はじめに
画像のみを入力としてbird's-eye-view表現を予測するモデルとしてよく知られる、LSSについて解説します。近年のSotAモデルと比較すると性能は劣るものの、CNNのみを用いるモデルのため軽量です。そこで自宅のPCでも学習ができるのではないかと思い、シミュレータ上でClosed Loop検証をする事を目標に取り組んでいます。本記事では、論文の内容のみ概説します。
内容要約
- 複数カメラ画像からEnd-to-EndでBEV表現を生成する「Lift-Splat-Shoot」アーキテクチャを提案
- 画像ピクセルの深度を固定幅の深度ビンとして確率的に扱うことで、BEVボクセルとの一意な対応付けを可能にした
- 内外部パラメータと深度ビンに基づく幾何変換は非学習(決定的)で、深度分布と特徴は学習で推定するため、異なるカメラでも同一モデルで推論可能。
- BEV表現をコストマップとして利用し、テンプレート軌跡から最適経路を選択するEnd to Endプランニングを実装した。

論文情報
タイトル:Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
著者:Jonah Philion, Sanja Fidler
公開情報:ECCV 2020
論文URL:https://arxiv.org/abs/2008.05711
要旨
- 複数のカメラから得られた画像から、bird's-eye-view(BEV)表現を抽出するEnd to Endのアーキテクチャを提案する。
- "lift"で個別のカメラ画像から特徴量のフラスタムを抽出し、"splat"でBEVグリッド表現に特徴を潰す(複数画像/ピクセルから得られる同じBEV座標上の特徴や、Z軸方向の情報をひとつの特徴量に統合する)、"shooting"でテンプレートから軌跡を選択し、BEVコストマップ上に展開する事で解釈性の高いプランニングを行う。
lift : 一般に、2Dの情報を3D空間に持ち上げること。
フラスタム : 画像に深度を追加すると角錐型になるため、このように呼ばれる - 複数のカメラ情報を、キャリブレーション誤差に対してロバストに、BEV表現にフュージョンすることができる。
論文の貢献
- 下記3つの"対称性"を満たす、End to Endに微分可能な(プランニングの結果をパーセプションに逆伝播できる)アーキテクチャを提案する。
- Translation equivariance : 入力画像をシフトすると、その分出力もシフトされる。
- Permutation invariance : 出力はカメラの順序に依存しない
- Ego-frame isometry equivariance : カメラがego座標上のどこにあっても、同じ物体が検出される。
- どのように画像からフラスタム型の3D点群を抽出し(lift)、フラスタムをego座標平面に展開(splat)、解釈可能なモーションプランニングとしてBEV平面上に軌跡を生成(shoot)するか解説する。
- 従来のモデルでは、ある画像ピクセルの特徴が物体の奥行きに関係なく全てのボクセルに均一に割り当てられてしまい、これが性能のボトルネックになっていた。本稿ではこれを解決している。
手法
問題設定
n枚の画像$\lbrace X_k \in \mathbb{R}^{3 \times H \times W} \rbrace_n$、extrinsic$E_k \in \mathbb{R}^{3\times4}$、intrinsic$I_k \in \mathbb{R}^{3\times3}$を入力とし、BEVフレーム$\mathbf{y} \in \mathbb{R}^{C \times X \times Y}$を出力する。
- extrinsic : ego座標系におけるカメラの位置と姿勢。平行移動$T_n = [X_0,Y_0,Z_0]_n^T$と回転$R_n \in \mathbb{R}^{3\times3}$を持つ。
- intrinsic : カメラ座標系→画像座標系に変換するための行列(本稿では逆の変換なので、逆行列を用いる)。
I_n =
\begin{bmatrix}
f_{x,n} & 0 & c_{x,n} \\
0 & f_{y,n}& c_{y,n} \\
0 & 0 & 1
\end{bmatrix}
𝑓_{𝑥,𝑛}, 𝑓_{𝑦,𝑛}\text{:カメラnの焦点距離}
𝑐_{𝑥,𝑛}, 𝑐_{𝑦,𝑛}\text{:カメラnの画像中心座標}
画像→3D空間への拡張
- 画像の各ピクセルに対して深度を回帰するのではなく、固定幅で設定した深度ビンの確率を予測する。
→深度ビンを固定することにより、各ピクセル/深度とBEV空間上のボクセルを一意にマップする事ができ、変換が容易になる。また、確率予測のため、深度予測の曖昧さを考慮することができる。 - ピクセル$p$に対し、コンテキストベクトル$\mathbf{c}$と深度ビンの確率分布$\alpha$を予測する。これにより、ピクセル$p$の深度$d$におけるコンテキストは以下のように表せる。
\mathbf{c}_d = \alpha_d \mathbf{c}
→ピクセルの深度がdである確率とピクセルの特徴cの積を取ることにより、深度dにおいて特徴が強く反映され、確率の低い深度では特徴が反映されない形になる。この処理で深度確率は特徴量に統合され、特徴$c_d$が深度確率とコンテキストを合わせ持つ特徴量となる。

BEV空間のボクセルへの統合
-
"lift"で得たフラスタム型の特徴量を、ego座標系のボクセルに変換する。このボクセルは二次元グリッド上の位置と、その位置における特徴量(Z軸方向)を有する。
→ピクセル$p$の深度$d$における特徴量$c_d$が、対応するボクセルの特徴量にマッピングされる。すべての深度が対応するボクセルにマッピングされるが、確率の低い深度は特徴が0になるため、ボクセルにも0が反映される。 -
複数の画像やピクセルが同じボクセルに対応している場合があるため、累積和を計算して統合する。
-
Z軸方向のスライスは、チャネルと連結させてCZとする。
→最終的にCZ,X,YのBEV空間が得られる。

経路生成
- BEV特徴量を用いてコストマップを学習し、テスト時にはコストが最小になる経路を出力する。
- 経路生成を、K個の経路テンプレート$\tau$から教師データに最も近い経路を選択する問題と定義する。
- 経路$\tau_i \in \tau$が正しい確率を、下記のような経路上のコストを合計する方法により定義し、正解ラベルを"教師データとのL2ノルムが最小の経路"とすることにより、誤差逆伝播を用いてコストマップを学習する事が出来る。
p(\tau_i \mid o) =
\frac{
\exp\!\left(
- \sum_{(x,y) \in \tau_i} c_o(x,y)
\right)
}{
\sum_{\tau \in T}
\exp\!\left(
- \sum_{(x,y) \in \tau} c_o(x,y)
\right)
}
→複雑だが、経路選択タスクを通じてコストマップが学習されるということ。コストマップから経路が選択されるので、誤差逆伝播によりコストマップのパラメータがチューニングされる。
- 経路テンプレートは、教師データにK-Means法を用いることで作成する。
実装、モデルアーキテクチャ
- モデルは二つのbackboneから構成され、一つは入力画像の深度確率と特徴量抽出、もう一つはBEV空間に投影した特徴量からのBEVセグメンテーション(Bounding Boxや車線の検出)の生成や経路生成に用いる。
- 一つ目のbackboneにはImagenetで事前学習したEfficientNet-B0を用いる。
- もう一方のbackboneには、ResNetのブロックを組み合わせて用いる。畳み込み層とbatchnorm、ReLUを通した後、ResNet-18の3レイヤーを通して解像度の異なる$x_1,x_2,x_3$を得る。$x_3$をUpsampleして$x_2$と結合した後、さらにresnetブロックを通してから出力するBEV画像の解像度に合わせてUpsampleする。
- ハイパーパラメータとしていくつかの解像度がある。入力画像の解像度H×W(128×352)、BEV空間の解像度X×Y(-50mから50mまで0.5mづつ刻む→200×200)、深度ビンの距離と刻み幅D(4mから45mまで1mづつ)。
Gitのサンプルコードから確認した詳細なアーキテクチャは下図の通り。これは別記事で解説したいと思います。

ソースコードの取得
https://github.com/nv-tlabs/lift-splat-shoot
実験結果
ベースラインとの比較
- nuScenesとLyft Level 5を用いて精度を検証する。
- オブジェクトのセグメンテーションタスクとマップ予測タスクを行う。
セグメンテーション:3D Bounding BoxをBEVに投影する。
マップ予測:nuScenesのマップ構造をego座標系に投影して用いる。 - どちらのタスクにおいても、ベースラインに対して高い性能を発揮している。

ロバスト性の検証
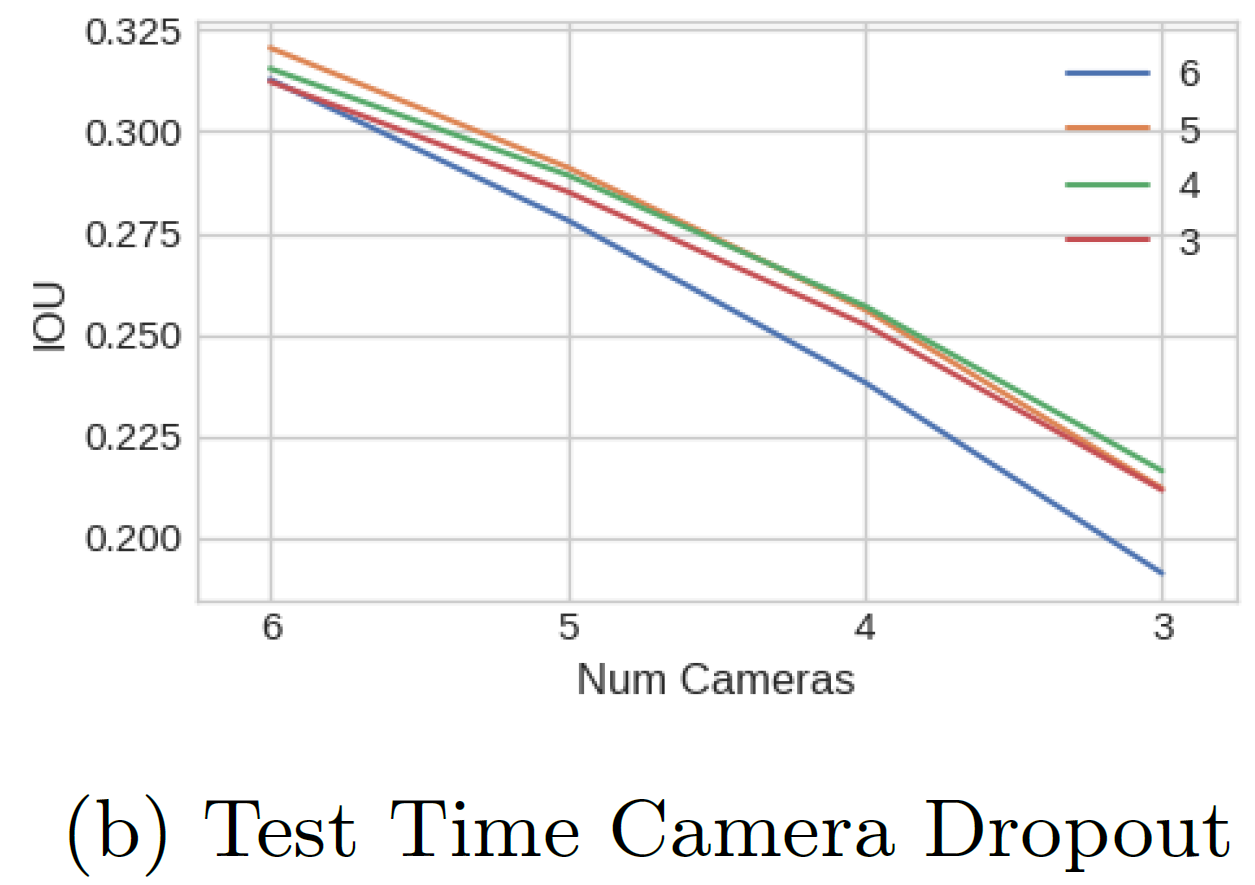
- カメラシステムでは、外部パラメータのズレや、カメラが故障するリスクがあるため、これらの現象に対するモデルのロバスト性を確認した。
- トレーニング中にカメラをドロップアウトさせることで、テスト時のドロップアウトに対する性能が向上することが分かった。6カメラ中1カメラを、すべてのフレームでランダムにドロップアウトする方法が最も精度が高かった。
→ドロップアウトにより、少し離れたカメラ間の関係性も学習するようになるためと考えられる。
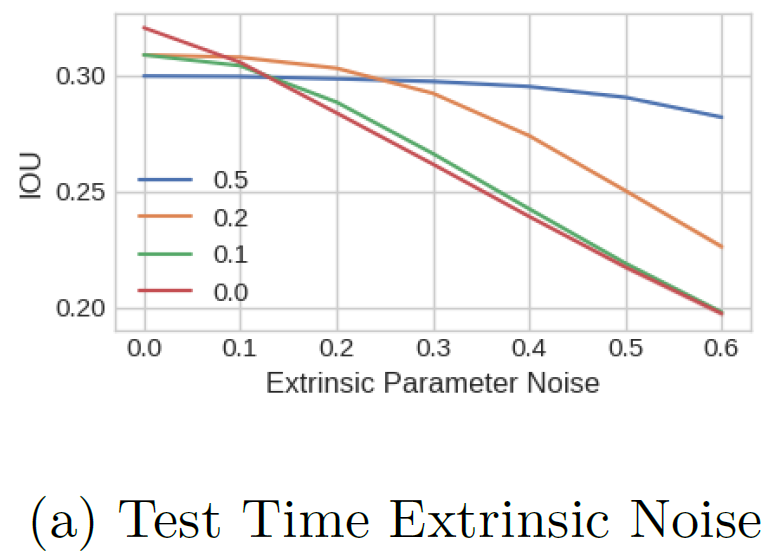
 - 外部パラメータのノイズに対しては、テスト時のノイズが小さいときはノイズなしで学習したモデルが精度が良いが、テスト時のノイズが大きいときはノイズありで学習したモデルの方が精度を維持できることが分かった。
- 外部パラメータのノイズに対しては、テスト時のノイズが小さいときはノイズなしで学習したモデルが精度が良いが、テスト時のノイズが大きいときはノイズありで学習したモデルの方が精度を維持できることが分かった。
汎化性能の検証
- テスト時に学習時よりもカメラ数を増やして検証したところ、再学習なしでも精度の向上が見られた。
→LSSでは共通のモデルで複数カメラの特徴量抽出と深度推定を行うため、intrinsicとextrinsicを変えるだけで、学習時に存在しなかったカメラに対しても予測を行うことができる。

- 学習時と異なるデータセットで検証(nuScenesで学習してLyft Levelで検証)した場合も、妥当な予測結果を得られることが分かった。ベースラインに対しても、汎化性能の向上が見られた。

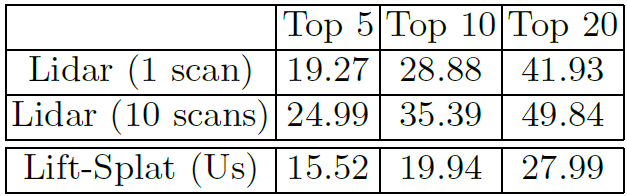
LIDARとの比較
-
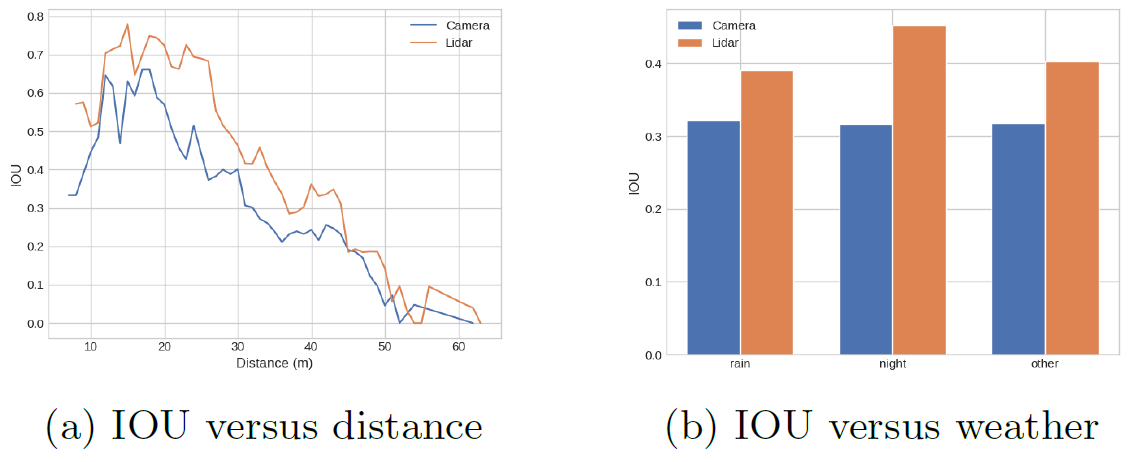
LIDARを用いたモデルであるPointPillarsと性能を比較した。LIDARモデルに比べて僅かに劣る結果となったが、走行可能領域に関しては近い精度を発揮している。
https://arxiv.org/abs/1812.05784 -
距離とシーンに対する性能評価を行った。予測通り、距離が遠くなるほど性能は劣化し、シーンは特に夜にLIDARとの性能差が顕著になった。
軌道生成
- 道路境界に沿って走る、横断歩道で停止する、前車がブレーキを踏んだら後ろで停まる等の望ましい挙動を示した。
- 1つの入力から、複数の軌道の可能性を予測することが分かった。
- モデルに速度情報を入力していないのに、シーンに応じて速度調節を行う(横断歩道付近は低速で走るなど)ことが分かった。
- Planningにおいても、LIDARに比べて性能が下がる結果となった。

結言
- 特定のカメラ構成に依存することなく、BEV表現を出力可能なアーキテクチャを示した。
- 多くのカメラベース手法に対して優位性を示した。
- カメラのキャリブレーションノイズに対してロバストなモデルを学習する方法を示した。
- このモデルを用いて、ENd to Endのモーションプランニングを行う方法を示した。
残課題
・LIDARを用いたモデルに匹敵する性能を出すには、複数時刻の画像を入力とする必要がある。
おわりに
本論文でやっていることは画像の深度確率を予測してBEV座標系に変換するだけなのですが、文字での説明が多く、画像の座標変換を扱ったことが無い筆者には少しイメージが難しい内容でした。同じ感想を持つ方も多いかと思うので、次の記事ではモデルの実装内容についてコードベースで解説したいと思っています。是非ご一読頂ければと思います!