Comet.mlとは
こちらが,Comet.mlのHPです.
簡単に言えば,モデルの学習を可視化して管理するための機械学習の実験支援ツールです.
可視化の様子は上記のHPに簡単なデモ動画が用意されているので,そちらを参照しましょう.
今回用いたモデル
今回はgithubから,以下のORCNNというモデルを使用しました.
今回の記事は学習プロセスが1つの場合について説明しています.複数プロセスの場合は,この記事に加えて他の知識も必要になりますので注意してください
このリポジトリはアメリカ合衆国のWaiyu Lamさんによって作成されました.
このモデルのtrainの過程をComet.mlで可視化するための技術についてまとめていきたいと思います.
なお,このリポジトリにはdetectron2が含まれていますが,ImportError解決のために,改めて公式のdetectron2のリポジトリをクローンしなおしています.
なぜComet.mlが必要?
- まず,
ORCNN/toolsのREADME.mdを見てみるとdetectron2の内蔵モデルを学習するための学習スクリプトの例として,train_net.pyが紹介されており,このファイルをORCNN/GETTING_STARTED.mdコマンドを参考に動かすことで,trainのループが始まるようになっています. - うまくいけば,下記のような出力が大量に(各iterationごとに)出てくるはずです.
[04/12 09:43:40 d2.utils.events]: eta: 8 days, 19:05:55 iter: 19 total_loss: 1.932 loss_cls: 0.4236 loss_box_reg: 0.01658 loss_mask: 0.693 loss_rpn_cls: 0.6818 loss_rpn_loc: 0.1441 time: 2.6872 last_time: 2.6050 data_time: 0.4750 last_data_time: 0.3432 lr: 0.00039962 max_mem: 18286M
[04/12 09:44:37 d2.utils.events]: eta: 8 days, 21:23:19 iter: 39 total_loss: 1.904 loss_cls: 0.5555 loss_box_reg: 0.0516 loss_mask: 0.6887 loss_rpn_cls: 0.4362 loss_rpn_loc: 0.1668 time: 2.7533 last_time: 3.2054 data_time: 0.4584 last_data_time: 0.8729 lr: 0.00079922 maxs the indexing argument. (Triggered internally at ../aten/src/ATen/native/TensorShape.cpp:3549.)_mem: 18286M
[04/12 09:45:34 d2.utils.events]: eta: 8 days, 21:48:13 iter: 59 total_loss: 1.579 loss_cls: 0.3354 loss_box_reg: 0.0846 loss_mask: 0.6902 loss_rpn_cls: 0.6818 loss_rpn_loc: 0.1441 time: 2.6872 last_time: 2.6050 data_time: 0.4750 last_data_time: 0.3432 lr: 0.00039962 max_mem: 18286M loss_rpn_cls: 0.3072 loss_rpn_loc: 0.1403 time: 2.7851 last_time: 3.0831 data_time: 0.4133 last_data_time: 0.6181 lr: 0.0011988 max_ loss_rpn_cls: 0.4362 loss_rpn_loc: 0.1668 time: 2.7533 last_time: 3.2054 data_time: 0.4584 last_data_time: 0.8729 lr: 0.00079922 max_mem: 18286Mmem: 18287M
- しかし,この数字や文字の列が各iterationごとに表示されるだけでは,lossの減少傾向や学習の良し悪しなどを一目で判断することはできません.
- もしかしたら,「データセットやバッチ数の関係で学習に失敗してlossが思うように変化しなかった」なんてこともあるかもしれません.
- そういった管理をしやすくするためにグラフ形式にして可視化してくれるのがComet.mlです.
lossの変化率などが一目でわかるようになり,学習の良し悪しを評価しやすくなります. - また,学習全体を通してどのようにlossが変化していったかなど指標の変化を観察することができます.
hooksとは(事前知識)
これから説明するtrainの構造の事前知識として,hooksという概念を紹介します.
もう知っているという方は飛ばしてもらっても結構です.
hooksとは,プログラムの特定の箇所に利用者が独自の処理を追加できるようにする仕組みです.(Wikipedia)
つまり,「利用者がこのタイミング(特定のイベント)でこの処理をプログラムにさせたいよ」というのを独自に追加できるシステムのことです.
callbacksと言った方が馴染みがある人がいるかもしれません.
detectron2を用いたプログラムではそのような機能のことを,hooksと定義していて記述したり登録して使用しています.
必要なファイルを作成
VSCodeなどのテキストエディタ上のコードを実行した際にComet.mlを使用できるようにする際にいくつか準備が必要なファイルがありますので,一緒にみていきましょう.
.comet.configの作成
Cometを利用できるようにするために設定ファイルをルーとディレクトリの下に置く必要があります.
ファイル名を.comet.configにして下記のように作成しましょう.
いくつか自作モジュールを作成しますので,train_net.pyで忘れずにimportしておきましょう.
https://www.comet.com/docs/v2/api-and-sdk/python-sdk/advanced/configuration/
# api_key should be in "~/.comet.config", NOT HERE!
[comet]
workspace=workspace_name #自身のものに変更
project_name=orcnn-training
[comet_logging]
hide_api_key=True
display_summary_level=0
file=comet_logs/comet-{project}-{datetime}.log
# [comet_fallback_streamer]
# keep_offline_zip=True
[comet_auto_log]
env_details=True
env_gpu=True
env_host=True
env_cpu=True
cli_arguments=True
graph=True
metrics=True
workspace_nameは自身のものに変更してください.
loggerフォルダを作成する
このフォルダでは,Cometにログを送る際の設定などがされています.
例えば,Comet.mlのExperimentsの名前などをここで指定できたり,タグをつけることもできます.
あまり説明の本質ではない気もするので,とりあえず同じ物を作成して使ってみて,理解が
深まってから色々いじってみてもいいかもしれません.
とりあえず,以下のディレクトリ構造を作成しましょう.
ORCNN/
│
├── my_logger/
│ ├── __init__.py
│ ├── logger_pl.py
│ └── logger.py
│
└── ・・・
それぞれのコードを下記に掲載しておきます.
from .logger import configure_logger
from .logger_pl import configure_logger_pl
__all__ = [
'configure_logger',
'configure_logger_pl'
]
from datetime import datetime
from comet_ml import Experiment
def configure_logger(
logged_params: dict,
model_name: str,
disable_logging: bool,
) -> Experiment:
"""comet logger factory
Args:
logged_params (dict): hyperparameters to be logged in comet.
Typically "vars(args)" for logging all parameters in "args".
model_name (str): modelname to be added as a tag of comet experiment
disable_logging (bool): disable comet Experiment object
Returns:
comet_ml.Experiment: logger
"""
# Use ./.comet.config and ~/.comet.config
# to specify API key, workspace and project name.
# DO NOT put API key in the code!
experiment_logger = Experiment(disabled=disable_logging)
exp_name = datetime.now().strftime("%Y-%m-%d_%H:%M:%S:%f")
experiment_logger.set_name(exp_name)
experiment_logger.add_tag(model_name)
experiment_logger.log_parameters(logged_params)
return experiment_logger
from typing import Tuple
from datetime import datetime
from comet_ml import Experiment
from lightning.pytorch.loggers import CometLogger
def configure_logger_pl(
model_name: str,
disable_logging: bool,
save_dir: str,
) -> Tuple[Experiment, str]:
"""comet logger factory
Args:
model_name (str): modelname to be added as a tag of comet experiment
disable_logging (bool): disable comet Experiment object
save_dir (str): dir to save comet log
Returns:
comet_ml.Experiment: logger
str: experiment name of comet.ml
"""
exp_name = datetime.now().strftime("%Y-%m-%d_%H:%M:%S:%f")
exp_name = exp_name.replace(" ", "_")
# Use ./.comet.config and ~/.comet.config
# to specify API key, workspace and project name.
# DO NOT put API key in the code!
comet_logger = CometLogger(
save_dir=save_dir,
experiment_name=exp_name,
parse_args=True,
disabled=disable_logging,
)
comet_logger.experiment.add_tag(model_name)
return comet_logger, exp_name
-
logger_pl.pyはpytorch lightningを使用している人向けなので,必要ない人は削除してしまっても大丈夫です. - そうして,
train_net.pyに下記のような記述を追加してください.
def main(args):
cfg = setup(args)
logger = configure_logger(
logged_params=vars(args),
# model_name=args.model_name
model_name="ORCNN",
disable_logging=args.disable_comet,
)
・・・
return trainer.train()
- さて,ここまででCometにtrainの過程を可視化するための下準備が整いました.
次からは,実際のtrainのloopの中でCometにログを送るためのコードの埋め込み方についてみていきましょう.
trainの構造
Comet.mlの可視化を利用するにあたって説明のためにまずは,ORCNNがどのようにtrainを回しているかを把握しないといけません.
trainを回すための実行ファイルであるtrain_net.pyから,trainの核となるmain関数抜き取ってみます.
def main(args):
cfg = setup(args)
if args.eval_only:
model = Trainer.build_model(cfg)
DetectionCheckpointer(model, save_dir=cfg.OUTPUT_DIR).resume_or_load(
cfg.MODEL.WEIGHTS, resume=args.resume
)
res = Trainer.test(cfg, model)
if comm.is_main_process():
verify_results(cfg, res)
if cfg.TEST.AUG.ENABLED:
res.update(Trainer.test_with_TTA(cfg, model))
return res
"""
If you'd like to do anything fancier than the standard training logic,
consider writing your own training loop or subclassing the trainer.
"""
trainer = Trainer(cfg)
trainer.resume_or_load(resume=args.resume)
if cfg.TEST.AUG.ENABLED:
trainer.register_hooks(
[hooks.EvalHook(0, lambda: trainer.test_with_TTA(cfg, trainer.model))]
)
return trainer.train()
ここで最後のreturn文のtrainer.train()のtrain()の定義へ移動(⌘+クリック)すると,このtrain_net.pyでも使用しているDefaultTrainer(TrainerBase)クラスの定義をしている以下のようなファイルの部分に飛ぶはずです.
また,trainer.register_hooksで作成したhooksを登録することができます.
class DefaultTrainer(TrainerBase):
・・・
def train(self):
"""
Run training.
Returns:
OrderedDict of results, if evaluation is enabled. Otherwise None.
"""
super().train(self.start_iter, self.max_iter)
if len(self.cfg.TEST.EXPECTED_RESULTS) and comm.is_main_process():
assert hasattr(
self, "_last_eval_results"
), "No evaluation results obtained during training!"
verify_results(self.cfg, self._last_eval_results)
return self._last_eval_results
ここで,またこのクラスが継承しているTrainerBaseクラスのtrain関数が呼び出されていますので,また定義に移動(⌘+クリック)して,中身を確認して見ましょう.
class TrainerBase:
・・・
def train(self, start_iter: int, max_iter: int):
"""
Args:
start_iter, max_iter (int): See docs above
"""
logger = logging.getLogger(__name__)
logger.info("Starting training from iteration {}".format(start_iter))
self.iter = self.start_iter = start_iter
self.max_iter = max_iter
with EventStorage(start_iter) as self.storage:
try:
self.before_train()
for self.iter in range(start_iter, max_iter):
self.before_step()
self.run_step()
self.after_step()
# self.iter == max_iter can be used by `after_train` to
# tell whether the training successfully finished or failed
# due to exceptions.
self.iter += 1
except Exception:
logger.exception("Exception during training:")
raise
finally:
self.after_train()
def before_train(self):
for h in self._hooks:
h.before_train()
def after_train(self):
self.storage.iter = self.iter
for h in self._hooks:
h.after_train()
def before_step(self):
# Maintain the invariant that storage.iter == trainer.iter
# for the entire execution of each step
self.storage.iter = self.iter
for h in self._hooks:
h.before_step()
def after_backward(self):
for h in self._hooks:
h.after_backward()
def after_step(self):
for h in self._hooks:
h.after_step()
ここで,trainのloopの大元に辿り着くことができました.
中身を順番に見て行くことにしましょう.
1.最初はloggerの設定や,iteration (train loopを繰り返す回数)の設定を行っています.
2.with EventStorage(start_iter) as self.storage:は,EventStorageクラスのインスタンスを作成して,それをself.storageという変数で使用できるようにしています.
EventStorageは簡単に説明するならば,学習中のメトリクスやイベントを記録および追跡するために定義されたクラスです.
3.その後は,train_loopが実行されるためのコードになっています.
-
def before_train()これは、トレーニングが開始される前に実行される処理を実行するための関数です。例えば、トレーニングの前にデータの準備やモデルの初期化などが行われます。 -
def before_step()これは、各トレーニングステップの前に実行される処理を実行するための関数です。各イテレーション(ステップ)の前に、データのバッチ処理やモデルの更新前の準備が行われます。 -
def run_step()これは、実際のトレーニングステップ(イテレーション)を実行するための関数です。モデルのパラメータを更新し、損失を計算するなど、トレーニングの中核部分がここで行われます。 -
def after_step()これは、各トレーニングステップの後に実行される処理を実行するための関数です。例えば、トレーニングの進捗を表示したり、ログを記録したりします。 -
def after_train()これは、トレーニングが終了した後に実行される処理を実行するための関数です。トレーニングが終了した後の後処理や、結果の保存などが行われます。
4.次に3.で説明したそれぞれの関数が定義されています.
- この関数の中身を見ると,ここで定義している関数はすべてhooksを利用していることがわかります.
- つまり,この関数で定義されているtrainのloopのタイミングであれば,独自の機能を追加して
train_net.pyで登録すれば,それをtrainのloopに反映させることができます.
ここまでくると分かった人もいるかもしれませんが,つまり各iterationごとにlossの値などを取得して,それをCometのログを残すようなhooksを独自に作成して登録してしまえばいいのです.上記で挙げた5つの関数のうち,各iterationごとにtrainのロスなどの情報を持っている関数(step)はafter_stepであることは自明です.
ですから,次の説明からafter_stepでCometにログを残すコードの書き方を見ていきましょう.(つまり自作の`hooksを作成して登録するところまで)
自作hooksの作成
ここからはafter_step関数でCometにログを残すためのhooksの作成方法について解説していきます.
まず新しいフォルダを作成して,以下のようなディレクトリ構造を作成してください.
ORCNN/
│
├── my_hooks/
│ ├── __init__.py
│ └── my_logger_hooks.py
│
└── ・・・
- それぞれのファイルの簡単な意味としては
my_logger_hooks.pyで自作hooksを作成して,__init__.pyを用いて自作モジュールとして扱えるようにします. - これからそれぞれのファイルの中身を見てみましょう.しかしあくまでこれは一例になりますので,ここで得た知識をもとに自分で目的に合うように書き換えてください.
- また,trainのlossなどの情報をどうやって持ってくるかは
detectron2/utils/events.pyのコードが参考になりますので自作で作成するときはそちらも参考にしてください. - また,注意点としてクラスを自作する際に
HookBaseを継承していないとエラーが出る場合があるので必ず継承するようにしましょう.
from detectron2.utils.events import get_event_storage
from detectron2.engine.train_loop import HookBase
class MyLoggerHooks(HookBase):
def __init__(self, logger):
self.logger = logger
def after_step(self):
storage = get_event_storage()
# ログを残すコードを書く
# get_event_storage(でロスとかを残す)
# detectron2/utils/events.py def write(self)を参考に作成する
self.losses = " ".join(
[
"{}: {:.4g}".format(
k, v.median(storage.count_samples(
k, self._window_size))
)
for k, v in storage.histories().items()
if "loss" in k
]
)
print(self.losses) #これはいらないかもです
このようにafter_step関数で,lossを取得してloggerを通してCometにログを残すためのhooksを作成しました.
そして,これを異なるファイルから自作モジュールとして利用できるようにするために,__init__.pyを作成しましょう.
下記に_init__.pyの例をしまします.
from .my_logger_hooks import MyLoggerHooks
__all__ = [
'MyLoggerHooks'
]
これで自作のhooksを異なるファイルで利用できるようになりました.
後は,train_net.pyで自作のhooksを下記のように登録したらCometでtrainの過程が可視化されるはずです.
def main(args)
・・・
trainer = Trainer(cfg)
trainer.resume_or_load(resume=args.resume)
if cfg.TEST.AUG.ENABLED:
trainer.register_hooks(
[hooks.EvalHook(
0, lambda: trainer.test_with_TTA(cfg, trainer.model))]
)
trainer.register_hooks(
[MyLoggerHooks(logger)]
)
return trainer.train()
追記(argsの設定)
上の設定に加えてargsの設定をすることをすっかり忘れていました.
tools/train_net.pyを開いて下の方に行くと,このような記述があります.
if __name__ == "__main__":
args = default_argument_parser().parse_args()
print("Command Line Args:", args)
この上記の2行目のdefault_argument_parser()関数の定義に移動してみると,
def default_argument_parser():
"""
Create a parser with some common arguments used by detectron2 users.
Returns:
argparse.ArgumentParser:
"""
parser = argparse.ArgumentParser(description="Detectron2 Training")
parser.add_argument("--config-file", default="",
metavar="FILE", help="path to config file")
parser.add_argument(
"--resume",
action="store_true",
help="whether to attempt to resume from the checkpoint directory",
)
parser.add_argument("--eval-only", action="store_true",
help="perform evaluation only")
parser.add_argument("--num-gpus", type=int, default=1,
help="number of gpus *per machine*")
parser.add_argument("--num-machines", type=int, default=1)
parser.add_argument(
"--machine-rank", type=int, default=0, help="the rank of this machine (unique per machine)"
)
parser.add_argument(
"-en",
"--experiment_name",
type=str,
help="name of experiment",
)
# PyTorch still may leave orphan processes in multi-gpu training.
# Therefore we use a deterministic way to obtain port,
# so that users are aware of orphan processes by seeing the port occupied.
port = 2 ** 15 + 2 ** 14 + hash(os.getuid()) % 2 ** 14
parser.add_argument(
"--dist-url", default="tcp://127.0.0.1:{}".format(port))
parser.add_argument(
"opts",
help="Modify config options using the command-line",
default=None,
nargs=argparse.REMAINDER,
)
return parser
このような記述があります.ここは実行時に指定できるargsのデフォルト値を設定しているところです.
そこに下記のような記述をreturn文の前に追加してください.
parser.add_argument(
"-en",
"--experiment_name",
type=str,
help="name of experiment",
)
parser.add_argument(
"-et",
"--experiment_tag",
type=str,
help="tag of comet experiment",
)
parser.add_argument(
"-d",
"--dataset",
type=str,
choices=["coco_2017_train"],
help="select dataset",
)
parser.add_argument(
"--disable_comet",
"--no_comet",
dest="disable_comet",
action="store_true",
help="do not use comet.ml (default: use comet)",
)
そしてスクリプトファイルで下記のようにargsを指定するようにすると,cometに関する様々な設定を実行時に行うことが出来ます.
export PYTHONPATH=YOUR/PYTHON/PATH
export CUDA_VISIBLE_DEVICES=2
python tools/train_net.py --config-file "configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"\
--experiment_name "train" \
--experiment_tag "ORCNN Train" \
--dataset "coco_2017_train"\
SOLVER.IMS_PER_BATCH 2 SOLVER.BASE_LR 0.0025
ここまでの変更を行って実際にcometを見に行ってみましょう.
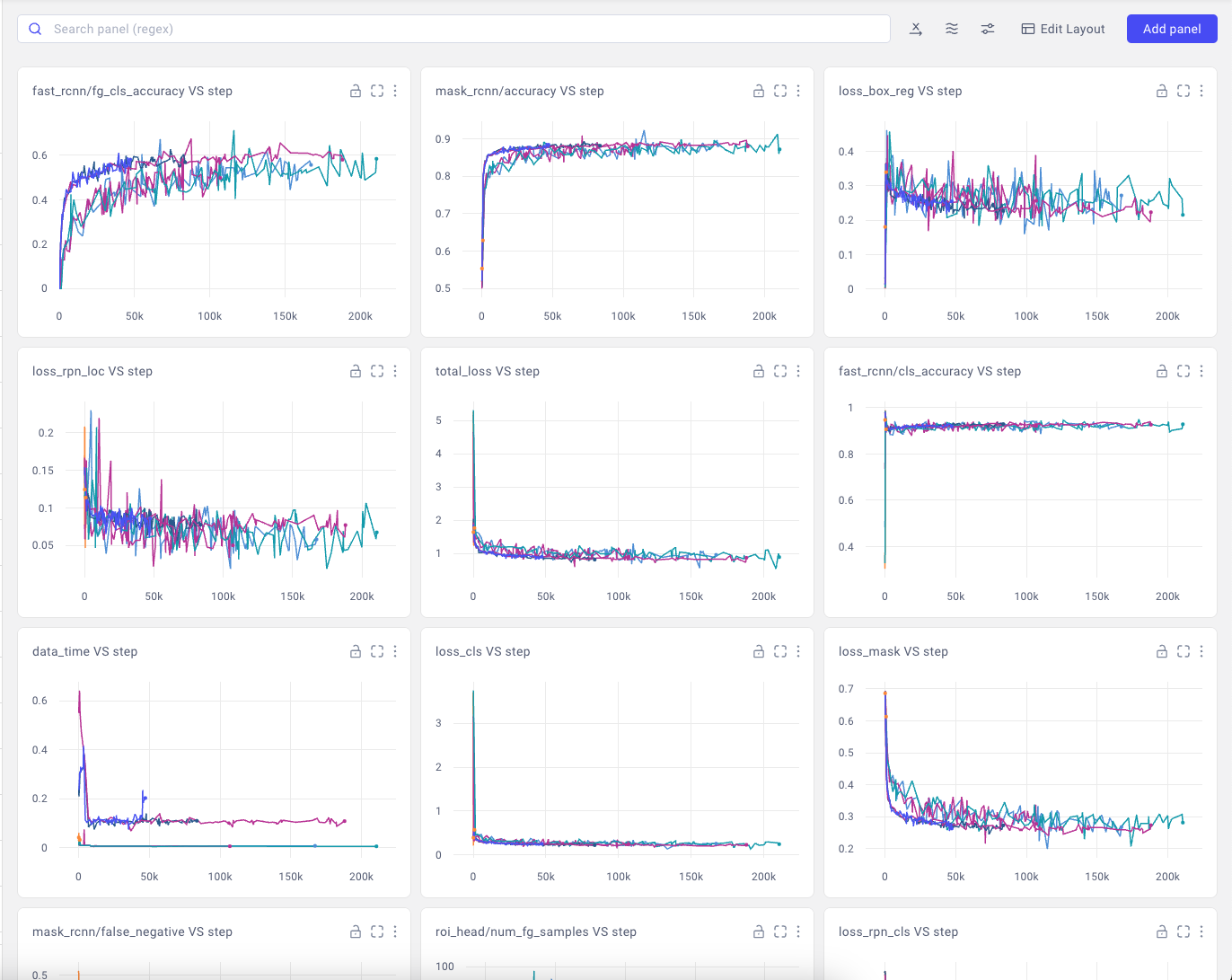
このように,折れ線グラフみたいなものがいくつか表示されて,lossの減少具合などがひと目でわかる様になっています.
これでモデルの学習がcometでしっかり見れるようになりました.
まとめ
今回はgithubからORCNNという学習プロセスが1つのモデルを持ってきて,そのtrainの様子をComet.mlで可視化できるようになるまでの工程を解説してみました.
意外と変更するところが多くて大変でしたが,1つ1つをしっかり理解すれば大丈夫です!
今回の記事は,学習プロセスが1つだけのモデルを扱いましたが,今は複数プロセスを必要とする学習プロセスの可視化を行なってますので,完了次第記事にまとめたいと思います.
この記事が誰かのお役に立てれば幸いです.