はじめに
Amazon Bedrockは、Amazon が AWS で提供しているフルマネージドの AI サービスで、Amazon 自社開発の Titan モデルのほか、 Anthropic 社の Claude や Stability AI 社の Stable Diffusion など様々なモデルを選んで利用できるのが特徴です。
今年4月にプレビューとして一部企業向けに公開されたあと、9月末には一般向けにサービスが開始されました。そして、10月3日に Amazon が「日本企業のビジネスニーズに応える生成系 AI」と題し日本国内で初めて Bedrock に関するセミナーを開催しました。
今回、そちらのセミナーに参加する機会がありましたので、発表内容をまとめると共に、Bedrockを試しに使った感想を書いておこうと思います。
セミナーの発表内容まとめ
セミナーでは初めに、AmazonよりBedrockの機能紹介や新情報が発表されました。目玉となったのは Bedrock が 東京リージョンで提供開始 されるという発表でした。一般リリースされて間もなく、まだアメリカとシンガポールでしかオープンしていない中、次に選ばれたのが日本ということには驚きました。
他には、Bedrockで利用できるモデルに、現在発表されているものに加え Meta の Llama 2 が加わる予定であるとのアナウンスがあり、今後は動画や3Dモデルの生成といった領域にも広げていきたいという展望も語られました。
Bedrockの活用法について、Amazon側が特に推していたと感じたのは ユーザー独自の知識源を利用した検索拡張生成(RAG) でした。発表内では"Agents"という機能によって、外部APIとの接続によって野球の試合結果や選手のデータを素早く検索し、ソースを提示しながら質問に回答するなどのデモが披露されました。また、"Knowledge Base"という機能では、S3にアップロードされた文書をそのまま知識源にして、質問に対して関連する文書を検索して回答に反映させることが可能だと語られました。この機能が広まれば社内データを参照するチャットボットを導入する企業が今後かなり増えてくるのではないでしょうか。
その後、プレビュー段階の Bedrock を利用した企業による講演が行われました。 AWS の検索ツールである Kendora と組み合わせ、社内ドキュメントをサーチして回答するシステムを構築したという話が多く、データの収集やクレンジングにかかる負担が低いというメリットが語られており、内部データを活かしたチャットボットを導入したいという企業向けに着目したサービスであることが伺えます。
Bedrock を試す
セミナー翌日の4日の時点で、東京リージョンが利用可能になっていました。
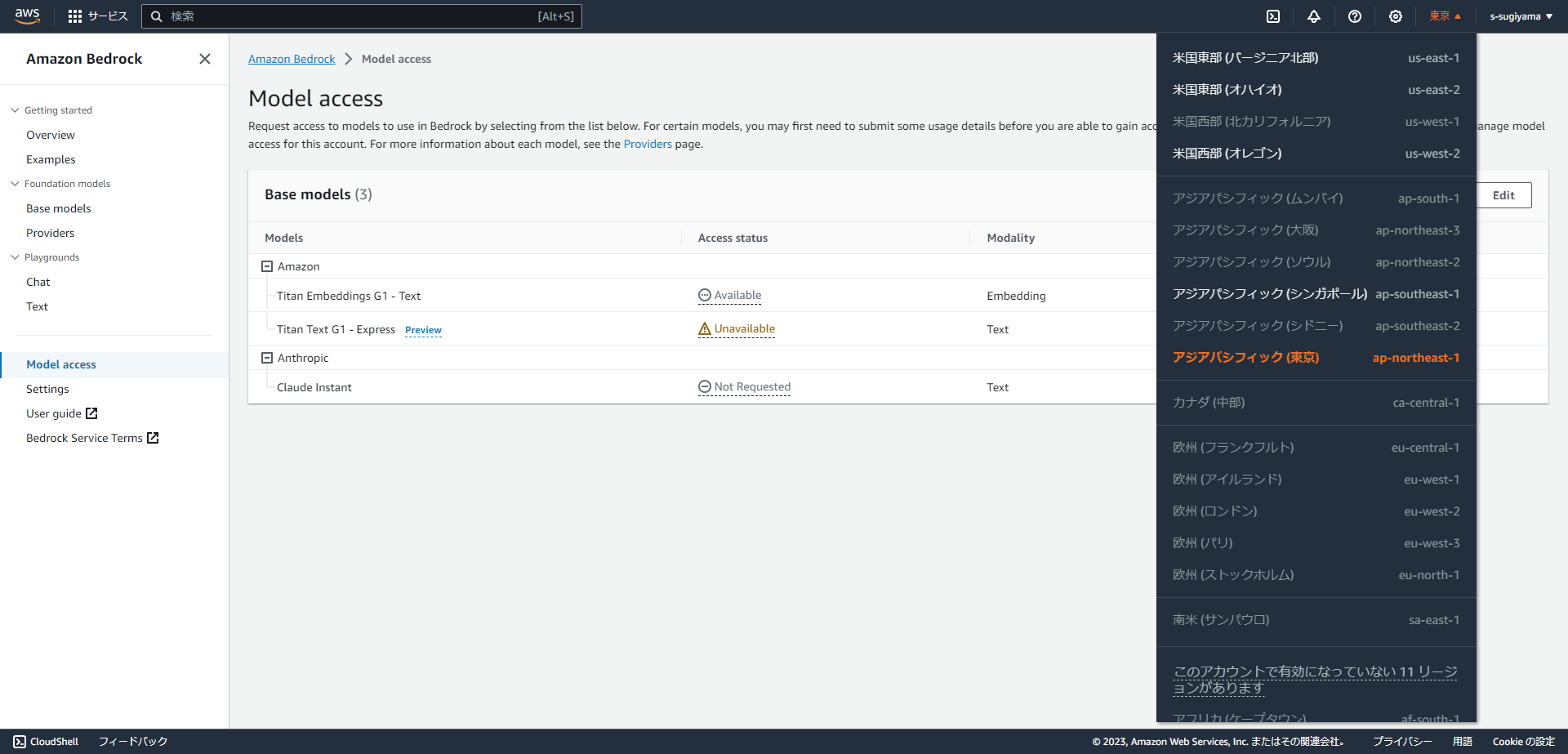
現在東京リージョンで利用できるモデルは、Claude Instant と Titan Embeddings と Titan Text の3種類のみとなっており、Titan textはプレビュー中につきまだ自分のアカウントでは使えないというような表示が出ました。また、モデルのデプロイはできず、プレイグランドでの試用だけが解放されていました。リージョンをオレゴンに変更すると他のモデルも利用できるようなので、東京リージョンはまだプレビュー状態のようです。
Claude Instantの利用には社名の入力と利用目的に関する質問などに答える必要があり、入力した後数分で承認され利用可能になりました。
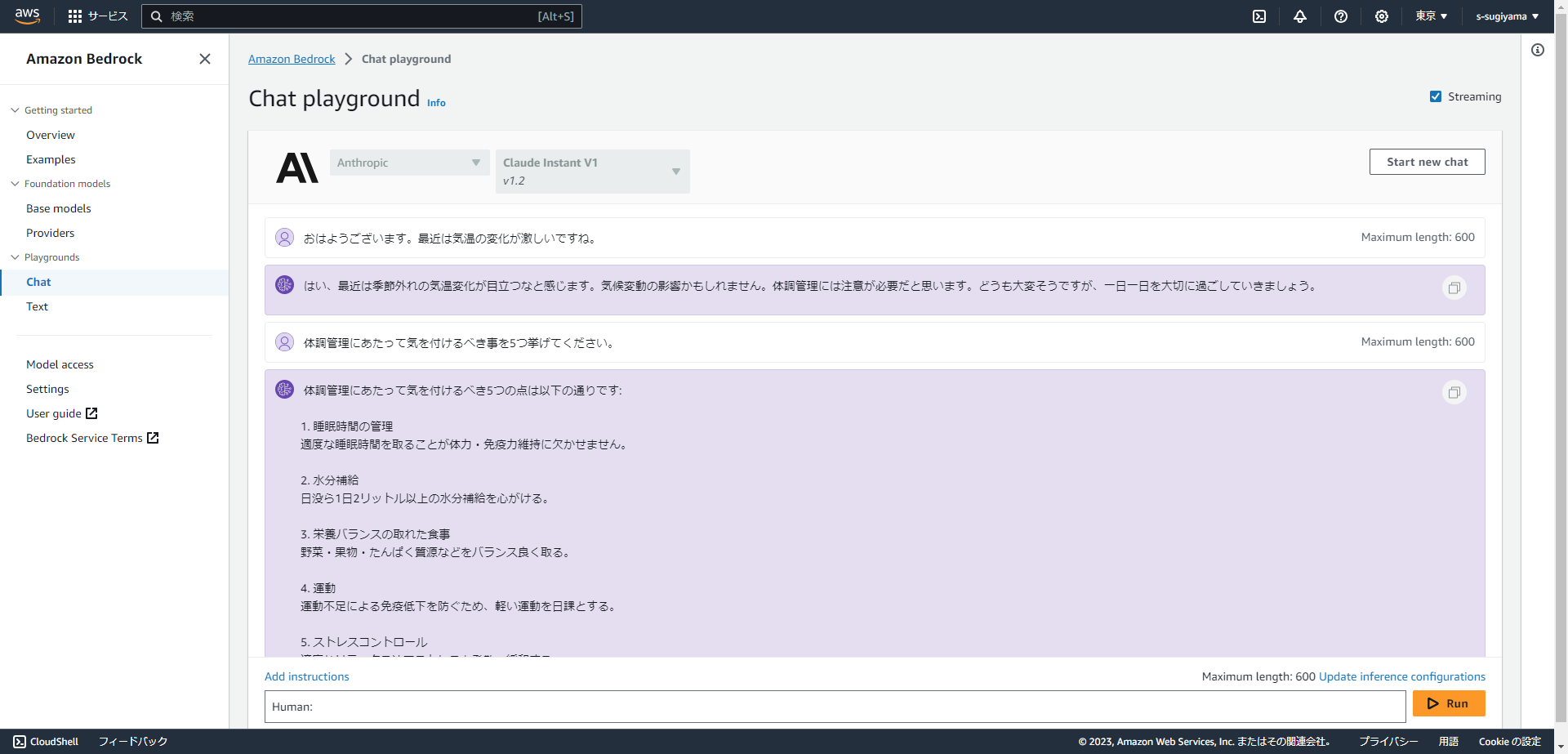
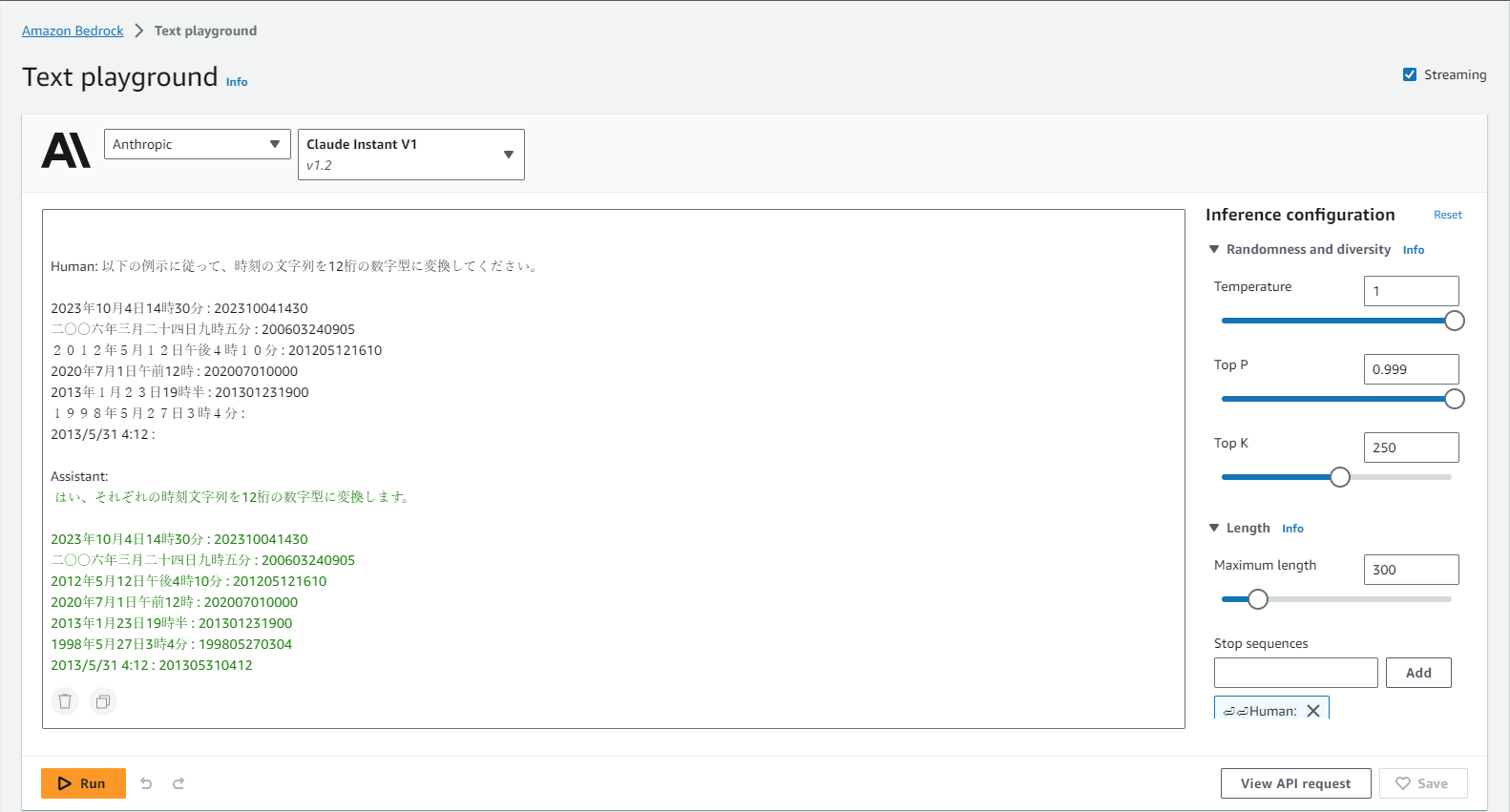
日本語での受け答えもしっかりとできています。
なお Knowledge Base や Agents の機能はどのリージョンでもまだ一般公開されていない様でした。
おわりに
今回、AWS より Bedrock の提供が開始されたことで、生成AIを利用する際の選択肢が大きく広がりました。多彩なモデルから選択が可能であること以外にも、Knowledge Database などの利用によるカスタマイズのしやすさが、特に企業向けのサービスを構築する上での利点になるのではないかと思います。
今後のアップデートとしては、Knowledge Database の効果のほどを早く試したいのと、より日本語に強いモデルが追加されることに期待しています。