概要
Databricks は AWS や Azure などで利用可能なデータレイクハウスプラットフォームです。
と言われても、具体的にどういったことが出来るのかはイメージしずらいと思われます。Databricks の機能は幅広いですが、実際のユースケースを踏まえないとプラットフォームを一貫できるメリットが分かりずらく、またいろいろ触って勉強しようと考えてもデータセットの準備が必要となったりするなど、ゼロから学ぶというのは現実的に難しいでしょう。
dbdemos は、Databricks の機能の理解に役立つサンプルとなるノートブックやデータセットが内包されたパッケージです。様々なシステム開発の事例を通して、データレイクハウスの構築から機械学習モデルのデプロイまで、Databricks の多様な機能について学ぶことができます。
ここでは、銀行の不正取引検知システムを例としたデモ " lakehouse-fsi-fraud " のドキュメントの翻訳、並びにノートブック上で何を行っているかについて解説します。
引用部分は、ノートブックに記載されている解説文の翻訳です。
インストール方法
databricksのワークスペースで、適当なノートブックとクラスターを作ってから以下を実行すれば完了。
パイプラインやデータセットなど必要なものはインストール時に自動で作成されます。
%pip install dbdemos
import dbdemos
dbdemos.install('lakehouse-fsi-fraud')
詳しくは以下の記事参照
利用方法
基本的にはノートブックの指示に従って「Run all」を実行すればよい。後はノートブックのテキストを読んだり、リンクをクリックして各種リソースを確認しながら進めましょう。
0.概要
Databricksは、どんなソースからのデータも、リアルタイムかつ最低限のコストでビジネスに最適化できる唯一のエンタープライズデータプラットフォームです。レイクハウスによってデータを一元化し、バンキングデータからこれまでできなかったスケールでの応答速度と効率によるリアルタイムでの不正検知が可能となります。
たった一つのプラットフォームとセキュリティレイヤーによってデータウェアハウスとAIのイノベーションを加速し、リスクを削減します。複雑でガバナンスが分かれた複数のソリューションを切り替える必要はありません。
Databricksはオープンソースとオープンスタンダードで構成されています。データは自分で保有したまま、ベンダーに依存せず容易に拡張することができます。また、オープン化によって外部の組織とベンダーに関わらずデータを共有することが可能です。
各種クラウドサービスを横断して利用でき、必要な場所でデータを処理できます。
タスク
銀行の取引内容から不正取引かどうかをリアルタイムで検知するシステムを作りたい
- 現在蓄積されている取引データから、分析可能な状態のデータベースを構築する
- データを分析し、不正取引の傾向を可視化する
- 機械学習によって、取引データから不正を自動で判別するモデルを作る
- モデルを実際に運用して精度を記録し、改善する

リアルタイムで情報を集め、一元化することは重要です。データは、リアルタイムのパーソナライゼーションや不正防止などの重要な機能を開放するための鍵です。
このデモでは、複数のソースからデータをリアルタイムで収集するend-2-endのバンキングプラットフォームを構築します。 この情報で、過去の不正取引について分析しパターンを得るだけでなく、リアルタイムで取引が持つリスクを評価することが可能となります。実装例としては、不正の可能性が高い取引に対して追加でセキュリティチェックを行ったり、人手での介入を行ったりするなどです。
実装の大まかな流れは以下の通りです。
- データを取り込んでSQLでのテーブル操作が容易なデータベースを作成する
- データを保護し、データアナリストやデータサイエンティストが読み取れる権限を設定する
- BIクエリを実行し、過去の不正について分析する
- MLモデルを作成し、リアルタイムで検出可能なシステムにデプロイする
デモを簡略化するため、外部のシステムが定期的に blob ストレージ (S3/ADLS/GCS) にデータを追加することを想定しています(技術的には、データは様々なソースから取得できます。SalesForce, Fivetran, queuing message like kafka, blob storage, SQL & NoSQL databases...)。
このデータがレイクハウス内でどのようにして分析し、予知保全をトリガーするかを見てみましょう。
目次
- データの準備(データエンジニア)
- データ保護とガバナンス(Unity Catalog)
- 分析(BI/ウエアハウス/SQL)
- モデル作成・リリース(データサイエンス&AutoML)
4.1 AutoMLの実行準備
4.2 AutoMLの生成例
4.3 サービス化
4.4 モデル改良
4.5 A/Bテスト - 全自動化(workflow)
1. データの準備(データエンジニア)
BI や機械学習に必要なデータの読み込みと前処理について学びます。
この例では、銀行取引の情報を利用するend 2 endのDLTパイプラインを実装します。ここでは medallion アーキテクチャを利用しますが、star schema や data vault などのモデルも利用できます。
autoloader を利用することで、新しいデータを追加で読み込むことができ、データベースを強化することができます。
このデータベースを利用して、DBSQL ダッシュボードで取引と不正の影響を追跡し、リアルタイムでの不正検知モデルを学習しデプロイします。
以下に示すデータフローを実装しましょう。

パイプラインが作成されているか、ノートブック内の Fraud detection Delta Live Table pipeline と書かれているリンクをクリックして確認してください。
1/ Databricks Autoloader によるデータの読み込み
Autoloader を利用すると、クラウド上の大規模なファイルを効率よく取り込み、拡大させることが可能です。
Autoloader の詳細についてはdbdemos.install('auto-loader')を実行してください。
パイプラインを利用して、生の JSON/CSV データを取り込みましょう。

2/ アナリスト向けにデータの品質強化と具体化
次のシルバーレイヤーではブロンズのデータからいくつかの情報をクリーニングしたインクリメンタルデータを作成します。
- 国名コードのクリーニング(ハイフンの除去)
- 残高の差分を計算する
また、Expectation(値のエラー情報)を追加して、データの品質を追跡できるようにします。これによってデータの異常値による変化を簡単に発見することができます。

3/ データを集約・結合し、機械学習用の特徴量を作る
これで、不正検出に必要な特徴量の準備が完了しました。
この取引データを充実させるために、モデルが予測のために利用するだろう追加の情報を結合します。

コード解説
データ分析の足掛かりとして、取引履歴・顧客データ・国データ・過去の不正取引レポートを、SQLで操作しやすく、機械学習のフレームワークに取り込みやすいテーブルに変換します。
- データはすべてDelta Live Table方式に変換される
- csvやjsonなどの様々な形式を一括で扱える
- 自動で追加、更新されるストリームデータにも対応できる
- ノートブック上ではテーブルとして出力しているので中身をチェック
Databricksにおけるデータの前処理はブロンズ->シルバー->ゴールドと段階分けして表現されています(メダリオンアーキテクチャ)。
- ブロンズ:生データをそのままテーブル化
- ここでは取引履歴の生データ
- シルバー:結合などの処理のためにクリーンアップ
- 国コードから余分な記号を取り除く
- 振込元/先の残高の差分を計算するなど、必要そうな項目を追加
- ゴールド:分析のために必要十分なデータが揃っている
- 国の座標、顧客のテーブルを結合し、必要な情報を揃える
この時点では学習に使えない項目(IDなど)もテーブルに含まれていますが、AutoMLで学習を始める段階で除去されます。
データセットの中身
- 銀行取引履歴(ストリームデータ)
- 取引金額
- 送金先/送金元国(3文字コード)
- 顧客ID
- 取引ID
- 送金先/元の残高(取引前後)
- 取引の種類(引出、振替など)
- 顧客データ(CSV)
- 国籍
- 住所
- 開設日時
- 最終操作日時
- 年齢層
- 顧客ID
- 国データ(CSV)
- 国コード(3文字)
- 座標(緯度経度)
- 国ID
- 過去の不正取引レポート(JSON)
2. データ保護とガバナンス(Unity Catalog)
これ以降、ノートブックを実行するクラスターの名前が、最初の「A cluster has been created for this demo」と表記されているセルに書かれている物と一致していることを確認してください。
Databricks上でデータテーブルを簡単に管理できるUnity Catalogについて学びます。
データプラットフォーム上で、完全なデータガバナンスとセキュリティを実現するのは困難です。テーブルに対する SQL GRANT だけでは不十分であり、ダッシュボード、モデル、ファイルなど複数のモデルアセットに対してセキュリティを強化する必要があるからです。
リスクを抑えつつイノベーションを推進するために必要なことは、
- すべてのデータアセットの統合
- 複数チームでのオンボード化
- 外部組織との共有と監視
グローバルデータガバナンスの実装とUnity Catalogでのセキュリティ
レイクハウスがUniy Catalogを用いてどのように課題を解決するか見てみましょう。
データはデータエンジニアチームによってDelta Tableとして保存されました。次のステップは、これらのデータをチーム間でアクセスできるようにしながら保護することです。
典型的な設定は以下の通りです。
- データエンジニア/ジョブ:主要なデータやスキーマの読み取りや更新(ETL)
- データサイエンティスト:最終(ゴールド)テーブルの読み取り・特徴量テーブルの更新
- データアナリスト:データエンジニアテーブルと特徴量テーブルの読み取りと、別のスキーマで追加データの読み込みや変換
- データは各ユーザーのアクセスレベル別に動的に隠される必要がある
これらが Unity Catalog によって可能になります。Unity Catalog にテーブルを保存すると、組織全体、複数ワークスペース、複数ユーザーがアクセスできるようになります。
Unity Catalog は、データプロダクトの作成やデータメッシュ周辺のチーム編成を含むデータガバナンスの鍵となります。
- きめ細かいアクセス制御リスト(ACL)
- 監査ログ
- データ リネージ
- データ探索
- 外部組織との共有(Delta Sharing)
クラスターのセットアップ
このデモを実行する際、クラスターのセキュリティモードが有効化されていることを確認してください。
「クラスター」のページで、新しいクラスターを作成し、「Single User」を選択し、Unit Catalogのユーザー(ワークスぺースに所属している必要があります)を選択してください。
データベースの探索
サイドメニューの「データ」から読み込まれたデータを見ることができます。
- データの置き場所を見る
- 検索
- アクセス権限の編集
Unity Catalog には3つのレイヤーがあります。
- CATALOG
- SCHEMA (or DATABASE)
- TABLE
カタログはSQLで作成できます(CREATE CATALOG IF NOT EXISTS my_catalog...)
SQLからテーブルにアクセスする場合は、フルパスを指定してください(SELECT * FROM <CATALOG>.<SCHEMA>.<TABLE>)
Unity Catalog は左側のメニューからアクセスできる包括的なData Explorerを提供します。
すべてのテーブルを探し、アクセス権限を設定できます。スキーマ内に新たなテーブルを追加することもできます。

コード解説
ここでは Unity Catalog のシステムを用いたデータ管理について説明しています。
GUI 上でデータをブラウジングできる点や、SQL を使わずともアクセス制御の設定ができることを確認しましょう。
3. 分析(BI/ウエアハウス/SQL)
Databricks SQL を用いて、ウェアハウス・BI 機能を利用する方法について見ていきます。
伝統的なデータウェアハウスは多彩なデータやユースケースに対応することができません。機械学習の知見を必要とする素早いビジネスにおいては、信頼性の高いリアルタイムデータを求められています。
レイクハウスを使い、データ全体に直接、かつ安全なまま接続できるリアルタイムなBIアプリケーションを利用しましょう。
DatabricksでのBIとウェアハウジング
データセットは完全に取り込まれ、保護され、高品質かつ容易にアクセスできるようになりました。
Databricks SQLがインタラクティブBIによってデータアナリストをサポートし、取引と詐欺の分析を行うところを見てみましょう。
Databricks SQLを始めるには、左メニューのトップからSQLニューを選択します。ここでできるのは、
- クエリを使ってSQLウェアハウスを作る
- DBSQLでダッシュボードを制作
- 分析内容をBIツール(Tableau,PowerBI等)に接続
クエリの作成
ユーザーはSQLエディターでクエリを作成し、可視化をを追加することができます。
オートコンプリートとスキーマブラウザを利用して、アドホッククエリを実行できます。
データアナリストのみならず、様々なペルソナがデータセットを分析するの為に役立ちます。

ダッシュボードの作成
次のステップではクエリを組み合わせ可視化したものをSQLダッシュボードに組み込み、ビジネスで追跡できるようにすることです。
リンクを開いて既存の不正取引パターンを確認しましょう。

サードパーティー BI ツールの利用
統一されたセキュリティモデルとUnity Catalogを用いて、テーブル上で直接クエリを実行できます。アナリストは好きなツールで、完全で新鮮なデータを利用してビジネス インサイトを発見できるようになりました。
サードパーティーのBIツールを利用するには、左下の「Partner Connect」をクリックし、サービス名を選択してください。
コード解説
あらかじめ用意されているテーブルとクエリを用いて、データを取り出すだけでなく可視化を行えることを確認します。
- ノートブックのリンク先にクエリがいくつか用意されているのでそれを実行すればすぐに表示ができる
- クエリを実行してから「+Add visualisation」で可視化
- クエリで作ったグラフを組み合わせてダッシュボードを作り上げる
- ダッシュボードの例も確認
4.モデル作成・リリース(データサイエンス&AutoML)
AutoMLでモデルを作り、デプロイするまで。さらにモデルの改良と性能検証まで行えることを確認します。
4.1 AutoML の実行準備
データを活用して、各取引の不正リスクを評価するモデルを構築する方法を見ていきましょう。
データサイエンティストの最初のステップは、モデルを訓練するために必要な特徴量を分析し構築することです。
顧客データを結合された取引情報のテーブルは Delta Live Table パイプラインに保存されています。あとは読み込んで分析し、AutoML を実行するだけです。
※左メニューから Machine Learning ビューを選択してください
データセットのレビュー
-
データの分析:SQLビューを利用したり、plotで表示したりして確認します
- 詐欺の割合と金額
- 不正取引の割合は全体の3%、総取引額の割合は9%程度
- どのタイプの取引が詐欺なのか
- 引出、振替が50%づつ
- 通常の取引は預入が40%、次いで支払と引出
- 詐欺の割合と金額
-
Feature Store に保存(任意)
特徴量の準備ができたら、Databricks Feature Store に保存しましょう。ストアは Delta Lake table 形式となっています。これにより、組織内での特徴の発見や再利用が可能になり効率が上昇します。
Feature Store はどのモデルがどの特徴量セットに依存しているかを記録しており、デプロイ時の追跡やガバナンスを容易にし、リアルタイムでのサービスも簡略化することができます。
Feature Store にアクセスする際は Machine Learning ビューに切り替えてください。
Feature Store に特徴量を保存すると、別の AutoML エクスペリメントを作成する際に、他のテーブルと特徴量の結合ができるようになったりします。
-
機械学習で使われるpandasフレームに変換
- 不要な属性を除去
- 欠損しているデータを除去
-
AutoMLで機械学習
- Machine LearningタブからExperimentでデータセット(
gold_transactions)と予測したい項目(is_fraud)を選ぶ"だけ" - 1クリックで自動的にノートブックが生成される
- ノートブックにはAPIによるAutoMLの実行コードも掲載
- Machine LearningタブからExperimentでデータセット(
MLflowはモデルトラッキング、パッケージ・デプロイを可能にするオープンソースプロジェクトです。データサイエンティストがモデルを作成する際、Databricksは常にパラメータやデータを追跡、保存します。この機械学習の追跡可能性と再現性によってどのモデルがどのパラメータやデータを用いて作られたか簡単に知ることができます。
MLflowでモデルの管理を簡略化できるが、モデルを新たに作ること自体は時間がかかり非効率的なままです。そこで、毎回プロジェクトごとにコードを書く代わりに、Databricks AutoMLを使うことで分類、回帰、予測のための最先端のモデルを自動で生成することができます。
生成されたモデルを直接デプロイするか、生成されたノートブックをベストプラクティスによって改善することで、数週間分の労力を節約することができます。

4.2 AutoMLの生成例
AutoMLが自動作成したノートブックのサンプルです。これ自体が機械学習の手順について丁寧に解説されたドキュメントになっています。
結果はノートブック形式で出力されます。各工程では何をしているのかが表記されています。
また、後で一部を手動で直したり調整する事も可能です(この後で実際に修正されます)。
Databricks Auto-MLは多数のモデルを試し、モデルを作成するコードを含んだノートブックを自動で生成します。
Auto MLの実験から、最良のノートブックを選びました。
これ以降のコードはすべて自動で生成されたものです。データサイエンティストは、知識に基づいてこれらを調整することができますし、そのまま使用することもできます。
- ノートブック・モデルの説明
- 再現に必要なクラスターの条件などが書かれている
- データセットの読み込み・前処理
- 先頭5データ分だけ中身を表示
- 型がサポートされている行だけが残される
- 削除された要素(IDなど)が表記されている
- データの穴埋め
- 数値型への変換・One-hot化(0,1であらわされるクラスの型に変換)
- データ分割
- 訓練に使うデータ(train)、ハイパーパラメータ調整に使うデータ(validation)、未知のデータに対する性能をチェックするデータ(test)に3分割する
- 割合は60-20-20(train-valid-test)
- 学習
- ログはMLflowで追跡される
- モデルが自動的に保存、バージョン管理される
- ハイパーパラメータを探索する範囲(条件数)は設定可能
- 複数の条件で学習し、一番良かったモデルを選べる
- ログはMLflowで追跡される
- 実験
- 分類を行い、結果(精度)、並びにデータセットの構造(処理された内容)を表示
- SHAPという指標でどの値が予測する際に重要かを表示できる
- shap_enabled = Trueにして再実行すること
- 混同行列、ROC、適合率-再現率曲線による結果のグラフ化
グラフについて
- 混同行列

- 縦軸は正解のクラス(0:不正ではない、1:不正)、横軸はモデルが予測したクラス
- 不正を75%の割合で正しく検知し、25%をこぼしている
- 逆に正常なもののうち7%は誤検知になっている
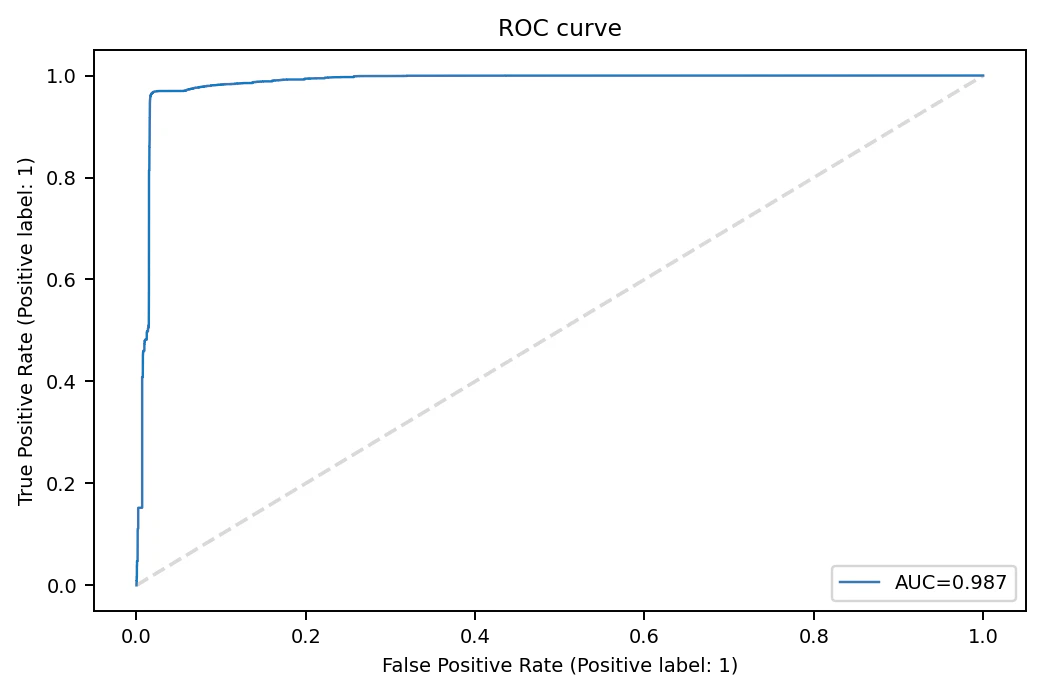
- ROC 曲線

- 不正と判断する閾値を変化させていった(基準を緩くした)場合に、検知率と誤検知率(実際は正常なのに不正と判断)をそれぞれプロットしていったグラフ
- 一番左上に近い点を閾として選ぶと良い
- AUCはグラフの下部分の面積で1に近いほど正確
- Precisiton - Recall 曲線

- 閾値を動かして、縦軸に適合率(不正と予測して実際にそうだった確率)、横軸に再現率(不正が不正だと検知された確率)をプロットしていったグラフ
- APはグラフの下部分の面積で1に近いほど正確
4.3 サービス化
AutoML で作ったモデルをリアルタイムのサービスにデプロイする方法の説明です。こちらもクラスターを用意すれば1クリックでお手軽にできます。
モデルをスケーラブル API の背後にデプロイして、 不正取引の可能性をミリ秒で評価し、リアルタイムで不正を減らしましょう。
AutoMLでモデルが作られれば、簡単に運用準備完了のフラグを立て、Databricks Model Servingに切り替えることができます。
HTTPリクエストを送り、リアルタイムで推論を得ることができます。
Databricks Model Servingはサーバレスで以下のことができます。
- 1クリックデプロイ。Databricsはスケーラビリティに、非常に高速な起動と推論時間を提供します。
- 0までスケールダウンで最高のTCOオプション(エンドポイントが使われてない間は起動しない)
- 複数モデル&バージョンの組み込みをサポート
- 2バージョンへのトラフィック振り分け、比較によるA/Bテスト
- メトリクス、モニタリング機能
- MLflowの機能で、モデルのバージョンをproduction(本番)に変更
- サイドメニューでMachine Learningに切り替えて、Servingタブから1クリックでエンドポイントを作成できる
- ノートブックを実行するとサンプルのデータセットをリアルタイムで送信する事が可能
4.4 モデル改良
生成されたノートブックのモデルを改良する方法について学びます。機械学習に詳しい人はチェックしておきましょう。
データサイエンティストは、不均衡なクラスを調整するロジックを追加すれば、 XGBoost でより良い検知ができることに気が付きました。
生成されたノートブックを改善して、以下の2ステップでバランスの悪いデータセットをよりうまく扱えるようにします。
- 頻度の高いクラスに相対的な重みを持たせる
- モデルを XGBoostに切り替える
- 4.2で生成されたノートブックにsklearnのclass_weightによる数値の処理と、別のモデルである XGBoost への変更を行っている。
- 実際のケースでどうやってAutoMLのコードを改善するかは、データサイエンティストの知識が関わってくる。
- テストの結果、不正の検知率(再現率)は97%に上昇(旧モデルは75%)


4.5 A/Bテスト
改良前後のモデルをA/Bテストして、性能が良くなったことを検証します。
新しいモデルがレジストリに保存されました。
次のステップは、デプロイして期待通りに動作するかを確認することです。新しいバージョンの REST API を用いて、
- 本番環境を停止することなく
- リクエストを新しいバージョンに誘導
- 自動スケーリングと潜在的なバーストをサポートする
- A/Bテストを行い新しいモデルがより良い結果を出していることを確認
- モデルの結果やCPU/負荷などの監視

- リンクからエンドポイントのUIを開き2つめのモデルを追加する
- 20%で新モデルの方に誘導するように設定
- 下のコードを実行してテストし、両モデルの結果をモニタリングする
5. 全自動化(workflow)
テーブル・モデルを自動更新するワークフローの機能についての解説です。ここまで出来ればかなり効率が良くなりますね。
アセットの準備がすべて完了しました。次は、DLTパイプラインを設定してテーブルを更新するタイミングを定める必要があります。
一つは、ストリーミングパイプラインに切り替えて、ほぼリアルタイムでの更新を行う方法です。
もう一つは、一定時間ごとにパイプラインを起動して、増分を取り込んでシャットダウンする方法です。
これは、シンプルに稼働時間と遅延のトレードオフとなります。
ここでは、1時間ごとに新たなデータを取得することがベストだと決めました。
- DLTパイプラインを開始しデータを取り込んでテーブルを更新する
- DBSQL ダッシュボードをリフレッシュ
- モデルを再学習して、潜在的な挙動の変化をとらえる
Databricks Workflowsでパイプラインの自動化
Databricks Lakehouse では、外部のオーケストレータは必要ありません。
Workflows を使って数回のクリックでパイプラインをオーケストリングできます。
ワークフローの作成
タスクはそれぞれ固有のジョブをトリガーできます
- Delta Live Tables
- SQL query/dashbord
- モデル再学習/推論
- ノートブック
- dbtなど…
この例では3つのタスクがあります。
- DLT パイプラインを起動し、差分データを読み込む
- DBSQL ダッシュボードの更新
- モデルの再学習
他にはエラーログなどの確認などWorkflow機能の紹介
まとめ
以上がdbdemosの翻訳ならびに解説となります。
このデモではDatabricksが一通りできることを、一つのシステム開発を通じて解説しており、幅広い方法でのデータ活用ができることが分かります。
デモ自体も、必要なものはすべて自動でインストールされるため動いている所をすぐに確認することができるのがかなり強いです。
dmdemosにはこれ以外にも複数のデモが用意されているので、気になった人はdbdemos.list_demos()を打ち込んで気になるデモを探してみましょう。