Playwright
webの自動操作。
ブラウザはPlaywright内でChromiumなどをインストールして使用される。
以下を覚書として。
version:1.51.0
調査日:2025年5月
公式:https://playwright.dev/python/docs/intro
インストール
pip install playwright でplaywright本体をインストール
playwright install で、使用するブラウザをインストール。Chromium、FireFox、Webkitがインストールされる。
playwright install chromium でchromiumのみインストール可能。
各種オブジェクト
playwright_sync
本体、大元。
ここからブラウザ(browser)やページ(page)、ロケータ(locator)などを生成してweb操作する
with構文の使用が可能。
余談:一般に、classのメンバ関数に def __enter__(): , def __exit__(): を作成しておくとwith構文で使用が可能となる
withでの記述
from playwright.sync_api import sync_playwright
import time
with sync_playwright() as p:
# ブラウザ起動。headless=Booleanで可視化の有無を設定
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://www.google.com/")
page.wait_for_selector("#APjFqb", state="visible")
page.click("#APjFqb")
page.fill("#APjFqb", "playwright")
page.screenshot(path="screenshot.png")
page.press("#APjFqb", "Enter")
# 表示確認用に少しsleepを入れておく
time.sleep(2)
browser.close()
withを用いない場合は.start()から始めて、終了時に.stop()する。
from playwright.sync_api import sync_playwright
import time
# playwright オブジェクトの作成
p = sync_playwright().start()
# browserの生成
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://google.com/")
page.wait_for_selector("#APjFqb", state="visible")
page.click("#APjFqb")
page.fill("#APjFqb", "playwright")
page.screenshot(path="screenshot.png")
page.press("#APjFqb","Enter")
time.sleep(2)
# browserの停止
browser.close()
# playwrightのstop
p.stop()
browserオブジェクト
- ブラウザ実態(アプリケーション)
- 動作時の表示・非表示設定:「headless」
- pageオブジェクトを生成 → 2種類あり
- new_page():新規タブ作成(ログイン、クッキー共通)
- new_context():新規独立ブラウザ(ログイン、クッキーは共有しない)
以下、詳細。playwright_syncから生成する。
browser = p.chromium.launch(headless=False)
page = browser.new_page()
pageオブジェクトを生成。
page = browser.new_page() page = browser.new_context()
の2種類がある。
page = browser.new_page()
- 同じbrowserセッションを作成。ログインやクッキーは共通して使用される
page = browser.new_context()
- 新しい独立browserセッションを作成。ログインやクッキーは独立している
- プライベートモードのようなイメージ?
pageオブジェクト
- HTML中身を扱う
- ただし、全体的な内容であり、個別要素はlocatorオブジェクトが担う
- よく使うもの
-
page.goto("URL")でwebページを開く -
page.screenshot("file_path_and_name.png or .jpg")画面スクリーンショットを指定pathに保存
-
一応要素(element)へも直接アクセスできる(前述の例はpageからcomboboxにアクセスしている)が、
locatorオブジェクトでは自動でDOM表示、クリック可能になる等の待機を管理してくれるので、
要素にアクションを執る場合にはlocatorを使用した方が良い。
locatorオブジェクト
htmlの要素、pageオブジェクトから生成
-
locator = page.locator("#APjFqp"): CSSセレクタを使用するLow LevelなAPI -
locator = page.get_by_role("combobox", name="検索"): アクセシビリティを基準に取得
前述のコードをlocatorを使用したものに変更。前述のpageベースで実施していた個所はコメントアウトして表示しておく
from playwright.sync_api import sync_playwright
import time
# playwright オブジェクトの作成
p = sync_playwright().start()
# browserの生成
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://google.com/")
"""
page.wait_for_selector("#APjFqb", state="visible")
page.click("#APjFqb")
page.fill("#APjFqb", "playwright")
page.screenshot(path="screenshot.png")
page.press("#APjFqb", "Enter")
"""
locator_search_box = page.get_by_role("combobox", name="検索")
locator_search_box.fill("filling by locator ")
locator_search_box.press("Enter")
time.sleep(2)
# browserの停止
browser.close()
# playwrightのstop
p.stop()
要素の選択方法
page.fill("_select_element_", "text")
select_element 部の書き方(ルール)。
ブラウザからwebページのhtmlを調べて、対応する名称を書く。
| セレクタ先頭文字 | 意味 | 例 |
|---|---|---|
| # | ID | "#username" |
| . | class | ".form_input" |
| input[name=xxx] | input等の要素のうち、「name=xxx」属性を持つもの | "input[name='email']" |
✅ # → ID
✅ . → クラス
✅ [name=xxx] など、あるの属性を持つ要素で指定
| 取得方法 | 信頼性 | 速度 |
|---|---|---|
page.get_by_role("button", name="submit") |
要素の役割によるので、HTML構造に依らず長期的に信頼性が高く、フレームワーク間共通なので変更に強い | ブラウザのアクセシビリティツリーによる検索なのでCSSセレクターと同等かそれ以上に高速 |
page.get_by_test_id("submit-button") |
開発者の明示的な意図で設置されているので信頼性高い。一方、テスト目的のものなのでweb公開時にtest_idが削除されることがあり、test_id()に過度に期待できない | CSSセレクターと同等かそれ以上に高速 |
| page.locator("#id") | 一意の値を使用するので堅牢。HTML構造変更の影響を受けにくい(思想的な問題) | ブラウザはidをインデックス化して所持しているので非常に高速 |
| page.locator(".class") | クラスは一意でないので、何番目の要素か指定する(.first()、.last()、.nth(n))信頼性はやや劣る | 高速だが、複数ヒットする場合には影響を受ける |
| page.locator("//button[@id='submit']") | XPath。非推奨。構造変更に弱い | 全要素を走査して検索するため遅い |
読み込み待ち
ページのロード待ちを明示的に指定。
基本的にplaywrightでは自動で適切に待機していくれるので使用する必要はない。
動的なページでタイミングが合わないときにこれを検討するとよい。
以下、オプション引数の選択肢を " | " で区切って表示。
-
pageオブジェクト-
page.wait_for_load_state(state="load" | "domcontentloaded" | "networkidle")-
"load": デフォルト。 load イベント発火を待つ -
"domcontentloaded": DOMコンテンツのロード完了イベントを待つ -
"networkidle": 非推奨。500ミリ秒以上ネットワーク接続が無くなるまで待つ
-
-
page.wait_for_selector(state="attached" | "detached" | "visible" | "hidden" )- "attached" : 要素がDOMに追加されるまで待つ
- "detached" : 要素がDOMから削除されるまで待つ
- "visible" : 要素が画面上に表示されるまで待つ
- "hidden" : 要素が非表示になるまで待つ(visibleの逆)
-
-
locatorオブジェクト-
locator.wait_for(state= "attached" | "detached" | "visible" | "hidden")- オプション引数は
page.wait_for_selector()と同じ - 使い方 : 先にlocatorオブジェクトを作成、その要素オブジェクトに待機命令
locator = page.get_by_role("button", name="submit") locator.wait_for(state="visible")
- オプション引数は
-
codegen:自動生成
ターミナルで以下を実行
playwright codegen --browser=chromium https://www.google.com
対象URLのページが開き、操作が記録される
以下の図はマウスを検索ボックスに置いたときの図

操作すると、「Playwirght Inspector」window何にコードが生成される。
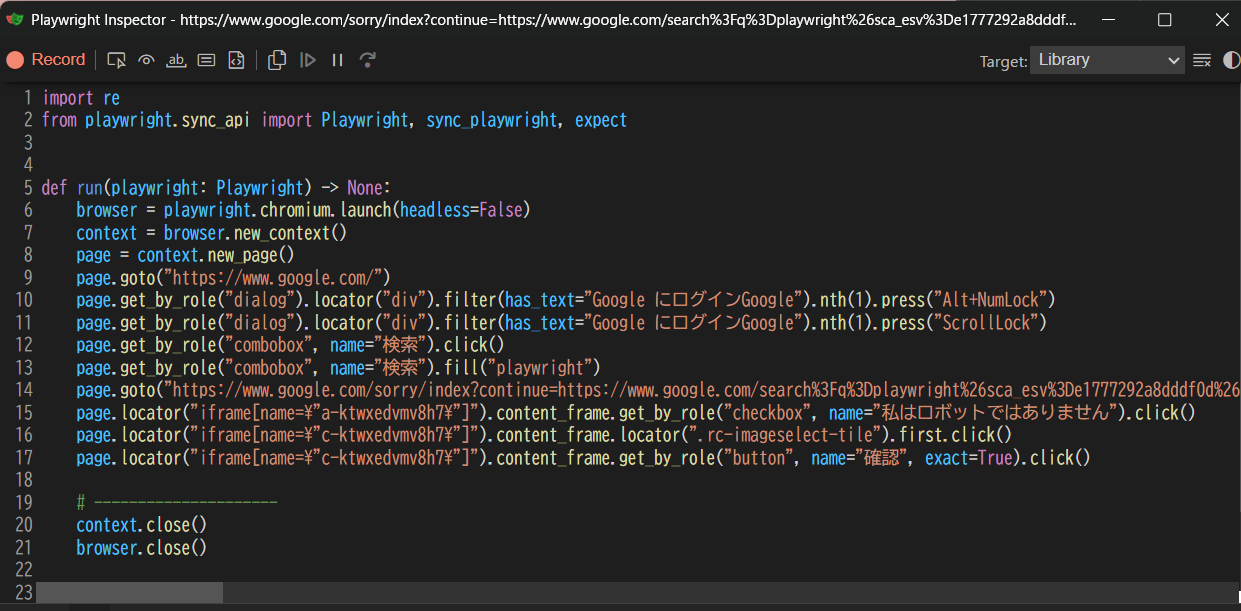
コードは言語設定可能
