JOINとリレーションを考えてみる
一対一の関係
1:1の説明と例
双方のレコードが1対1に対応していることを表すもの。
例えば、1つの商品は1つのserial番号しか持っていないとか、1人は1つの免許書しか持っていない。
一般的に1:1関係はテーブルのカラムとして表す。商品の例だと、「商品」テーブルにserial_numberというカラムを追加するだけで十分。
| id | seirial_number | product_name |
|---|---|---|
| 1 | 0020192449 | apple |
| 2 | 0038155728 | pen |
同じ考え方で、「人」というテーブルにdriving_licenseカラムを追加できる。
|id|person_name|height|country|driving_license_number
|:---:|:--:|:--:|:--:|:--:|:--:|
|1|Jose|190|Mexico|22193|
|2|Taro|160|Japan|44768|
しかし、免許書は様々な情報も含めている。1:1の関係なら、テーブルに免許書のすべての情報(有効期限、種類など)も入れないといけないことになる。
| id | person_name | height | country | driving_license_number | license_expiration_date | license_type |
|---|---|---|---|---|---|---|
| 1 | Jose | 190 | Mexico | 22193 | 2030/12/12 | gold |
| 2 | Taro | 160 | Japan | 44768 | 2017/04/30 | gold |
license_expiration_dateやlicense_typeなどのようなカラムを「人」テーブルに入れないといけない。そのパターンが続くと、膨大なテーブルになってしまうので、以下のリンクを読むと良い。
可視化、カラム数を考慮するなら、オブジェクト指向に基づいた構造を考えるのは良い事。
上記のテーブルを見たら、カラムを2つのオブジェクトに分けられる。
- 人
- 免許証
以下のように2つのオブジェクトで2つのテーブルに情報を分けられる。
|id|person_name|height|country|driving_license_id
|:---:|:--:|:--:|:--:|:--:|:--:|
|1|Jose|190|Mexico|1|
|2|Taro|160|Japan|2|
|id|driving_license_number|license_expiration_date|license_type
|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|1|22193|2030/12/12|gold|
|2|44768|2017/04/30|gold|
こうして、1人に対して一つの免許証を紐付ける事ができ、1:1を実現できます。
一対多の関係
1:*の説明と例
AのレコードはBの複数のレコードと関連する可能性があるがBのレコードはAのレコードと最大一件のみ関連する。
- 人間は1人の実母しかいないけど、ある母は複数の子供がいる
- ある1つの町は1つの国にしか所属しない。
- ある人は一つの会社にしか属さないが、会社は複数の従業員がいる
ということで、Qiitaのようなwebアプリケーションで考えてみる。
お試し
あるユーザの投稿一覧を表示(実装)したい場合どうやったら実現できるか?
テーブル構造は?
多対多の関係
互いに対応づけられる二つの項目が双方とも多数である状況を指す表現。
http://www.weblio.jp/content/%E5%A4%9A%E5%AF%BE%E5%A4%9A
*:*の説明と例
つまり、あるテーブルの複数のレコードに他のテーブルの複数のレコードと関係を表すリレーションのこと。
例えば、
- レンタル映画 <ー> 顧客
- 生徒 <ー> 講義
- 商品 <ー> 店舗
1:*とはちょっと考え方が変わってくるので注意。
ただし、ここが分かればリレーションに関してはおおよそOKという感じ。
演習3: 下のような機能を実装したい場合を考える
- あるユーザのお気に入り一覧 を表示する
- ある投稿をお気に入りしているユーザ一覧 を表示する
という機能を実装するとしたら、今までの1:*の関係で書けるか?
他に例を挙げると、
- Twitterのお気に入り機能
- Facebookのいいね
- LINEの既読・未読
- Qiitaのような記事にいいねをする機能
多対多の条件の時は、中間テーブルを作るとわかりやすくなることが多い。
記事にいいねをする場合の例で考えてみる。
| users |
|---|
| id |
| likes |
|---|
| user_id |
| post_id |
| posts |
|---|
| id |
いいね数はcountでとる感じなのかな?
じゃあ「いいね」が増えた時どーすんの?
- そもそもそこだけNoSQLなどを使う
- 「いいね」の数はcountではなく、likesなどに数のカラムをもたせてそこをselectさせる(これだとUPDATEの海図うが増えすぎる)
- またははてブのようにいいねし放題にしちゃう
- 本当にajaxなどの通信があるたびにcountを行い、フロントの返す値に含める
などなどある気がしているが、これが正しいのかはわからない。誰かご教授ください!
JOIN句について
上で説明したような1対多を実現させる為に使うSQLクエリ。
- テーブルを結合することで複数のテーブルからデータを参照することが可能に
JOIN 結合先テーブル名 ON 結合条件
SELECT *
FROM `table1`
INNER JOIN `table2` ON `table1`.`id` = `table2`.`id`;
SELECT *
FROM `table1`
LEFT JOIN `table2` ON `table1`.`id` = `table2`.`id`;
SELECT *
FROM `table1`
RIGHT JOIN `table2` ON `table1`.`id` = `table2`.`id`;
- JOIN
- INNER JOIN の省略形
- 内部結合
- LEFT JOIN
- LEFT OUTER JOIN の省略形
- 外部結合
- RIGHT JOIN
- RIGHT OUTER JOIN の省略形
- 外部結合
話だけじゃ理解し難いので実際にやりながら。
(先輩と同期の苗字もお借りしながら)
-- メンバーテーブル
CREATE TABLE `members` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(32) DEFAULT NULL,
`role_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=12 DEFAULT CHARSET=utf8;
INSERT INTO `members` (`id`, `name`, `role_id`)
VALUES
(1, '鈴木', 1),
(2, '能美', 1),
(3, '大木', 1),
(4, '伊藤', 3),
(5, '逸見', 3),
(6, '田中', 3),
(7, '山本', 3),
(8, '後藤', 2),
(9, '巻嶋', 2),
(10, '佐竹', NULL),
(11, '森本', NULL);
-- 役割テーブル
CREATE TABLE `roles` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(32) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
INSERT INTO `roles` (`id`, `name`)
VALUES
(1, '管理者'),
(2, '一般'),
(3, 'VIP'),
(4, 'ゲスト');
上記のmembersテーブルとrolesテーブルをJOINしてみる:
SELECT members.name, roles.name FROM members JOIN roles ON members.role_id=roles.id;
どんな結果? RIGHT JOIN と LEFT JOIN も試してみる!
SELECT members.name, roles.name FROM members RIGHT JOIN roles ON members.role_id=roles.id;
SELECT members.name, roles.name FROM members LEFT JOIN roles ON members.role_id=roles.id;
結果は何に違うのか。
INNER JOIN
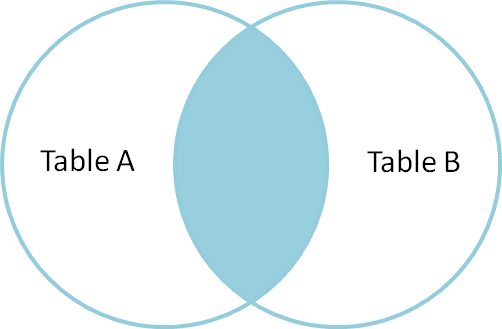
- 指定したカラムについて同じ値を持つレコード同士を結びつける
- 指定したカラムの値がどちらかにしか存在しないレコードについては表示しない
LEFT JOIN
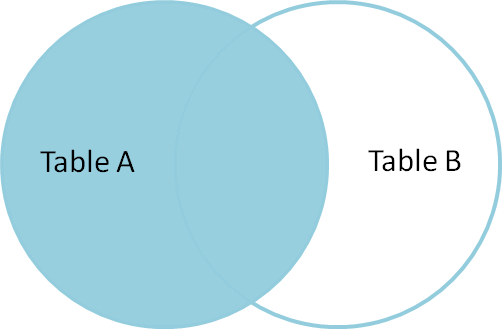
- テーブルを結合する際、優先するテーブルを1つ決める必要がある(この場合左、
FROM ***のテーブルが優先となる) - INNER JOINと同じく、同じ値を持つレコード同士を結びつけて表示する
- が、優先するテーブルのレコードは結びつくものが無くとも表示する(結びつくものが無い場合、NULLで結合される)
- 今回の場合、役割が決まっていない人も表示したい、とか
RIGHT JOIN
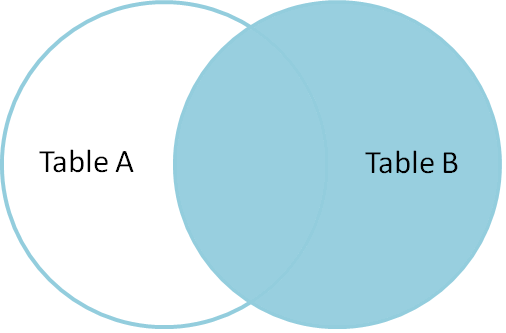
- 優先するテーブルが入れ替わっただけ。
LEFT JOIN と RIGHT JOINの何が違うのか疑問に思った人へ。
今まで数学の集合などをやってきた人にはLEFT JOINとRIGHT JOINの何が違うのかと思った人もいるのではと思っている。まさしくその通りで。本質的にやっていることは同じ。気にしておくべきはどちらのテーブルからどちらのテーブルにJOINするのかということ。なので以下のような場合は同じと考えて良い。
FROM A LEFT JOIN B
FROM B RIGHT JOIN A
例えがうまく言えているがわからないが、数学的にいうと、対偶のような関係といったら伝わるか?
JOINにもアルゴリズムがあり、その順番によっては大きくパフォーマンスが大きく変わる場合がある。MySQLの場合はよしなにやってくれるが、よしなにやってくれないDBの場合はとても気にすべき要項。
これを気にするだけでパフォーマンスに数倍から数百倍の差が生じることがある。
お試し
- 改めて
usersとpostsテーブルの構成を確認してみる(どうなってる?)
INDEXを試してみる
実際にJOINを使っていくと、多くのテーブルを結合していくことで、何万、何十万、何百万....と指数関数的にレコードが大きくなってしまうことがある。こういったクエリは当然実行する速度が低下することが多々ありうる。
そこで、SQLでは、レコードを探す際に辞書の索引のようなものをつけることで、目的のレコードまでの道しるべを指し示すことができる。
それがINDEX。
下のクエリを一度作成して実行をためす。
テスト用テーブルを作成
CREATE TABLE sample (
name varchar(64) NOT NULL,
point int NOT NULL
) ENGINE=InnoDB;
テスト用のデータを挿入
INSERT INTO sample (name, point) VALUES
('sato', 100),
('suzuki', 200),
('takahashi', 300),
('tanaka', 400),
('ito', 500),
('yamamoto', 600),
('watanabe', 700),
('nakamura', 800),
('kobayashi', 900),
('kato', 1000);
データを複製して1000万件のテストデータを作成
INSERT INTO sample (name, point)
SELECT s1.name, s1.point
FROM sample s1, sample s2, sample s3, sample s4, sample s5, sample s6, sample s7;
結構、時間がかかるので、気長に待つべし!
検索用のデータを1件追加する
INSERT INTO sample (name, point) VALUES('doraemon', 100);
検索してみる
SELECT * FROM sample WHERE name='doraemon';
割と検索するのに時間がかかったかと。
nameカラムに対して、INDEXを追加する
ALTER TABLE sample ADD INDEX(name);
またまた結構、時間がかかるので、気長に待つ!
もう一度、検索してみる
SELECT * FROM sample WHERE name='doraemon';
お、まじか!?と思うくらいには、検索結果を得る時間がかなり短縮されたのが実感が出来る!
参考資料
- MySQLで大量のデータを追加してみる - yk5656 diary
- MySQLパフォーマンスチューニングのためのインデックスの基礎知識 - 久保清隆のブログ
- MySQL初級者を脱するために勉強してること -INDEX編- - Qiita
外部キー制約
投稿をしたユーザの情報を取ってきたい → でも取れない。
postsのuser_idに対応するユーザのレコード(usersのid)が存在しない場合
- ようするに「投稿」が存在するのに「投稿者」がいない状態
- どうすればこのような 迷子 の投稿を無くせる?
- 1つでも投稿があったらユーザを消せないようにする
- 存在しないユーザIDの投稿を作成できないようにする
FOREIGN KEYとかFキーとか聞いたことがある方、それであってると思われる。
外部キー(がいぶキー、英語:foreign key、FK)は、コンピュータの関係データベースの関係モデルの文脈において、2つの関係変数(テーブル)の間の参照整合性制約をいう。
外部キー - Wikipedia
http://ja.wikipedia.org/wiki/%E5%A4%96%E9%83%A8%E3%82%AD%E3%83%BC
整合性が崩れていると...?
- ユーザの関係が崩れた投稿がうまくSELECTできずに記事一覧に出てこない。。。
- 記事の詳細画面で対応するユーザIDが存在しない場合を考慮する必要が。。。
などなど。不整合により様々なバグ、余計な実装発生の原因に。
それを防げる仕組みが外部キー制約。素晴らしい。万歳。
外部キー制約とは
外部キー制約とはテーブル間の値に一定の条件を設ける条件のようなもの。
サーバサイドやフロントエンドでロジックを書いて本来入れるべきでは無い値を弾くようにするが、最後にデータが保存される直前でも制約をつけておく事で安全な値が入力されていると保証する事ができる。
-
CASCADEとかを指定しておくと親テーブルに対して更新を行った際に、子テーブルで同じ値を持つカラムの値も合わせて更新(削除)してくれる
ER図
文字だけだとかなり複雑になってくるので、ER図を使って説明する。
E-R図(ERD: Entity Relationship Diagram)とは、データを「実体(entity)」と「関連(relationship)」、「属性(attribute)」という3つの構成要素でモデル化する「ERモデル」を図で表したものである。ER図はおもにデータベースを設計する際に用いられている。
ER図 (Entity Relationship Diagram)
http://itref.fc2web.com/technology/entity_relationship_diagram.html
DB設計の全体像、テーブル同士の関連を掴むことに使う図。
各カラムのコメント(型や制約だけでは読み取れない関連性や注意事項など)までは表示してくれないので、ER図と合わせてテーブル定義書を作ることも。
PlantUMLがER図に対応しているので、使ってみると良い。
PlantUML で ER 図(ERD)を描く(似非ではないです)
HameeではAtomのパッケージの物を使っていることが多いとのこと。vimやemacsやPHPStormやらの方々はその時だけ使うということになるのだろうが・・・
中間テーブルの設計
多対多に関しての課題に戻ると、ER図を得た知識で考える。
関係のテーブルを、一対多と多対一に分割し、結合できるのでは?
多対多関係を表示できるようなテーブルは中間テーブルという。
いいねを実装するのであれば、以下のようテーブル関係が必要になる:
users ↔ 中間テーブル ↔ posts