はじめに
CARLA Autonomous driving challenge 2024https://opendrivelab.com/challenge2024/ にて入賞したTransFuser++の元論文を紹介します。実際の入賞モデルについて書かれた論文は"Hidden Biases of End-to-End Driving Datasets"になりますが、これはデータセットについて書かれたものなので、アーキテクチャの設計思想についてはこちらの論文の方が詳しく解説されています。
論文情報
タイトル:Hidden Biases of End-to-End Driving Models
著者:Bernhard Jaeger, Kashyap Chitta, Andreas Geiger
公開情報:ICCV 2023
論文URL:https://arxiv.org/abs/2306.07957
要旨
End to Endの運転システムは、CARLAにおいて急速な進歩を遂げているが、その主要因は明確でない。この論文では、ほぼすべてのSoTaモデルで進歩の要因となっている2つのバイアスを特定する。そしてこれらのバイアスの欠点を調査し、代替手法を取り入れたTF++を提案する。このモデルはLongest6 および LAV ベンチマークで第1位を獲得した。
論文の貢献
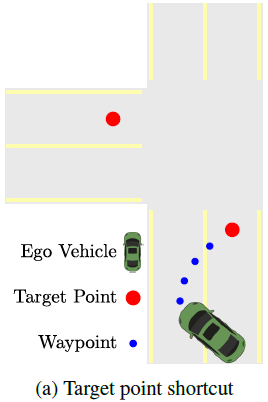
- Target pointを入力とするモデルでは、車両をレーン中心へ復帰させるショートカット学習が起きる事を示す。
→Target pointとは、マップ情報をもとにレーン中心に置かれる通過目標点。
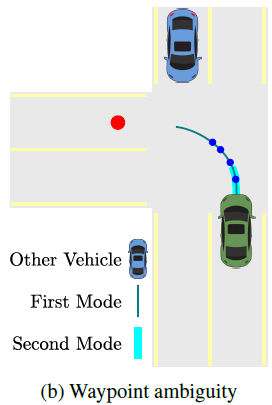
- Waypointによる出力は曖昧さ(停止・回避など明確な意味を持たない)を有するが、その連続的な性質によって滑らかに減速することができることを示す。
→Waypointとは、End-to-Endモデルから出力される時間(または距離)等間隔な点列であり、目標軌跡を示している。これは明確な意味を持たないが、特定の条件において徐々に間隔を狭めたりするため、結果的に減速という安全動作が出力される。
- 実験から得た知見を基に、TF++を提案する。このモデルはLongest6(最長距離ルートにおける走行性能と安定性を測るCARLAの高難度ベンチマーク)および LAV(未知の町と天候下での汎化能力を評価するCARLA自動運転ベンチマーク) ベンチマークで第1位を獲得した。
End-to-End自動運転における隠れたバイアス
問題設定
- メトリクス:CARLA online metricsを使用。ルートを完走できた割合を示すRoute Completion
(RC)と、違反行動により1.0から減点されていくInfraction Score (IS)の積であるDriving Score (DS)を使用。 - ベースライン:TransFuserを改良して利用する。主な変更点は、360°Lidarの導入と、2倍速で走行させたデータセット。
https://arxiv.org/abs/2205.15997 - ベンチマーク:CARLA LAVを使用。
ショートカット学習によるルート復帰 [バイアス1]
- CARLAにおける評価タスクでは、累積誤差からの復帰が求めれる。
累積誤差:モデルの出力が徐々に誤りを増幅させ、時間とともに性能が悪化していく現象。学習時は正しい軌跡上でしかデータ収集しないため、モデルはルートから外れた場所から復帰できない。 - 一般的には学習データの入力に意図的なズレを加える手法が用いられるが、CARLAにおけるSotAモデルではこのような加工は行われていない。
- 対象のTransFuserをTarget point(TP)と、車両がとるべきアクションをワンホットベクトルにしたNavigation command(NC)を入力としてそれぞれ学習させたところ、TPではDSとRCが上昇、1kmあたりの違反"Dev"は0であった。

+ TPを用いたモデルでは、学習分布外(ルートから外れている)の状況でもTPに向かってwaypointが生成された。これは、定期的にTP側に操舵が切られることによって誤差がリセットされるからであり、"ショートカット学習"であると考えられる。

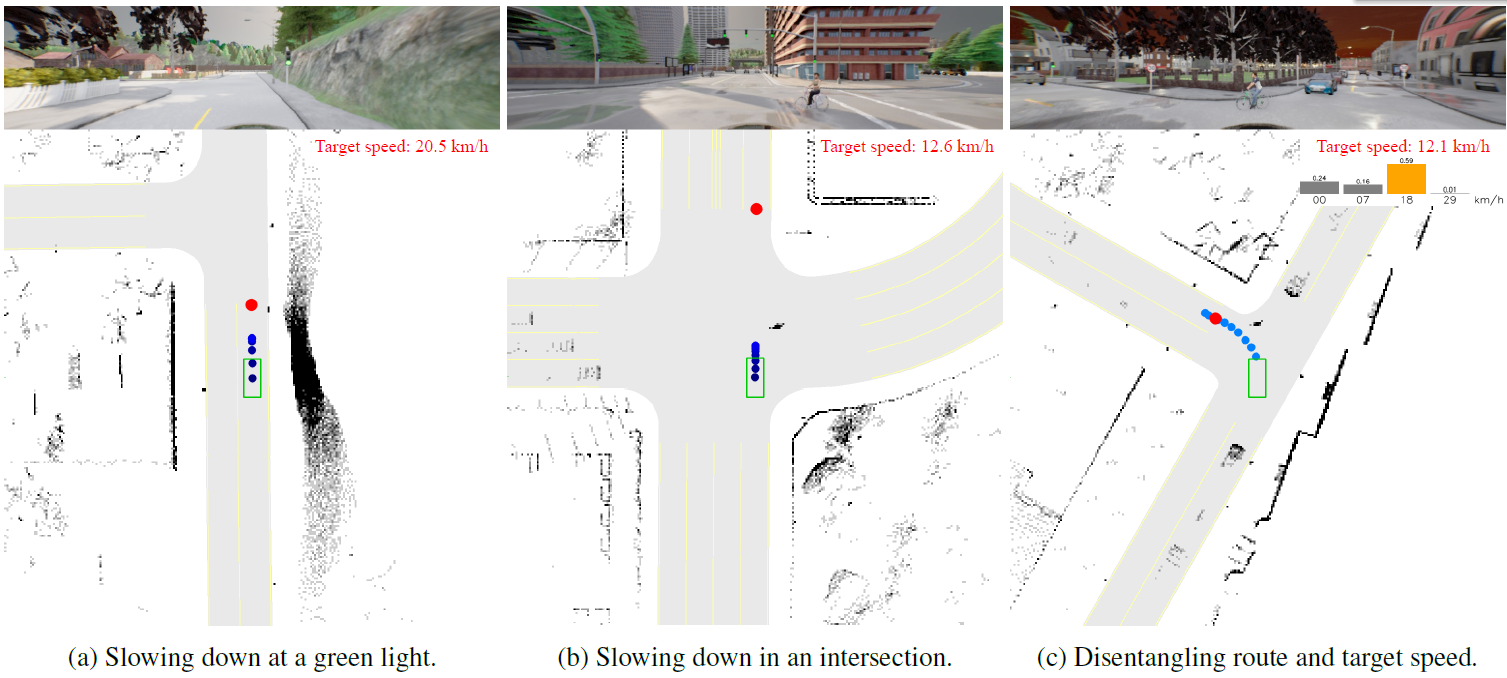
- 上記特性はTPが十分に近い場合は有用であるが、遠い場合は逆に致命的なエラーの原因になる可能性がある(下図(a),(b))。

プーリングの改良とデータ拡張 [バイアス1の欠点の改良]
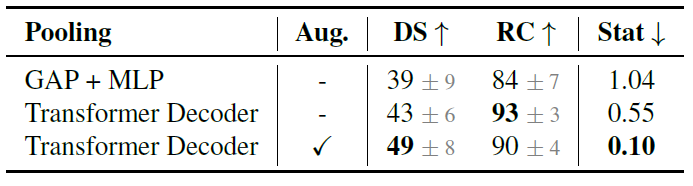
- SotAモデルのアーキテクチャで異なるのは、Encoder/Decoder間のプーリング処理である。このプーリング処理には平均プーリングのものとattentionを用いたものがあるが、平均プーリング型では上図(a)(b)のようなエラーが観測される。これは平均プーリングによって空間的な特徴が失われるためであると考えられる。
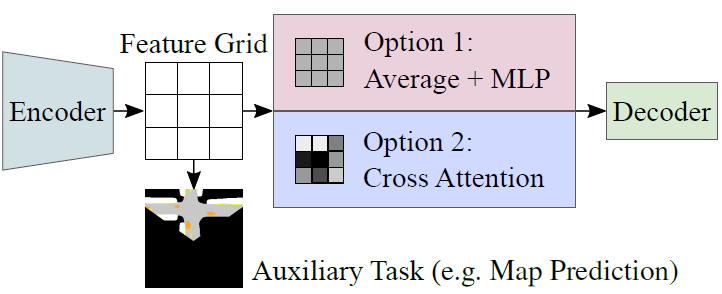
- 一方で、attentionを用いたプーリングでは位置エンコーディングによって空間的な特徴が保持されるため、このようなエラーを回避する効果が期待できる。TransFuserをglobal average pooling (GAP)とMLPを用いた場合、Transformer Decoderを用いた場合でそれぞれ学習させたころ、スコアの向上が見られた。また、Transformer Decoderでは、上図(c)のようにTPショートカットの影響を受けずにレーンを走行するパスが出力されることを確認した。
Waypointの曖昧性 [バイアス2]
- waypointから計算される目標車速を計測した所、エキスパートの設定車速は走行モードに応じた四種類しかないのにも関わらず、モデルの出力は広い範囲に分布していた。
→モデルの出力が特定のモードを表さない曖昧な形になっている。
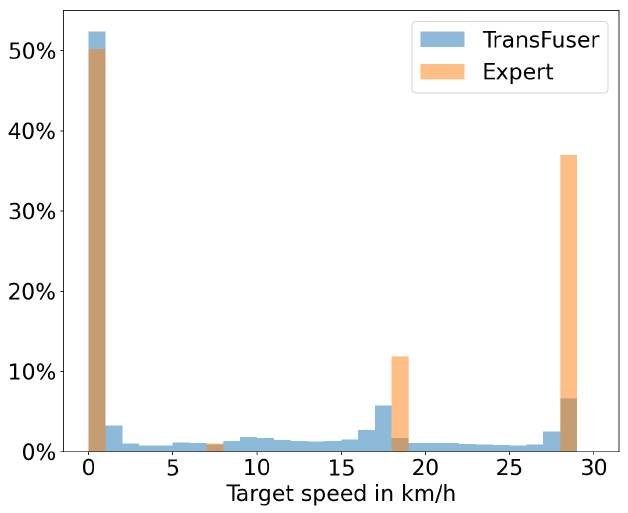
- エキスパートの将来軌跡は決定的であるが、速度はマルチモーダルである。これをwaypontとして同時に出力するため、曖昧な表現になる。つまり、ある瞬間のシーンから発生しうるその後の車速のパターンは複数あるが、waypointは一つの点列でそれらの可能性を表現している。下図(a)(b)では、青信号や交差点で減速される様子が確認できる。
→最も可能性の高い車速で出力しているようにも思えますが、明示的に車速の確立推定はしていないといったところでしょうか。
- これらの曖昧性は有益な場合もあるが、モデルの説明性を欠くため好ましくない。また、停止時には操舵角を設定することができない。
- 上記課題を解決するため、モデルの出力を"距離等間隔なパス"と"エキスパートの設定車速の予測値"にする。
- 上記出力を用いたところ、他車との衝突率"Veh"はわずかに増加したものの、停止障害物への衝突率"Stat"は減少し、運転スコア"DS"が増加した。

- 上記出力を用いたところ、他車との衝突率"Veh"はわずかに増加したものの、停止障害物への衝突率"Stat"は減少し、運転スコア"DS"が増加した。
TransFuser++への拡張
- 上記の分析結果を取り込み、下記のTransFuser++へ拡張する。

学習スケジュール
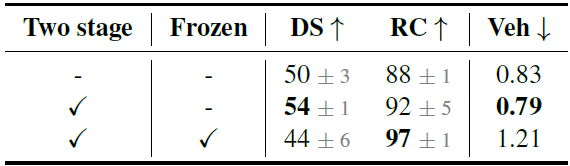
- エポック数を単に倍にしてもスコアに変化は見られなかったが、補助タスクで事前学習された特徴量でバックボーンを初期化し、2ステージを使った学習を行った所、スコアの向上が見られた。
- 試しにバックボーンをフリーズしてDecorderのみを学習させたところ、スコアが低下した。
データセットのスケール
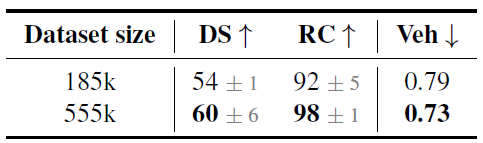
- このなる交通状況でルートを3回走行し、データのスケールアップを行った所、スコアの向上が見られた。
→模倣学習のアプローチは大規模データセットにおいても有用である。
SotAモデルとの比較
比較対象モデル:
-
Interfuser
マルチカメラとLiDARをCNNでエンコード、特徴gridをTransfomerに入力し、Perception結果とPathを出力する。その後、ヒューリスティックコントローラー"Safety Controller"によって制御を修正する。

https://arxiv.org/abs/2207.14024
-
Perception PlanT
モジュラーベースのモデルであり、Bounding boxからTransfomerエンコーダを用いてWaypointを出力する。PerceptionモジュールにはTransFuserが用いられている。

https://arxiv.org/abs/2210.14222
-
TCP
フロントカメラのみを用いたモデル。Trajectoryと制御量を同時に出力し、条件に応じて切り替える(旋回中は制御量の出力を用いる)。

https://arxiv.org/abs/2206.08129
-
TransFuser
カメラ入力とLiDAR BEVをそれぞれCNNで処理しつつ、間でTransformerを用いた特徴量の情報交換を行う。デコーダーの前に平均プーリングを用いた特徴量削減を行う。

https://arxiv.org/abs/2205.15997
-
LAV
マルチカメラとLiDAR点群からBEV中間表現を生成。自車だけではなく、周辺車両のパスも予測することでLabelをかさましする。自車軌跡はNCベースのGRUでまず予測し、TPベースのGRUで修正する。


https://arxiv.org/abs/2203.11934
-
WOR
模倣学習と強化学習の中間に位置する手法である。まずデータセットを用いてMDPにおける状態遷移関数を予測するモデルを学習し、そのモデルと動的計画法を用いて価値関数Qを定義する。Qを最大化する方策を教師データとする。NCを用いた最も高性能なベースラインである。

https://arxiv.org/abs/2105.00636
ベンチマーク
Longest6だけでは一時停止標識の無視に対するペナルティがなく、未知の町への汎化性能を測定していないため、LAVでの評価も実施した。

データセット
TF++はTransfuserと同じルートで、改良されたアルゴリズムを用いたエキスパートでデータ収集を行った。
結果
- NC入力とするモデルの中で最も有力なWORは、TPを入力とするモデルに対してスコアが非常に低い結果となった。
- TF++はLongest6においてその他のベースラインの性能を超えた。また、SotAモデルであるPerception PlanTと比較して、19%の改善が見られた。
- ベースラインであるTransFuserと比較して、同程度の処理時間に抑えつつも圧倒的な性能改善が見られた。

結言
- SotAモデルがTPによる強いバイアスによって高い性能を発揮している音を示した。
- LAV、Longest6において新たなSotAモデルとなるEnd-to-Endモデル"TF++"を提案した。
残課題:
- この研究はCARLAにおける都市部での運転を対象としており、低速域(< 35km/h)で実施している。
- レーンは停止障害物の無い状態で検証しているため、障害物周りのナビゲーションはシナリオに含まれていない。
- 復帰に関してTPに強く依存しているため、正確な自己位置推定が求められる。
おわりに
紹介したTransfuser++ですが、下記リポジトリにて2024年入賞チームの学習済みモデルを動作させることができます。Linux PCであれば基本的に手順通り動作出来るはずですが、WSL環境ではCARLAの起動に少し苦労したため、今後方法を記事にしてみたいとと思います。
https://github.com/akodama428/carla_garage