代表値
・代表値とは、データの中心的傾向や標準を表す値のことを指します。
代表値には平均値・中央値・最頻値があります。順にその特徴について見ていきましょう。
① 平均値 (mean)
・データの合計をデータの数で割った値
・通常、標本平均を$\bar{x}$, 母集団平均を$\mu$で表す
\bar{x} = \frac{x_1 + x_2 + ・・・ + x_n}{n}
\bar{x} = \frac{1}{n}\sum_{i = 1}^{n}x_i
Pythonで実践してみましょう。
import seaborn as sns
import numpy as np
# データ準備
df = sns.load_dataset('tips')
df['tip_rate'] = df['tip'] / df['total_bill']
# 平均値を求める
np.mean(df['tip_rate'])
結果
0.16080258172250478
Seriesに対して、mean()メソッドを呼ぶ
df['tip_rate'].mean()
結果
0.16080258172250478
また性別ごとの平均値を確認したい場合はgroupbyを使う
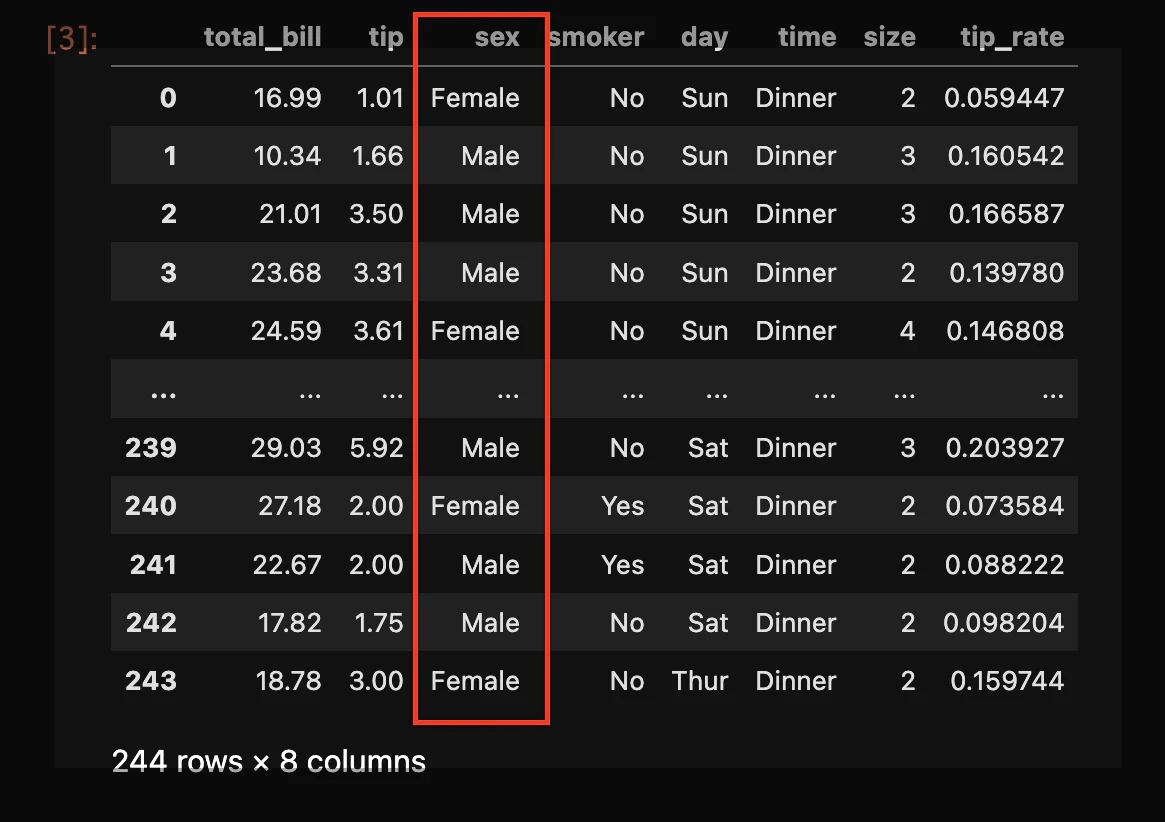
df.groupby('sex').mean()
結果
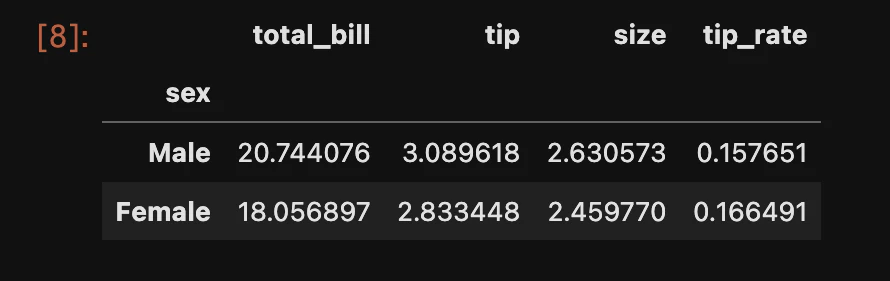
特定のカラムのみの計算でいい場合は下記のように記述する
# 特定のカラムのみ平均値を計算する
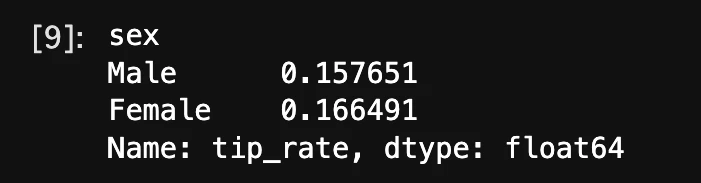
df.groupby('sex').mean()['tip_rate']
結果
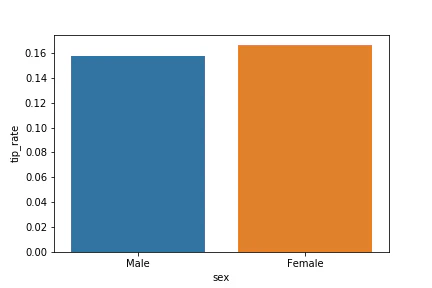
では、上記の平均値をグラフで表してみよう。
・sns.barplot(x=x軸, y=y軸, data=データ)
# 平均値を描画する
sns.barplot(x='sex', y='tip_rate', data=df)
# barplotはデフォルトで平均値が設定されている (estimator=<function mean)
# また、上記を実行すると、エラーバーが表示されるが、無くしたい場合は、ci=Noneを引数に渡せばよい
# ※コンフィデンスインターバル(Confidence Interval、CI)は、95%信頼区間を指す
結果
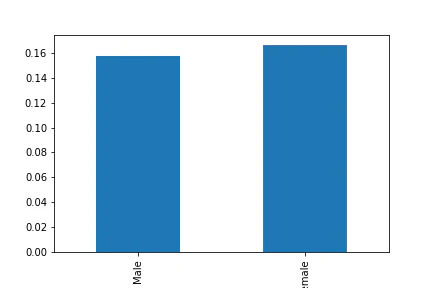
Seriesから平均値を描画する方法
df.groupby('sex').mean()['tip_rate'].plot(kind='bar')
結果
②中央値(median)
・中央値とは、データを大きい順に並べた際の真ん中の値で、真ん中の値がない場合は真ん中の二つの中間を取る。平均値より外れ値の影響を受けにくいが、計算に時間がかかることに注意する。
Pythonで実践してみましょう。
np.median(df['tip_rate'])
結果
0.15476977125802577
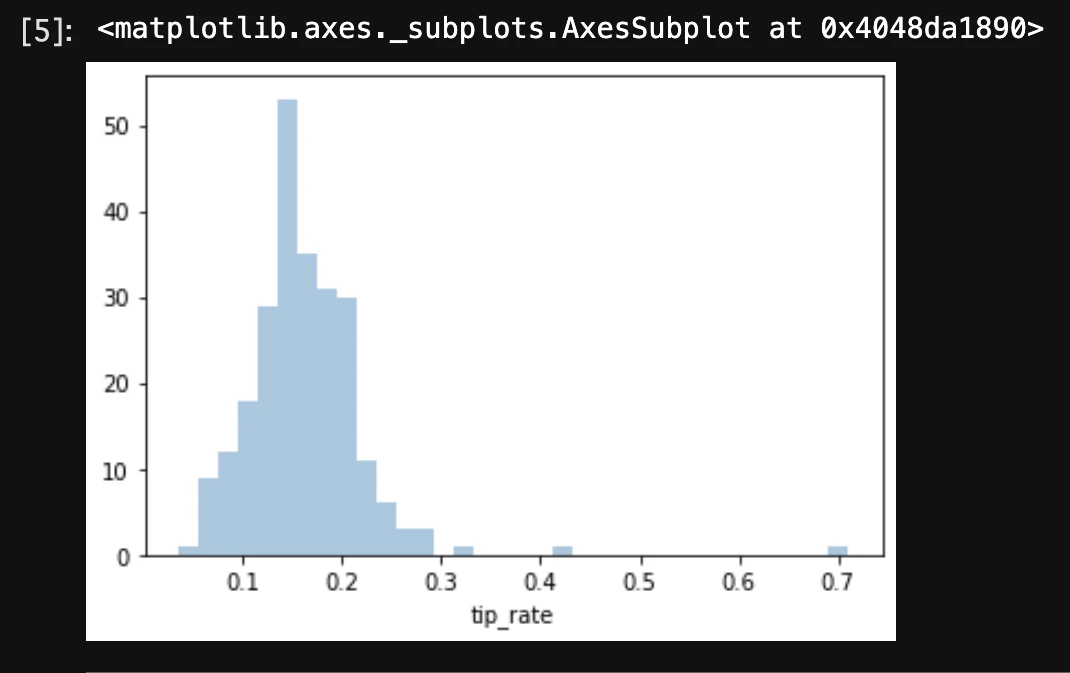
では、上記の中央値をグラフで表してみよう。
・sns.distplot(データカラム, kde=False)
sns.distplot(df['tip_rate'], kde=False)
結果
Seriesに対して、median()メソッドを呼ぶ
・df['column'].median()
df['tip_rate'].median()
結果
0.15476977125802577
df.groupby('sex').median()
結果
| total_bill | tip | size | tip_rate | |
|---|---|---|---|---|
| sex | ||||
| Male | 18.35 | 3.00 | 2 | 0.153492 |
| Female | 16.40 | 2.75 | 2 | 0.155581 |
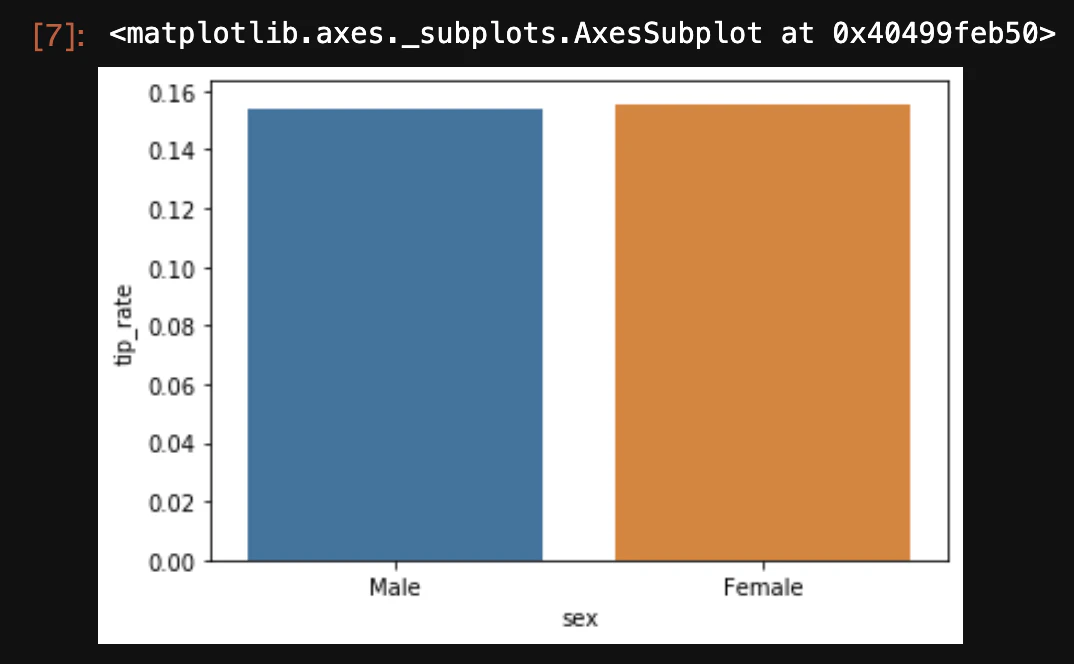
barplotで描画する場合、estimatorに中央値を指定する。
sns.barplot(x='sex', y='tip_rate', data=df, estimator=np.median, ci=None)
結果
③最頻値(mode)
・最頻値とは、データの中で最も多く観測される値(最も頻繁)
極端に特定の値に集中している場合は、最頻値を代表値として扱い、分布の山をモーダル(modal)と呼ぶ。
Pythonで実践してみましょう。
・stats.mode()
最頻値とカウントを返す
mode, count = stats.mode([1, 2, 2, 2, 3, 4])
Seriesに対して、mode()メソッドを呼ぶ
・df['column'].mode()
最頻値をseriesで返す
df['size'].mode()
散布度
・散布度とはデータの散らばり具合を表す指標である。
・平均値や中央値のような代表値だけではどういったデータなのかを説明するのには不十分であり、散布度といった平均値の周りでデータがどれだけ散らばっているかという指標が重要になってくる。
・散布度には、範囲・四分位数・平均偏差・分散・標準偏差があります。
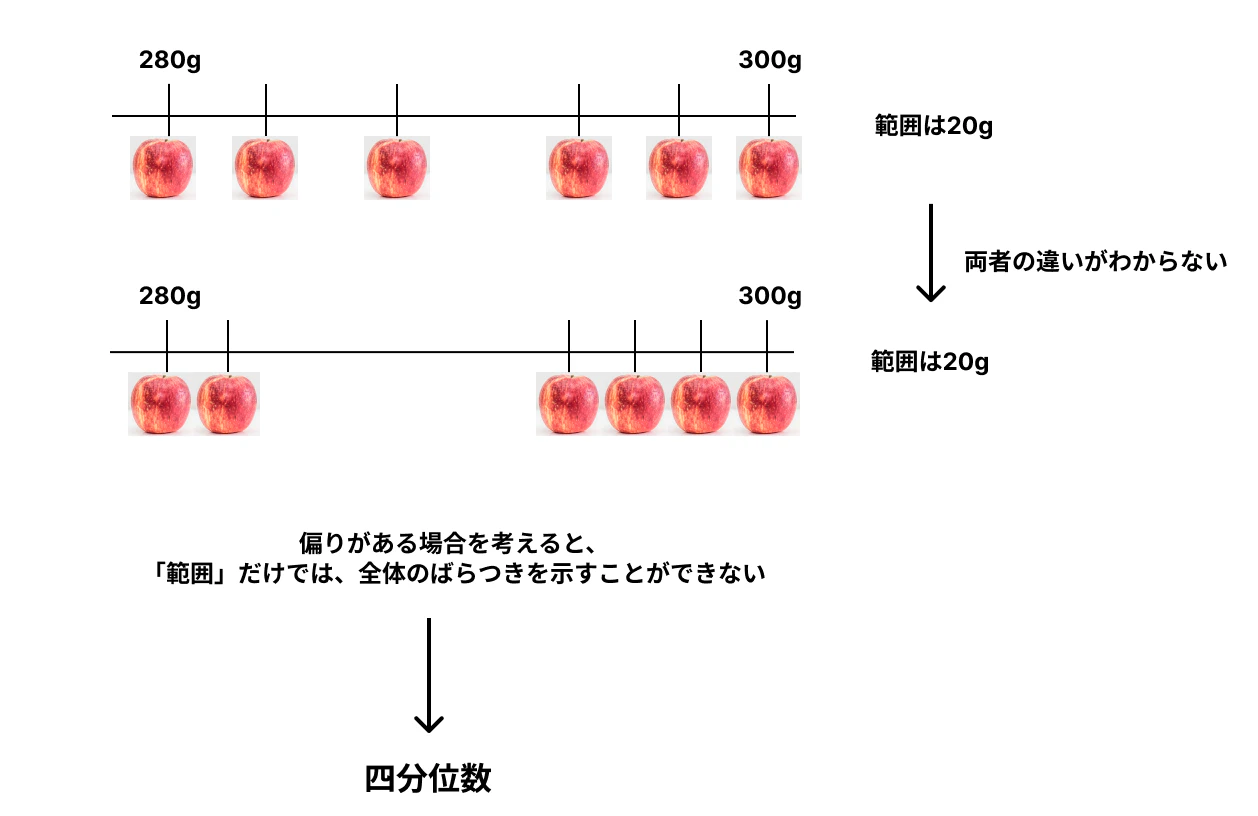
①範囲(range)
・最大値−最小値
「範囲」だけでは全体のばらつきを示すには不十分
Pythonで実践してみましょう。
最小値を求める
・np.min()
・df['column'].min()
・df.groupby('column').min()
np.min(df['tip'])
最大値を求める
・np.max()
・df['column'].max()
・df.groupby('column').max()
np.max(df['tip'])
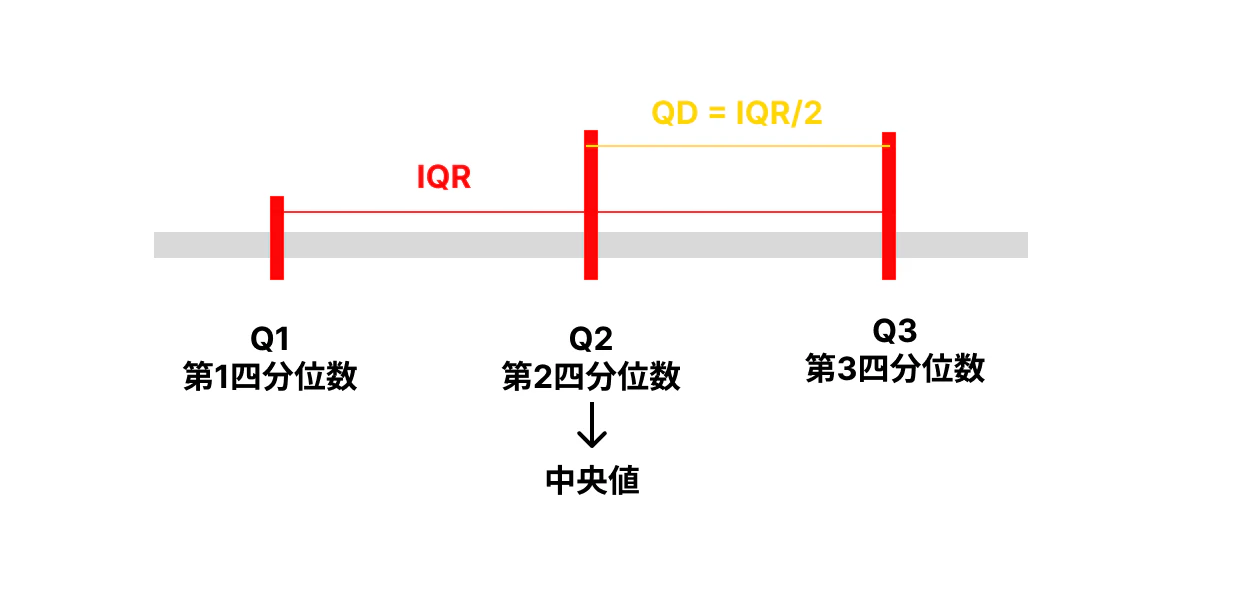
②四分位数(quartile)
データを並べて四分割したときの25%, 50%, 75%の値
全体のばらつきを示すにはまだ不十分
Q_3 - Q_1 : 四分位範囲(IQR:Interquartile\:range)
\frac{Q_3 - Q_1}{2} : 四分位偏差(QD:quartile\:deviation)
Pythonで実践してみましょう。
四分位数を求める
・np.quantile(data, [0.25, 0.5, 0.75])
・df['column'].quantile([0.25, 0.5, 0.75])
np.quantile(df['tip_rate'], [0.25, 0.5, 0.75])
df['tip_rate'].quantile([0.25, 0.5, 0.75])
四分位範囲(IQR)を求める
・stats.iqr()
stats.iqr(df['tip_rate'])
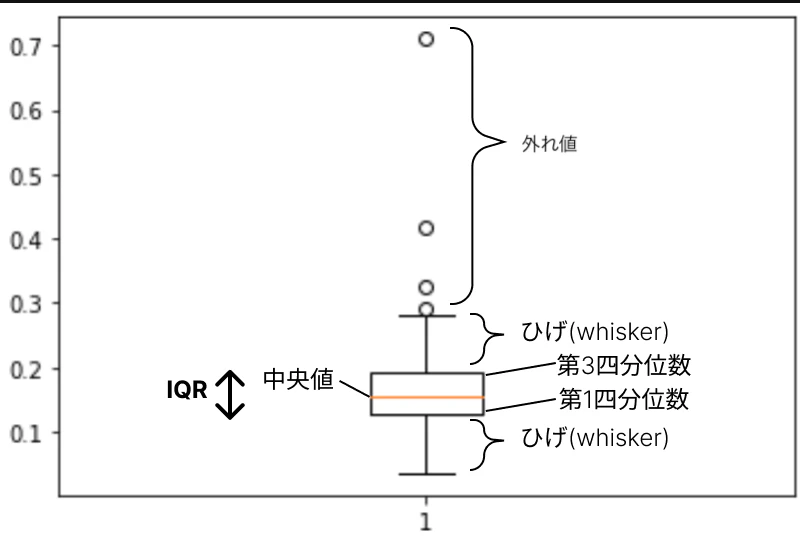
四分位数を使ったグラフである箱ひげ図(box plot)を描画してみましょう
import matplotlib.pyplot as plt
%matplotlib inline
plt.boxplot(df['tip_rate'])
plt.show()
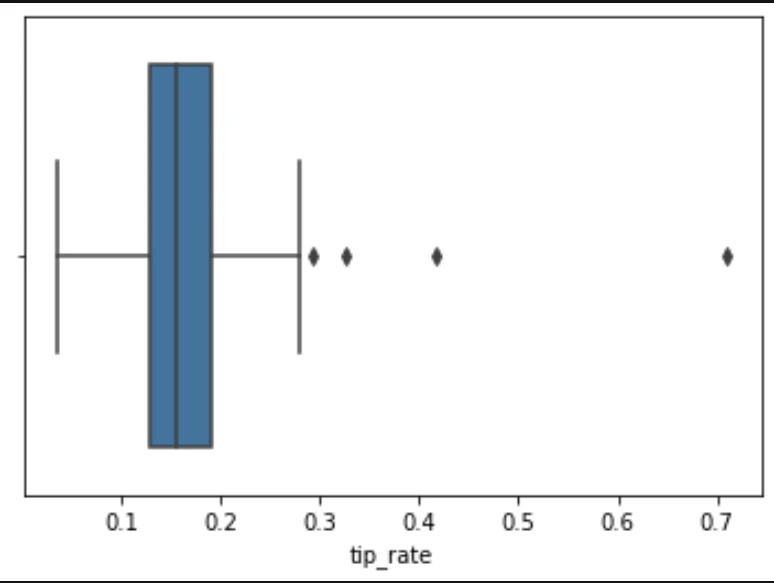
seabornを使った箱ひげ図
sns.boxplot(df['tip_rate'])
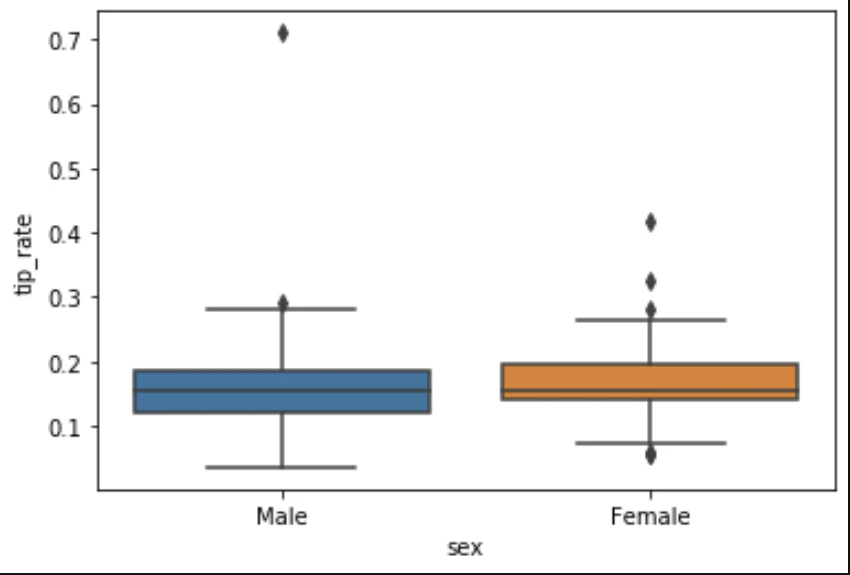
性別ごとに箱ひげ図を並べることも可能
sns.boxplot(x='sex', y='tip_rate', data=df)
③平均偏差(MD:mean deviation)
平均からの偏差や絶対値の平均
全てのデータを使うので、範囲や四分位数より散布度としては適している
MD = \frac{1}{n}(|x_1 - \bar{x}| + |x_2 - \bar{x}|+ ・・・ + |x_n - \bar{x}| = \frac{1}{n}\sum_{i = 1}^{n}|x_i - \bar{x}|
しかし、絶対値の中身がマイナスの場合、マイナスを掛けてプラスにしなければいけないため、絶対値が扱いにくい
→だからと言って、単純に絶対値を外すと、平均値からの偏差の和はゼロになってしまうため、絶対値は外せない。
→絶対値は扱いにくいため、二乗しようと考えたのが、次に説明する分散です。
④分散(variance)
・平均からの偏差の2乗の平均
・通常標本nの分散は$s^2$, 母集団の分散は$\sigma^2$で表す
・nではなくn-1で割る不偏分散もよく使われる
s^2 = \frac{1}{n}((x_1 - \bar{x})^2 + (x_2 - \bar{x})^2+ ・・・ +(x_n - \bar{x})^2) = \frac{1}{n}\sum_{i = 1}^{n}(x_i - \bar{x})^2
しかし、2乗したことで新たな問題があります。それは、尺度がずれてしまうことです。
尺度がずれるということは、統計的な意味での尺度の変化を指します。
その単位は元のデータの単位の2乗です。つまり、もともとのデータが異なる尺度を持っている場合、分散もその尺度の2乗になります。そのため、2乗した後に平方根をとることで尺度を戻そうと考えたのが、次の標準偏差です。
⑤標準偏差(standard deviation)
・平均からの偏差の2乗の平均の平方根(分散の平方根)
・通常標本の標準偏差は$s$, 母集団の標準偏差は$\sigma$で表す
s = \sqrt{\frac{1}{n}\sum_{i=1}^{n}(x_i - \bar{x})^2}
Pythonで実践してみましょう。
分散を求める
・np.var()
np.var(df['tip'])
標準偏差を求める
・np.std()
np.std(df['tip'])
分散や標準偏差がわかると、データの散らばりがわかります。そして、平均$\pm$標準偏差にどれくらいデータが入っているかを考えることができます。
| $\bar{x}\pm s$ | 約$\frac{2}{3}$ |
|---|---|
| $\bar{x}\pm 2s$ | 約95% |
| $\bar{x}\pm 3s$ | 約99%〜100% |