以前の記事で、Databricks社製のオープンソースな言語モデルである「Dolly-v2」について公式のドキュメントを交えて解説しましたが、今回、非公式のデモ集である「dbdemos」にもDollyの利用例について記述されたサンプルノートブックが追加されていることを知ったので、こちらも試してみることにしました。
dbdemosについて詳しくは過去に書いたこちらの記事もご覧ください。
現時点でのDollyの性能を最大限引き出す為に必要な実装のヒントが書かれており、Dollyに限らずプロンプトエンジニアリングの観点でも興味深い話がありました。
01 instruction
ChatGPTの魔法をオープンなモデルとレイクハウスで民主化する
大規模言語モデル(LLM)は一見知性を持っているかのように、チャットや質疑応答で驚異的な結果を出しています。
しかしLLMはあなたが持つ特定のデータについて答えられるでしょうか?あなたの企業のナレッジベースやSlackのチャットについて答えることを考えてみてください。
幸いなことに、オープンソースのツールとオープンなLLMを活用すれば、Datablicksで簡単に構築できます。Databricks Dolly: 世界初のオープンな対話で調整されたLLM
現在、最先端のモデルは制限付きのライセンスが付属しており、商業目的で使用することはできません。これは、訓練やfine-tuningに使われたデータセットがオープンなものではないためです。
これを解決するため、DatabricksはDollyを公開しました。Dollyは初の完全にオープンなLLMです。Dollyはdatabricks-dolly-15k(15000個の人手で作成された質疑応答ペアで、LLMの調整に特化している)でfine-tuingされており、あなた自身のモデルを作成するための出発点となるでしょう。あなたの質問に答える園芸用チャットボットをつくる
本デモでは、Dollyをベースとしたチャットボットを作成します。ガーデニングショップが、顧客の質問に答え、植物を育てる方法についてアドバイスする機能を組み込みたいとします。
デモは2つのセクションに分けられます。
- データ準備:Q&Aデータベースを用意し、埋め込みによってベクトル化します
- 推論:Dollyを利用して質問に回答します。プロンプトエンジニアリングによってQ&Aを知識源とします。
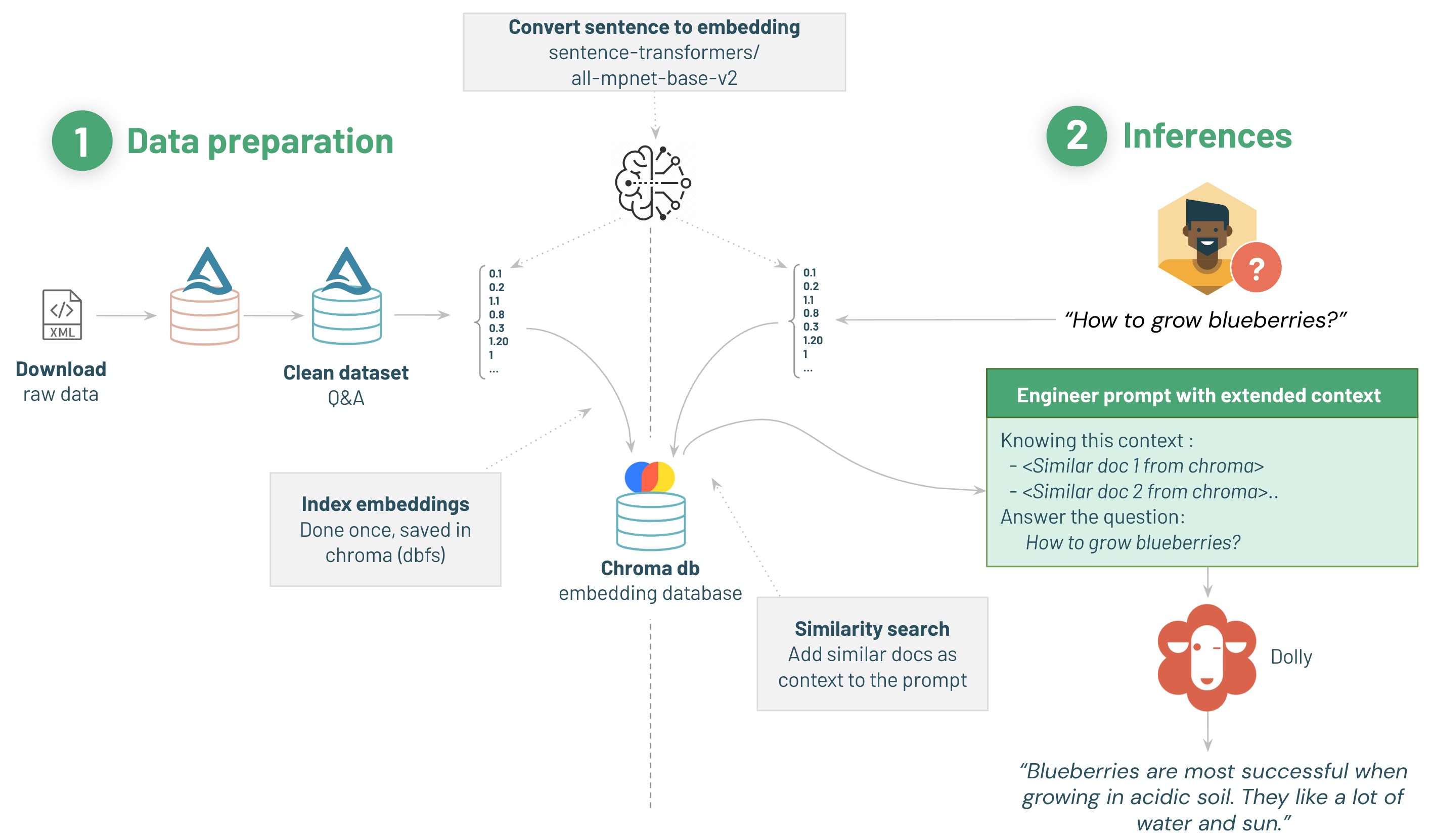
02 Data preparation
機能を特化させるため、学習データセットとしてQ&Aのリストが必要です。
このデモでは、Stack Exchange データセットを利用します。
Stack Exchange のデータを取り込み、クリーンアップして保存するシンプルなパイプラインを利用しましょう。
- 生データをダウンロードする
- クリーニング
- Sentence 2 Vectorモデルでデータをベクトルに変換
- ベクトルをChorma DBwp利用して保存する
StackExchangeのデータセットはEleutherAIが作成、公開しています。
StackOverflowが有名ですが、それ以外の各ジャンルに対応したQ&Aが登録されているため、特定のカテゴリに対する知識源が必要な場合に利用できそうです。
1/ データセットのダウンロード・展開
園芸に関する質問に着目したいので、gardening のデータセットを取得します。
- Gardening StackExchange データセットをダウンロード
- 7-zipで解凍(
7zをインストールする必要あり)Posts.xmlをコピーspark-xmlでパースする
2/クリーニング
sparck xmlを利用してデータを読み込みます。クラスターの設定にライブラリが登録されていることを確認してください(インストール時のクラスターには登録されているはず)。Maven coordinates:
com.databricks:spark-xml_2.12:0.16.0
軽く前処理も行います。
- 高評価のついている(スコア>=5)質問のみ抽出
- HTMLを平文に変換
- 質問と回答を一つのテーブルに結合
データは最初、HTMLタグがついていたりするのでこれを除去して、さらに長すぎるテキストや評価の低い行を除去します

質問と回答は別々のレコードとして保存されており、これを親IDの情報を元に結合します

質問と回答が同じペアに収まりました。
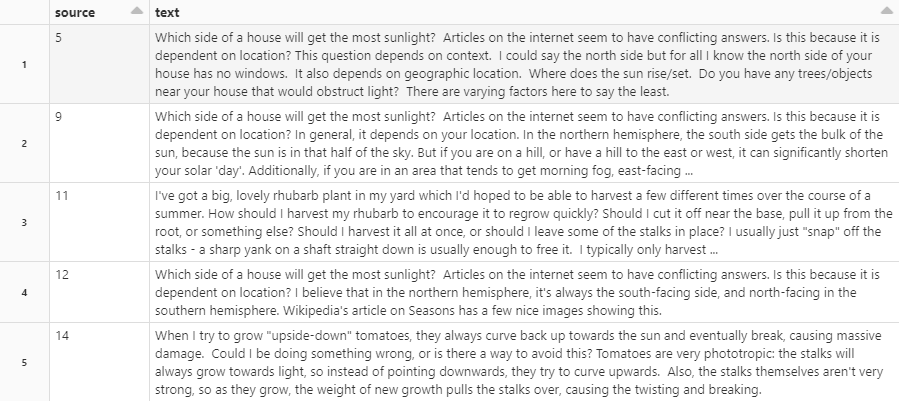
長いテキストを利用すると、推論が遅くなる可能性があります。一つの対策として、要約モデルを利用して文を短くします。
この作業には時間がかかるため、推論中に要約を行わずに済むよう、データ準備パイプラインでこれを実行します。
3/ 埋め込みモデルをロード
埋め込みモデルをhugging faceからロードして、後でchroma DBで利用します。
文書をベクトル化するsentence-transformersの学習済みモデルを利用します。
4/ ベクトルDBの文書にインデックスを付ける
テキストをロードし、langchainのパイプライン内で利用可能なデータベースを作成します。
データセットはベクトル化されており、入力された質問も同様にベクトルにし、関連するテキストと照合することができるようになります。
- Sparkでテキストチャンクを収集する。langchainはWordドキュメント、GDrive、PDFなどから直接チャンクを読むこともサポートしている。
- chromaでシンプルなインメモリベクトルDBを作成する。
sentence-transformerから埋め込み関数をインスタンス化する。- データベースを生成して保存する
文書データベースを作成します。- 関連するテキスト小さなデータセットを抽出し、
Documentを作成する。langchainはPDFやGoogleDriveから直接作成することもできる。- 長いテキストをチャンクに分割する
3 Dollyのためのプロンプトエンジニアリング
プロンプトエンジニアリングは与えられた質問に、モデルをよりよい答えに導くための追加情報を加える技術です。
- 用途に応じた答え方を伝える(例:あなたは庭師です。植物を生かすために以下の質問に出来る限り答えてください)
- 似た質問など、追加の情報を与える(例:「別のQ&A」を踏まえた上で、答えてください)
- 具体的な回答の指示(例:イタリア語で答えてください)
- 以前の質問の記録(埋め込みとして圧縮する)
langchain、Hugging Face transformers、Apche Sparkを適用して、特定のテキストコーパスについての質問に答えるプロンプトを作成する方法を示します。
この例はDollyだけではなく、少しの変更を加えれば、どんなテキスト生成LLMや、OpenAIであっても役に立ちます。
- 質問を取得し、質問データベースを作成したのと同じモデルでベクトルに変換する
- chromaから類似するQ&Aを検索する
- 質問と類似Q&Aを含んだプロンプトを作成する
- dollyにプロンプトを入力する
- 顧客がアドバイスを得られる
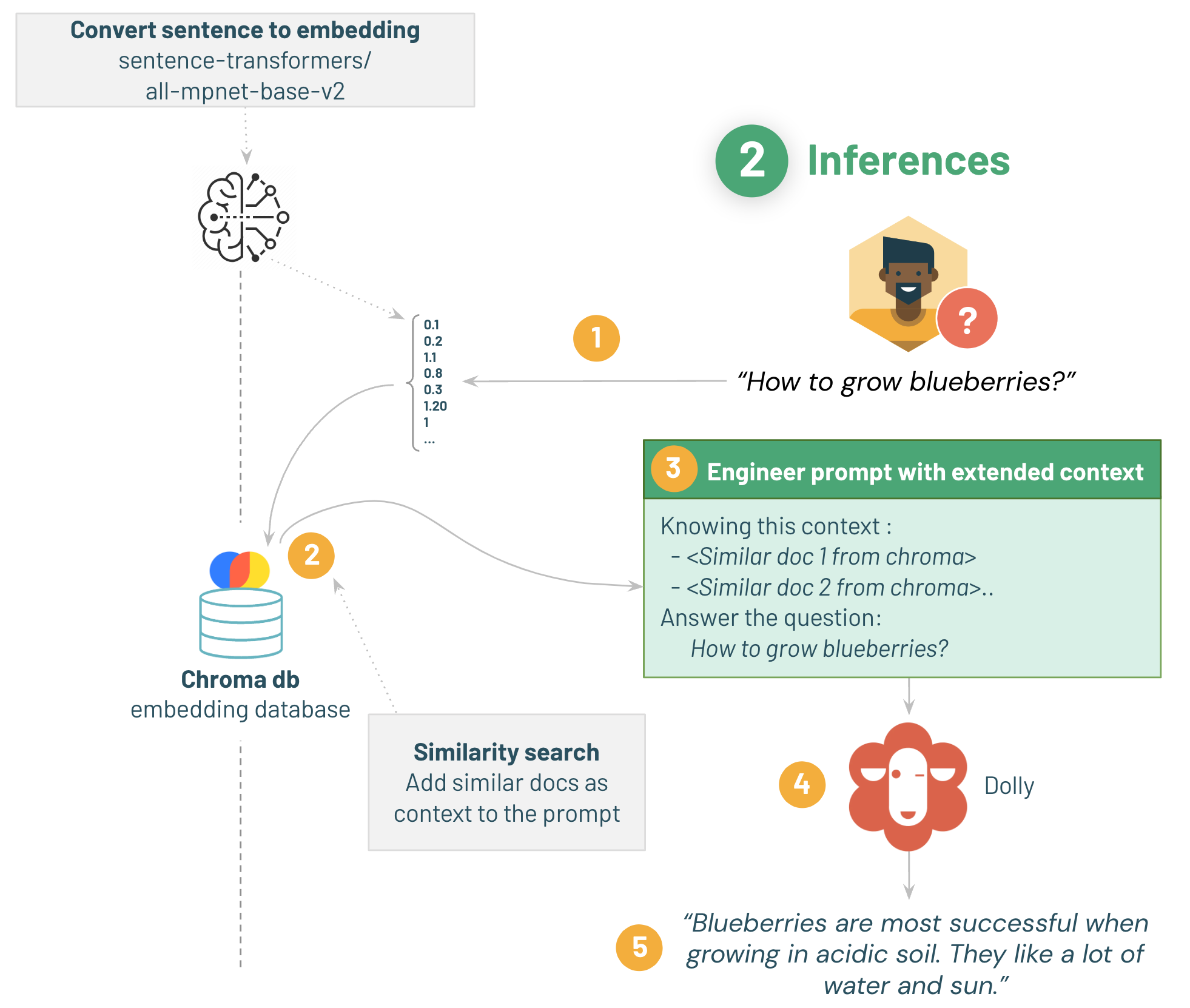
1/ 埋め込みモデルのダウンロード
(データ準備と同様)
2/ chromaで類似検索
簡単な質問で検索を試してみましょう。
kはプロンプトに送るチャンクの数です。プロンプトが長くなるとより多くのコンテキストを含めますが、その分処理が遅くなります。
試しに"how to grow blackberry?"という文に類似した文書を検索してもらいます。
結果、同じくブラックベリーについて聞く質問が返ってきました。

3/ langchain でプロンプトエンジニアリング
langchain でチェーンを作ることによって、言語モデルとプロンプトを合成できます。
langchainで定義するテンプレートは以下のようになっています。
template = """Below is an instruction that describes a task. Write a response that appropriately completes the request.
Instruction:
You are a gardener and your job is to help providing the best gardening answer.
Use only information in the following paragraphs to answer the question at the end. Explain the answer with reference to these paragraphs. If you don't know, say that you do not know.
{context}
Question: {question}
Response:
"""
「あなたは庭師です」というロール設定および「以下のパラグラフの情報だけを使ってください」「分からない場合は分からないと答えてください」という制約を設けていることが分かります。
言語モデルが質問に答えるのには多くの要因が関わっていることを知っておいてください。特筆すべきなのはプロンプト自身のテンプレートです。これが変化するとモデルの性能も変化します。
生成過程自体も調整可能であり、最良の設定を見つけるためにしばしば試行錯誤が必要になります。Hugging Faceの素晴らしいガイドもご覧ください。
最もパフォーマンスに影響する設定は、
maz_new_tokens長い返答は生成も長くかかります。短くすると、早くなりますnum_beamsビームサーチを利用する場合、ビームが増えると実行時間が直線的に増加します
4/ テスト
準備が整いました。質問に答え、その答えをソースとともに分かりやすく表示する関数を定義します。
def answer_question(question):
similar_docs = get_similar_docs(question, similar_doc_count=2)
result = qa_chain({"input_documents": similar_docs, "question": question})
result_html = f"<p><blockquote style=\"font-size:24\">{question}</blockquote></p>"
result_html += f"<p><blockquote style=\"font-size:18px\">{result['output_text']}</blockquote></p>"
result_html += "<p><hr/></p>"
for d in result["input_documents"]:
source_id = d.metadata["source"]
result_html += f"<p><blockquote>{d.page_content}<br/>(Source: <a href=\"https://gardening.stackexchange.com/a/{source_id}\">{source_id}</a>)</blockquote></p>"
displayHTML(result_html)
answer_question("What is the best kind of soil to grow blueberries in?")
質問文に対して類似文書を検索し、プロンプトに変換します。
その後、質問と出力、類似文書をまとめてHTMLファイルにして出力します。
結果、以下のような出力がされました。

ブルーベリーをどのような種類の土壌で栽培するか、またどのようなケアを適用するかを決定する際には、多くの変数があります。 まず、あなたの場所と栽培している気候があります。次に、土壌の組成、土壌の質、土壌のph、植栽培地の種類、そして植物が剪定されているかどうかです。 あなたの説明の前に、「私は知りません」という重要な言葉を最初に付け加えておきたいと思います。 栽培している作物に害を及ぼす可能性のある変更を加える前に、土壌検査を受けることを検討した方がよいでしょう。 ブルーベリーに最適な土壌は、中~高phの有機質で多孔質の砂質土壌です。
Scaling the our Question Answering with Spark
ここにはSparkUDFを利用して分散処理を行う方法について書かれています。
GPU入りクラスターが必須です。
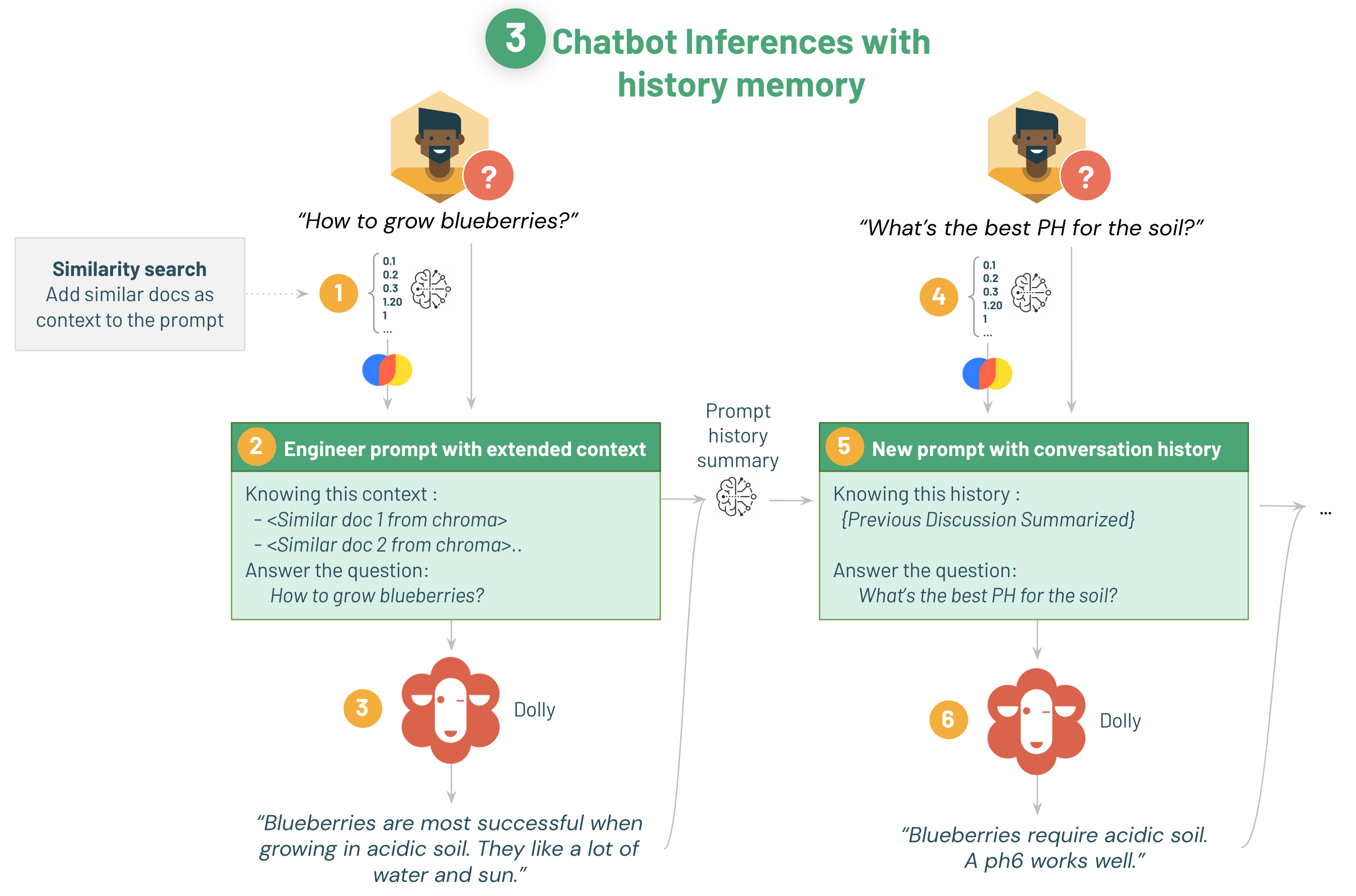
4 チャットボット化
チャットボットを作るため、先ほどのQ&Aシステムを改善します。
前の質問のコンテキストを保持できるメモリの追加が主な変更点です。
最大の問題は、会話の履歴をコンテキストとしてDollyに送信することはできないという点です。
これはコストの問題の他、それだけ大きいサイズのテキストがモデルの窓の最大値を超えてしまうのが最も大きな理由です。
秘策として、要約モデルを使用して会話の要約を取得しプロンプトに挿入するステップを追加することをします。
これを行う為には、langchainのConverstionsummaryMemoryを利用します。
注:これは発展的内容です、ノートブック3から始めることを推奨します。
2/ langchain とメモリでプロンプトエンジニアリング
言語モデルとプロンプトを組み合わせて、記憶を基に回答ができるチェーンを作成できるようになりました。
def build_qa_chain():
torch.cuda.empty_cache()
# Defining our prompt content.
# langchain will load our similar documents as {context}
template = """You are a chatbot having a conversation with a human. Your are asked to answer gardening questions and help cultivating plants.
Given the following extracted parts of a long document and a question, answer the user question. If you don't know, say that you do not know.
{context}
{chat_history}
{human_input}
Response:
"""
prompt = PromptTemplate(input_variables=['context', 'human_input', 'chat_history'], template=template)
例:What is the best kind of soil to grow blueberries in? → How much water should I give?

↓

このように、前の文脈を記憶できていることが分かります。
EX: MLFlowにデプロイする(DBR ML 13+必須)
langchainの作ったパイプラインを、mlflowを呼び出して保存する方法について
まとめ
本デモでは、会話履歴を用いた基本的なプロンプトエンジニアリングの手法を見ていき足t。より高度な手法を用いればより高度なコンテキストを供給できます。
モデルの性能を上げるため、より良くコンテキストを汲み取るためには良い訓練データを使うことが鍵となります。ボットを作る上での成功の秘訣は高品質なデータを準備することです。
データセットを改良するのに有効なのは、質問と会話を補足しておいて、少しずつQ&Aデータセットに追加していくことです。
例えば、langchainはOpenAIに似たデータセットでトレーニングされたモデルで動作するように設計されており、Dollyのものとは完全には合いません。
プロンプトが訓練データの内容と一致するように設計されているほど、精度も向上します。
データセットはどうなっているのか
まとめの項目で、プロンプトと訓練データの関連性について触れられていましたが、実際にDollyの訓練データはどうなっているのでしょうか。
databricks-dolly-15kをダウンロードして中身を見てみました。
{
"instruction": "What is the future for human?",
"context": "",
"response": "This is a very wide open question. It could be two directions. One direction is that human would just disappear like the dinosaur. One direction is that human would become a species like a god. For the first direction, it may be caused by many situations. e.g. Nuclear war from WW3, extreme climate change. For the other direction, reproduced energy is ready, all cancers can be cured, everything can be done with robot with AI, human life is unlimited.",
"category": "general_qa"
}
{
"instruction": "If I have more pieces at the time of stalemate, have I won?",
"context": "Stalemate is a situation in chess where the player whose turn it is to move is not in check and has no legal move. Stalemate results in a draw. During the endgame, stalemate is a resource that can enable the player with the inferior position to draw the game rather than lose. In more complex positions, stalemate is much rarer, usually taking the form of a swindle that succeeds only if the superior side is inattentive.[citation needed] Stalemate is also a common theme in endgame studies and other chess problems.The outcome of a stalemate was standardized as a draw in the 19th century. Before this standardization, its treatment varied widely, including being deemed a win for the stalemating player, a half-win for that player, or a loss for that player; not being permitted; and resulting in the stalemated player missing a turn. Stalemate rules vary in other games of the chess family.",
"response": "No. \nStalemate is a drawn position. It doesn't matter who has captured more pieces or is in a winning position",
"category": "information_extraction"
}
instructionは基本的に短文であることが多く、いくつかのタスクではcontextを読ませて回答させる方式をとっていました。
この場合、質問は簡潔に行い、セクションを分けて答えるための知識を与える、というプロンプトを取るのが良いのでしょうか。
おわりに
今回はDollyを使ったチャットボットの設計と、それを活かすためのプロンプトエンジニアリングについて見てきました。
訓練データに合わせてプロンプトを作成するという手法は、Dollyに限らず言語モデル全般で利用できるテクニックだと言えるのではないでしょうか(OpenAIくらいになるとさすがに気にする必要性も薄れるとおもいますが)。今後も、Dollyのように比較的小規模かつオープンな言語モデルが増加することも予想されますが、そういったモデルを利用する際には使えるのではないかと思います。