌーイ分布の期待値はp(Y=1の確率)。
pと式(1)の右辺 $\beta X + b$ とを対応付けするために、リンク関数として「ロジット変換」を行った。
この変換(を行う関数、式)をリンク関数と呼ぶ。
尤度関数(ベルヌーイ分布)
観測データ(学習データ)をどのように処理するか。
線形回帰の場合には最小二乗法で解いた(各説明変数と目的変数yとの、残差二乗和を最小化する係数βを求める)。
純粋に観測データのみを扱い、他の考慮は無いので理解しやすい。
ロジスティック分布では、観測データ(目的変数)の確率分布がベルヌーイ分布に従うことを利用して、尤度関数を作成する。
観測データが「ベルヌーイ分布に従う」という仮定(命題上そうなる)から、ベルヌーイ分布の確率質量関数を使用する。
尤度については理解しにくい?ので、別記事にまとめた。
https://qiita.com/SumMae/items/f809b7163b8f85e3c7c6
尤度関数を$\mathcal{L}(\theta)$と書く。
(データYを得たうえでの、、、という条件付確率なので統計業界では$\mathcal{L}(\theta|Y)$と書くこともあり、データ分析業界では逆に$P(Y|\theta)$と書く。)
今回対象としている$y\in{\{0,1\}}$のデータをn回観測、各観測値を$y_i$として、$Y=\{y_1,y_2,\dots y_n\}$と表現する。
尤度関数の作成。
n回の試行は互いに独立だとすると、尤度関数$L(\theta)$は事象各$y_i$が観測された同時確率と解釈できる。つまり、各観測値の生起確率$P(y_i)$の積で表現できる。
\begin{align}
\mathcal{L}(\theta) &= P(y_1) \times P(y_2) \times \dots P(y_n) \\\
\mathcal{L}(\theta) &= \prod_{i=1}^{n} P(y_i)
\end{align}
今対象としている事象は 0 or 1 の2択問題なのでベルヌーイ分布で記述できる。
ベルヌーイ分布:
f(k ; p) =p^k(1-p)^{(1-k)}
- p:1が出る確率
- 1-p:0が出る確率(pの排反事象)
- k:観測値{0,1}
kについては、観測値が0のとき(1-p)が、1のときにpが抽出されるように記述されたもの。
\begin{align}
&@k=1 : f(1;p) = p^1(1-p)^{1-1} = p \\
&@k=0 : f(0;p) = p^0(1-p)^{1-0} = 1-p
\end{align}
観測値に依ってf(p)の場合分けをする、という記述は面倒。
kを導入することで1つの式で表現できる。
ベルヌーイ分布の式が事象の発生確率を表す。
さて、n回の試行から定義した尤度関数$\mathcal{L}(\theta)$は、各生起確率の積で表現できるということであった。
\begin{align}
\mathcal{L}(\theta) &= P(y_1) \times P(y_2) \times \dots P(y_n) \\\
\mathcal{L}(\theta) &= \prod_{i=1}^{n} P(y_i)
\end{align}
ベルヌーイ分布の確率質量関数に対応させ、その関係を描く
\begin{align}
y_i&\in\{{0,1}\}
\\
f(k ; p) &= p^k(1-p)^{(1-k)} \\
\hat{y_i} & := p_i
\\
P(y_i) &= \hat{y_i}^{y_i}(1-\hat{y_i})^{(1-y_i)} \\
\rightarrow P(y_i) & =
\left\{
\begin{array}{ll}
\hat{y_i} & (y_i = 1) \\
1-\hat{y_i} & (y_i = 0)
\end{array}
\right.
\\
\mathcal{L}(\hat{y_i}) &= \prod_{i=1}^{n} P(y_i) = \prod_{i=1}^n \hat{y_i}^{y_i}(1-\hat{y_i})^{(1-y_i)}
\end{align}
尤度を最大化するために、$\mathcal{L}(\hat{y_i})$が最も大きくなる$\hat{y_i}$を求める。
最尤推定法の考え方である。
$\hat{y}$ は、説明変数$X_i$ によりその値が変わるので、i番目のデータに於いて$\hat{y_i}$となる。
尤度関数は実観測値の羅列なので、「各$\hat{y_i}$を観測した」と理解しても良い。
ベルヌーイ分布の例で挙げられる「偏ったコインの表の生起確率$p$」の試行では、i番目のデータでもj番目のデータでもパラメータは共通の$p$となる。
最尤推定
ベルヌーイ分布を仮定し、観測値がi.i.dな試行の同時確率であると考えると、以下のように尤度関数を定められる。
\mathcal{L} (\hat{y_i}) = \prod_{i=1}^n \hat{y_i}^{y_i}(1-\hat{y})^{1-y_i}
この$L(\hat{y})$を最大にする$\hat{y}$を推定する。
最終的に求める値は、$L(\hat{y})$を最大にする$\hat{y_i}$を与える$\beta$、b。
最小二乗法適用は?
最小二乗法は実験でよく使われ馴染みがあるが、今回の系で最小二乗法は使えるか?
「残差」は、何を対象にするか?
$\hat {y_i} - y_i$ : 予想確率と事象との差 が考えられる。
これは計算は可能であるが、最小二乗法の対象とする前提、「残差(誤差)が正規分布に従う」、「残差(誤差)のバラつきが一定である」という前提から逸脱する。
これより、最小二乗法が適しておらず、信頼性の高い(理論に裏付けられた)推定が行えない。
よって、最尤推定法を使用する。
対数尤度関数
「尤度関数の最大化 = 微分して0の値を求める」という操作となる。
これは最小二乗法の発想と同様。
また、尤度関数の自然対数を取った「対数尤度関数」を最大化することと尤度関数の最大化は同じ操作であり、対数尤度の微分=0でも求めることができる。
尤度関数のグラフが3次以上の高次の曲線である場合には大域解でなく局所解である可能性はあるが、線形モデルや指数型分布の場合には対数尤度関数が凸関数となる為、微分=0を大域解と考えてよい。
複合型分布の場合はその限りでない(らしい?)ので注意。
以下の尤度関数の計算はべき乗・次数が多すぎて計算が難儀。
\mathcal{L} (\hat{y_i}) = \prod_{i=1}^n \hat{y_i}^{y_i}(1-\hat{y_i})^{1-y_i}
対数をとると、logの内側の積はlogの和に分解できて簡単な形になる。
\begin{align}
\ell (\hat{y_i}) &= log \left(\mathcal{L} (\hat{y_i})\right) \\
&= log \left( \prod_{i=1}^n \hat{y_i}^{y_i}(1-\hat{y_i})^{1-y_i} \right) \\
&= \sum_{i=1}^n log \left( \hat{y_i}^{y_i}(1-\hat{y_i})^{1-y_i} \right) \\
&= \sum_{i=1}^n \left( y_ilog(\hat{y_i}) + (1-y_i)log(1-\hat{y_i}) \right)
\end{align}
これを微分して0になる値が最大。
ただ、一般に最大化問題より最小化問題の方が好まれるので、対数尤度にマイナスを付けた「負の対数尤度」を最小化する、という事にする。
計算手続き上は大きな意味はない。
負の対数尤度にすることで情報論との関連性(クロスエントロピーと等価になる)や、多くのソルバーの設計に対応できる、というのが目的。
負の対数尤度と情報量の関連
これは数式上で考えると、-log(P(X))*P(X)という「自身に自身の対数変換を掛ける」という意味の分からない計算で混乱する。
日本語に解釈しなおして考える方が理解しやすい。
情報量$I(X)$は、乱暴に言うと「P(X)の希少度」を数値化している($I(X)$が大きいとレア、小さいとありふれている)。
平均情報量(エントロピー)$H(P(X))$は情報量の期待値。つまり、今から行う試行により得られるであろう「希少度」の期待値。
試行結果が「だいたい予測できる」場合(得た結果が「妥当だね」と思える確率が高い)はエントロピーが小さい。
試行結果が「何が出るか予測できない」場合(何が出るか分からない=読めない=ありふれていない=希少)はエントロピーが大きい。
回帰式から計算する値を確認
最尤推定 → 負の対数尤度最小化 と辿った。
ここで、求めたいものは、回帰係数であった(回帰式中の$\beta$、b)。
結論から述べると、負の対数尤度関数$-\ell(\hat y)$を、$\beta$、bで偏微分して0になるような、$\beta$、b を求める。
回帰式から順に追っていく。
y = \beta X + b \tag{1}
各関係式を再度書く。
\begin{align}
y &\in{\{0,1\}} \\
0 \lt &\hat{y} \lt 1 \\
-\infty \lt &\hat{y}^* \lt \infty \\
\\
\hat{y}^* &= \beta X + b \\
\hat y^* &= log\left(\frac{\hat{y}}{1-\hat{y}}\right)
\end{align}
尤度関数は $\hat{y_i}$ に対して作成した。
今は、回帰問題を解きたい。
説明変数$X=\{x_1,x_2,\dots x_i, \dots, x_n\}$に対する確率に対応する回帰係数を求めることが目的。
回帰係数$\beta$、bと、尤度関数との関係に直す必要がある。
ロジット変換で回帰式を
log\left(\frac{\hat{y}}{1-\hat{y}}\right) = \beta X + b
としていた。
尤度関数は$\hat y$の式だったので、「$\hat{y} = \dots $」 の形に変形したい。
ロジット変換の逆変換をする操作となり、これをロジスティック変換と呼ぶ。
単純にlogを外して整理すればよい。
式変形していく。冗長だが、1つずつ書く。
\begin{align}
log\left(\frac{\hat{y}}{1-\hat{y}}\right) &= \beta X + b \\
\frac{\hat{y}}{1-\hat{y}} &= e^{\beta X + b} \\
\hat{y} &= ({1-\hat{y}})\cdot e^{\beta X + b} \\
(1+e^{\beta X + b})\cdot \hat{y} &= e^{\beta X + b} \\
\hat{y} &= \frac{e^{\beta X + b}}{1+e^{\beta X + b}} \\
\hat{y} &= \frac{1}{e^{-(\beta X + b)}+1} \\
\hat{y} &= \frac{1}{1+e^{-(\beta X + b)}} \\
\end{align}
なお、これはシグモイド関数になっている。
最尤推定するのは負の対数尤度関数の $\hat{y_i}$ に $\frac{1}{1+e^{-(\beta x_i + b)}}$ を代入して、尤度最大となるパラメータを求める。
負の対数尤度を再度表示。
\begin{align}
-\ell (\hat{y_i})
&= -log \left( \prod_{i=1}^n \hat{y_i}^{y_i}(1-\hat{y_i})^{1-y_i} \right) \\
&= -\sum_{i=1}^n \left( y_ilog(\hat{y_i}) + (1-y_i)log(1-\hat{y_i}) \right)
\end{align}
この$-\ell(\hat {y_i})$を微分して0になる$\beta$、bを求める。
計算していく(偏微分する)
まずは$\beta$について偏微分する。
合成関数の微分なので、簡単のため、今まで使用した文字式から整理すると簡単に計算できそう。
各文字式。
\begin{align}
-\ell (\hat{y_i}) &= -\sum_{i=1}^n \left( y_i log(\hat{y_i}) + (1-y_i)log(1-\hat{y_i}) \right) \\
\hat y &= \frac{1}{1+e^{-(\beta X + b)}} \left( = \frac{1}{1+e^{-\hat{y}^*}} \right)\\
\hat y^* &= \beta X + b
\end{align}
※尤度関数ではその性質から$\hat{y_i}$表記にした。他はサンプル集合(ベクトル)$X$で表現する都合上、$\hat y$で表記した。
次の式からは尤度関数を起点にするので、$\hat{y_i}$表記を用いる。
合成関数の微分:$\beta$、b のそれぞれで偏微分する。
$\beta$について。
\frac{\partial(- \ell(\hat{y_i}))}{ \partial \beta} = - \frac{\partial\ell(\hat{y_i})}{ \partial \hat{y_i}}
\frac{\partial \hat{y_i}}{\partial\hat{y_i}^*}
\frac{{\partial\hat{y_i}^*}}{\partial \beta}
1つずつ計算を書く。
\begin{align}
- \frac{\partial\ell(\hat{y_i})}{ \partial \hat{y_i}} &= \partial\left(
-\sum_{i=1}^n \left( y_i log(\hat{y_i}) + (1-y_i)log(1-\hat{y_i}) \right) \right) / \partial \hat{y_i}\\
&= -\sum_{i=1}^n \left( \frac{y_i}{\hat{y_i}} - \frac{1-y_i}{1- \hat{y_i}} \right) \\
&= - \sum_{i=1}^n\left( \frac{y_i(1-\hat{y_i}) - \hat{y_i}(1-y_i)}{\hat{y_i}(1-y_i)} \right) \\
&= - \sum_{i=1}^n \left( \frac{y_i - \hat{y_i}}{\hat{y_i}(1-y_i)} \right)
\\ \\ \\
\frac{\partial \hat{y_i}}{\partial\hat{y_i}^*} &= \partial\left( \frac{1}{1+e^{-\hat{y_i}^*}} \right) / \partial \hat{y_i}^* \\
&= \frac{e^{-\hat{y}^*}}{(1+e^{-\hat{y_i}^*})^2} \\
&= \frac{1}{1+e^{-\hat{y_i}^*}} \cdot \frac{e^{-\hat{y}^*}}{1+e^{-\hat{y_i}^*}} \\
&= \hat{y_i}(1-\hat{y_i}) \\
\\ \\ \\
\frac{{\partial\hat{y_i}^*}}{\partial \beta} &= \partial \left( \beta x_i + b\right) / \partial \beta \\
&= x_i
\end{align}
よって、偏微分をまとめると、
\begin{align}
\frac{\partial(- \ell(\hat{y_i}))}{ \partial \beta} &=
- \frac{\partial\ell(\hat{y_i})}{ \partial \hat{y_i}}
\frac{\partial \hat{y_i}}{\partial\hat{y_i}^*}
\frac{{\partial\hat{y_i}^*}}{\partial \beta}
\\
&= - \sum_{i=1}^n \left( \frac{y_i - \hat{y_i}}{\hat{y_i}(1-y_i)} \right)
\cdot
\hat{y_i}(1-\hat{y_i})
\cdot
x_i
\\
&= -\sum_{i=1}^n (y_i - \hat{y_i}) \cdot x_i
\end{align}
bについては、最後の項が
\begin{align}
\frac{{\partial\hat{y_i}^*}}{\partial b} &= \partial \left( \beta X + b\right) / \partial b \\
&= 1
\end{align}
となるだけで他は同じ。
よって、
\begin{align}
\frac{\partial(- \ell(\hat{y_i}))}{ \partial b} &=
- \frac{\partial\ell(\hat{y_i})}{ \partial \hat{y_i}}
\frac{\partial \hat{y_i}}{\partial\hat{y_i}^*}
\frac{{\partial\hat{y_i}^*}}{\partial b}
\\
&= -\sum_{i=1}^n (y_i - \hat{y_i})
\end{align}
微分して0になる値を求める
偏微分が0になる値を求めれば最尤推定が完了する、というのが主題であった。
最右辺に=0を代入しつつ、偏微分の結果を再度記載する。
\begin{align}
\frac{\partial(- \ell(\hat{y_i}))}{ \partial \beta} &=
- \frac{\partial\ell(\hat{y_i})}{ \partial \hat{y_i}}
\frac{\partial \hat{y_i}}{\partial\hat{y_i}^*}
\frac{{\partial\hat{y_i}^*}}{\partial \beta}
\\
&= -\sum_{i=1}^n (y_i - \hat{y_i}) \cdot x_i = 0
\\\\\\
\frac{\partial(- \ell(\hat{y_i}))}{ \partial b} &=
- \frac{\partial\ell(\hat{y_i})}{ \partial \hat{y_i}}
\frac{\partial \hat{y_i}}{\partial\hat{y_i}^*}
\frac{{\partial\hat{y_i}^*}}{\partial b}
\\
&= -\sum_{i=1}^n (y_i - \hat{y_i}) = 0
\end{align}
$\beta$:
\begin{align}
-\sum_{i=1}^n (y_i - \hat{y_i}) \cdot x_i &= 0 \\
\sum_{i=1}^n \left(\frac{x_i}{1+e^{-(\beta x_i + b)}}\right) &= \sum_{i=1}^n x_iy_i \\
\end{align}
b:
\begin{align}
-\sum_{i=1}^n (y_i - \hat{y_i}) &= 0 \\
\sum_{i=1}^n \left(\frac{1}{1+e^{-(\beta x_i + b)}}\right) &= \sum_{i=1}^n y_i \\
\end{align}
これを同時に満たす $\beta$ 、b を求めるので、連立方程式を解くことになる。
が、非線形、非二次型、総和の方程式であり解析的に解くのは困難。
→ 数値的開放で解く(勾配降下法など、ソルバーで解く)。
ここでは、勾配降下法に関する説明は省略する。
具体的計算がここで途切れるが、これにより$\beta$、b が求められる。
実際のコード(疑似データより)
scikit-learnにより、疑似データ作成およびロジスティック回帰を行う。
scikit-learnを使用すると、そのコード上でリンク関数もロジット変換も出てこない。
手軽に使用できてよい反面、勉強しないとロジスティック回帰で何が行われているか想像できない。
理解して使うといいことがあるかもしれない。
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
# データ生成
X, y = make_classification(n_samples=1000, n_features=1,
n_informative=1, n_redundant=0,
n_clusters_per_class=1, flip_y=0.03,
class_sep=1.5, random_state=42)
# 訓練・テストに分割
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2,
random_state=42)
# モデル学習
model = LogisticRegression()
model.fit(X_train, y_train)
# 予測確率と予測
# 線形式。範囲は±∞
logits = model.decision_function(X_test)
# 1の確率を取得
probs = model.predict_proba(X_test)[:, 1]
# 予測曲線
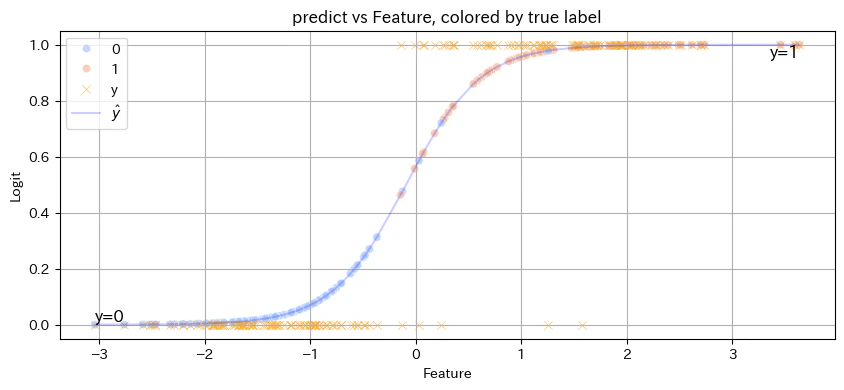
y_pred = model.predict(X_test)
# ① ロジット関数と正解ラベル
plt.figure(figsize=(10, 4))
#sns.scatterplot(x=X_test[:, 0], y=logits, hue=y_test, palette="coolwarm", alpha=0.7)
sns.scatterplot(x=X_test[:, 0], y=probs, hue=y_test, palette="coolwarm", alpha=0.7)
sns.scatterplot(x=X_test[:, 0], y=y_test,marker="x", color="orange",alpha=0.7, label="y")
plt.plot(sorted(X_test[:, 0]), sorted(probs), color="blue",alpha=0.2, label="$\hat{y}$")
plt.title("predict vs Feature, colored by true label")
plt.xlabel("Feature")
plt.ylabel("Logit")
plt.legend()
plt.grid(True)
# y=0とy=1のラベル
plt.text(X_test[:,0].min(), 0, 'y=0', fontsize=12, verticalalignment='bottom', horizontalalignment='left')
plt.text(X_test[:,0].max(), 1, 'y=1', fontsize=12, verticalalignment='top', horizontalalignment='right')
plt.show()
まとめ
- 2値分類問題を回帰により解く
- 予測値を確率$\hat y$とする
- リンク関数:ロジット変換$log\left( \frac{\hat y}{1-\hat y}\right)$により回帰式の範囲を $\pm \infty$にする
- ベルヌーイ分布より尤度関数を作成、最尤推定を行う
- 偏微分する際に確率 $\hat y = \dots$ にするべく、ロジスティック変換を行う($\hat y = \frac{1}{1+e^{-(\beta X + b)}}$)