はじめに
組み込みエンジニア2年目のすいばりです。
今回、リアルタイムにTwitterのワードクラウドをWebブラウザ上に表示するアプリを作りました。

当然開発で色々詰まりました。
同じこと目指している方に情報共有したいなと思って記事書きました。
読んで&使っていただけたら嬉しいです!
成果物の説明
アプリのシステム構成は以下の通りです。
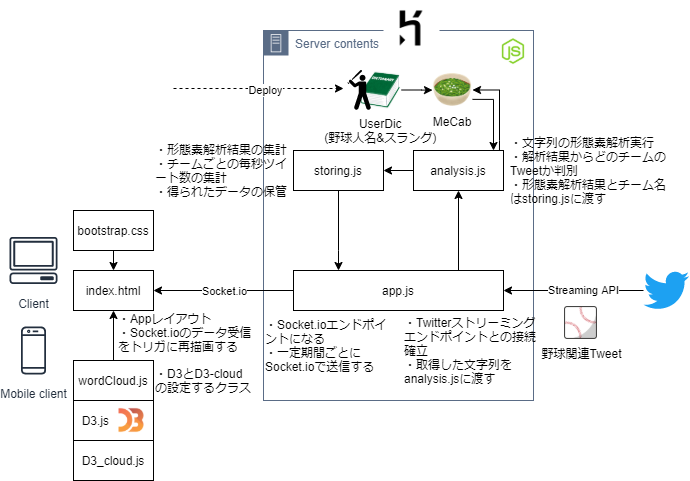
流れは大体以下です。
- Twitter filter streamでツイート収集
- MeCabで形態素解析
- 単語頻出数集計
- ブラウザでワードクラウド作る!
コード&機能詳細は、GitHubをご覧ください!
詰まったことリスト
- D3のバインディング設定が難しい
- heroku free planのslug sizeが限界
- MeCab辞書のherokuデプロイ方法が複雑
それぞれ説明します。
D3のバインディング設定
D3.jsはJavaScriptのグラフ描画用ライブラリです。
NPBライブクラウドではこのD3.jsと、D3-cloud.jsというD3.jsの機能を使ってワードクラウドを描画するラッパーライブラリを使用してます。
D3.jsにはバインディングという概念があります。
バインディングとは、DOM要素に対してデータを紐づけることです。
バインディングはDOM要素が存在しなくてもできます(XXX is not definedにならない!)。
この考え方がよくわからなくて詰まりました。
例えば以下のコード。
class wordCloud {
_draw(words) {
let cloud = d3.select('svg').select('g').selectAll('text').data(words); //wordsをtext要素に対してバインディングする
//中略
cloud.merge(cloud) // 全text要素(その時点でのあるなし問わない)に対しての操作
.style('fill', (d) => { return d.color })
//中略
}
_draw関数が最初に呼び出されるとき、まだtext要素は存在していません。
普通にDOM操作する感覚だと、not definedとか怒られるので違和感あると思います。
D3.jsは便利な分くせが強いので、そこに詰まりました。
heroku free planのslug size
herokuは無料から使えるレンタルサーバー(PaaS)です。
herokuの無料プランはデプロイできるサイズが500MBまでという制限があります。
NPBライブクラウドでは形態素解析ソフトのMeCabを使っているためサイズが大きいです。
最初、大体こんな感じでslug sizeオーバーしました。
| モジュール | サイズ |
|---|---|
| アプリ本体 | 10MB |
| Linuxbrew | 400MB |
| MeCab | 10MB |
| MeCab-ipadic | 50MB |
| MeCab新語辞書 | 400MB |
| 計 | 800MB↑ |
対策としては、MeCab新語辞書をやめて自作辞書を使用しました。
自作辞書は自分の過去記事を参考にWebスクレイピングで作成しました。(方法は下記の章)
それでもかつかつです。(確か490MBくらい)
MeCab辞書のherokuデプロイ
git経由して.MeCab設定ファイルmecabrcをherokuにデプロイします。
配置場所は ~/app/.mecabrc です。
注意点として、herokuのユーザhomeディレクトリのProcfileを使った方法は現在は使えません。
理由はこちら。
なのでこうして辞書ファイルを予めコンパイルしておいて一緒にデプロイするしかないみたいです。
おわりに
heroku上にwebアプリを作りました。そこで詰まった点をまとめたという話でした。
感想ですが、一番むずいのってモチベーションの維持かもしれないです。
このアプリは完全一方通行なので、誰がどのくらい見てくれてるとか、何が求められているとか、開発者の自分では把握できません…。
モチベーション維持やフィードバックの仕組みを考えておくのは趣味開発では大切かもって思いました。
ふわっとした記事になりましたが、以上です。
よいお年を!