はじめに
本記事は、trocco® Advent Calendar 2023 シリーズ2の16日目の記事になります。
本記事では、trocco®のデータマート定義(DWH内のデータを加工してDHW内に新たなテーブルを作成する機能)で利用するSQLについて、私がおすすめする初心者からの学習法を取り上げます。ユーザーの方はもちろん、これからSQLを学んでいきたい方に参考にしていただけると嬉しいです。
なお、データエンジニアリングの全体像を取り上げた前の記事
はかなり骨太な記事になっていますが、SQLについては定評のある書籍等も多くありますので、それらの紹介をベースにしつつ、初心者が抑えておくとよいTipsをBigQueryを例に取り上げています。
こんな方におすすめ
- trocco®のデータマート定義をより使っていきたいが、SQLを書く自信がない
- これまではExcelやBIでデータを取り扱っていたが、よりデータを活用していくにあたってSQLをしっかり身に着けたい
- データサイエンス100本ノックをBigQueryで実施したい
SQLとは何か
SQLとは、Structured Query Languageの略で、データベースにデータを問合せするための言語です。従来からのRDBで利用されているのはもちろん、DWHであるBigQueryやRedshift、Snowflakeでもそのデータ操作の基礎となっており、移り変わりの早いプログラミング言語と異なり長い間安定的に利用され続けている言語です。
処理を決められた関数で定義するExcelや、GUIベースでデータ加工のできるツールと比べるとハードルが高く感じるかもしれませんが、プログラミング言語を習得することと比べれば分析用途のSQLの習得はそれほど難しくはありません。
それは、下記の2点が理由になります。
- そもそもデータベースの処理に特化した言語であるため、プログラミング言語と比較するとできること(=学ばないといけないこと)の幅が著しく狭い
- 例えば、SQLでは基本的にループ処理ができない
- データベースの管理のためではテーブルの作成/変更やデータの変更/追加/削除やテーブルの関係の定義、パフォーマンスの最適化などやることの幅が広いが、分析のために限定すると基本はデータを抽出することができればよいので、上記に加えてできないといけないことの幅が狭い
- まずは抽出のための方法に慣れてくると、その他の処理も感覚が掴めてきます
特に、BI経験者であればその裏側で行われていることはSQLの処理になるので、GUI上での処理を言語として記載するとこういう形なのかというのが理解しやすいです。私はTableau使いだったので、JOINやUNION、LOD表現という処理の結果が、SQLではどう表現されるのかと考えると非常にスムーズに学習が進みました。
(確かJTUGのイベントで、パフォーマンスの計測を利用すると裏側で投げられているSQLクエリが確認できるという事例があったように思いますが、それがいつのものだったか思い出せず・・・)
SQLの学び方
私がおすすめするSQLの学び方は、まずSQLの位置づけをざっくり理解したあとに、SQLの用途や処理の内容を概念的に理解し、ハンズオンで手を動かしながら身に着け、実務で活用してみるという流れになります。
その際、疑問点を聞くことのできる有識者が周囲にいると、学習にあたり大きな助けになるでしょう。仮にいなくともLLMに聞いてみれば割と筋の良い返答は返ってくるでしょうから、とても便利な社会になったものです。
SQLの位置づけをざっくり理解する
この目的で利用できるコンテンツとしては、Snowflakeのユーザー会であるSnowVillageが公開しているYouTube動画がよくまとまっています。
ちなみに、同じくDWHとデータモデルの解説動画も内容が良く整理されており、おすすめです。
これらの動画は私が学習を始めた際にはまだ公開されておらず、私個人としては『[入門]はじめてのデータベース』から学習を始めました。この書籍はデータベースについて基礎から分かりやすく解説しており、全体像をおさえるのに非常におすすめです。初めて読んだ時点で全てを理解する必要はなく、なんとなくこういうものがあるのかと思っていれば、学習を進めていくうちに徐々に理解が深まってくるでしょう。
SQLの用途や処理の内容を概念的に把握する
この目的では、何より『10年戦えるデータ分析入門:SQLを武器にデータ活用時代を生き抜く』が定評があり、実際に優れた本だと思います。これは分析者のためのSQLの入門本になっています。ほぼ10年前に出版されたのですが、タイトルの通り実際10年戦えてきましたし、著者自身が最近の講演のなかで「SQLは不滅」とまでも言っています。まだまだこれから10年も余裕で戦えていきそうです。
※初心者には内容が難しいのでいいですが、ある程度学習が進んできたらData Engineering Studyでの著者の講演は大変勉強になります。
なお、残念ながら絶版本であり入手が難しいのがネックで、私も中古で定価より高く購入しました・・・。
ハンズオンで手を動かしながら身に着ける
ある程度概念的にその機能を理解したあとは、とにかく手を動かして、操作を結果を見ながら学んでいくのみです。この目的では素材は色々ありますが、データサイエンス協会が公開しているデータサイエンス100本ノックがおすすめです。
これはデータの基礎的な前処理についてSQL/Python/Rでの処理方法を学習できる教材であり、環境やデータがGitHubに公開されているほか、解説も含めたものでは『データサイエンス100本ノック:構造化データ加工編ガイドブック』という書籍が出版されています。具体的な取り組み方法については後述します。
自身の業務で活用してみる
基礎的なクエリの書き方をハンズオンで身に着けたあとは、自身の業務や実験で利用してみるのが何よりの学習になります。私の場合、trocco®でデータの抽出は簡単にできるので、加工して可視化してみるのが初めての利用でした。
具体的には過去の記事(「初投稿のPVが爆増したのがtrocco®とQiita APIでよくわかった話」)で取り上げた、QiitaでのPVなどを加工してLooker Studioでダッシュボードにするのが初めての利用でした。
BigQueryでデータサイエンス100本ノックをしてみる
ある程度概要を把握したあとのハンズオンとして、前述したようにデータサイエンス100本ノックがあります。公式で公開しているものでは、そのハンズオン環境としてDockerコンテナ(PC内に操作用の仮想環境を整備するためのもの)をベースにしたPostgreSQL(RDBの一種)でのハンズオンが可能です。
とはいえ、実務で利用する環境としてはBigQueryのようなDWHが多いでしょうから、その環境で慣れておく方が望ましくあります。
この背景として、SQLに方言があるという事実があります。SQLには標準SQLというISOの規格があるものの、データベース/データウェアハウスサービスによって独自の規則(方言とも呼ばれる)があり、サービスに合わせたクエリの書き方を学ぶ必要があるのです。
BigQueryの基礎知識
BigQueryとは、Googleが提供している分析用データウェアハウスサービスで、大規模データの高速な分析が特色になっています。
BigQueryの料金モデル
小さく試すにはトライアルのサンドボックス環境というものがあり、1か月あたり10GBのアクティブストレージと1TBのクエリデータ処理を利用できます。60日後に自動的にテーブルが削除されるという制約がありますが、テストで利用してみるにはこの機能で課金されることなく利用可能です。(参考:公式ドキュメント)
有料で利用する際には、料金モデルとしてオンデマンド料金と定額料金がありますが、オンデマンド料金では上記と同じ無料枠が存在します。(参考:公式ドキュメント)
オンデマンド料金をベースにすると、BigQueryを利用するには、ストレージ料金とクエリ料金があります。費用を考える上では、ストレージ料金 << クエリ料金となることが多く、クエリ料金のみを考慮すればよいですが、簡単に内容を整理しておきます。
ストレージ料金
東京(asia-northeast1)リージョンで無料枠を超えてから課金されるものとしては、下記2つがあります(2023/12/16現在)。
- アクティブストレージ(過去 90 日間で変更あり):$0.023 per GB
- 長期保存(過去 90 日間で変更なし):$0.016 per GB
つまり、1TB利用したとしても、$0.023 × ¥142/$ = ¥3.266であり、1TBのデータは小規模環境ではそうそうないので、実務利用する上でのコストはクエリ料金と比べてそれほど重要ではありません。
なお、リージョンによって料金が変わるため、東京リージョンの場合を記載しています。
クエリ料金
東京(asia-northeast1)リージョンで無料枠を超えてから課金されるものとしては、下記のものがあります(2023/12/16現在)。
- クエリ(オンデマンド):$6.00 per TB
これでは、1TB利用したとすると、$6.00 × ¥142/$ = ¥852とこちらも大したコストではありません。
BigQueryのクエリ料金はスキャンされたデータに対して料金が発生する仕組みであるため、コンソール(操作画面)でクエリを書いた際に表示される右上のスキャン量を必ずチェックし、*(カラムの全選択)は利用しないのが望ましいというのが基本になります。
ところが、今回のデータサイエンス100本ノックに限って言えば、一番スキャン量の大きいgeocodeのフルスキャンで12.17MBであり、上記の計算式に則ると、12.17MB / 1024×1024MB × $6.00 × ¥142/$ = ¥0.0099なので、クエリ結果を確認しながら学習をスムーズに進めるためにも、*も使いつつクエリを叩いてしまって問題ないでしょう。
実務での利用に関しても、
- 1MB:
1MB / 1024×1024MB × $6.00 × ¥142/$ = ¥0.00081 - 1GB:
1GB / 1024GB × $6.00 × ¥142/$ = ¥0.832 - 100GB:
100GB / 1024GB × $6.00 × ¥142/$ = ¥83.2
となり、数十~数百㎇オーダーまではコストを考えている人件費の方が遥かに高いので、躊躇せずにクエリを叩くべしということで良いでしょう。(もちろん*を使わない習慣は、いざというときに大切ではあります。)
また、スキャン量課金である以上、LIMIT句をつけて表示件数を減らしても料金は変わらないので、結果のデータが見やすいようLIMIT句をつけずとも問題ありません。
環境の準備
実際のハンズオンを進めていく前に、まずはデータを準備する必要があります。GitHubからCSVファイルをダウンロードし、BigQueryで実施用のデータセットを作成したあとに、そのデータセットでテーブルを作成からCSVをアップロードしてテーブルを作成してください。
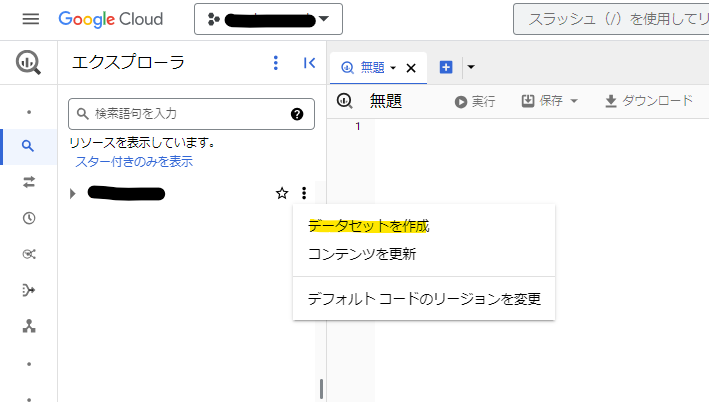
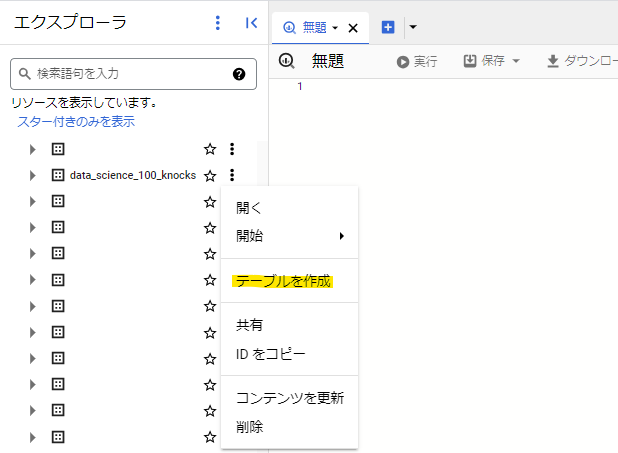
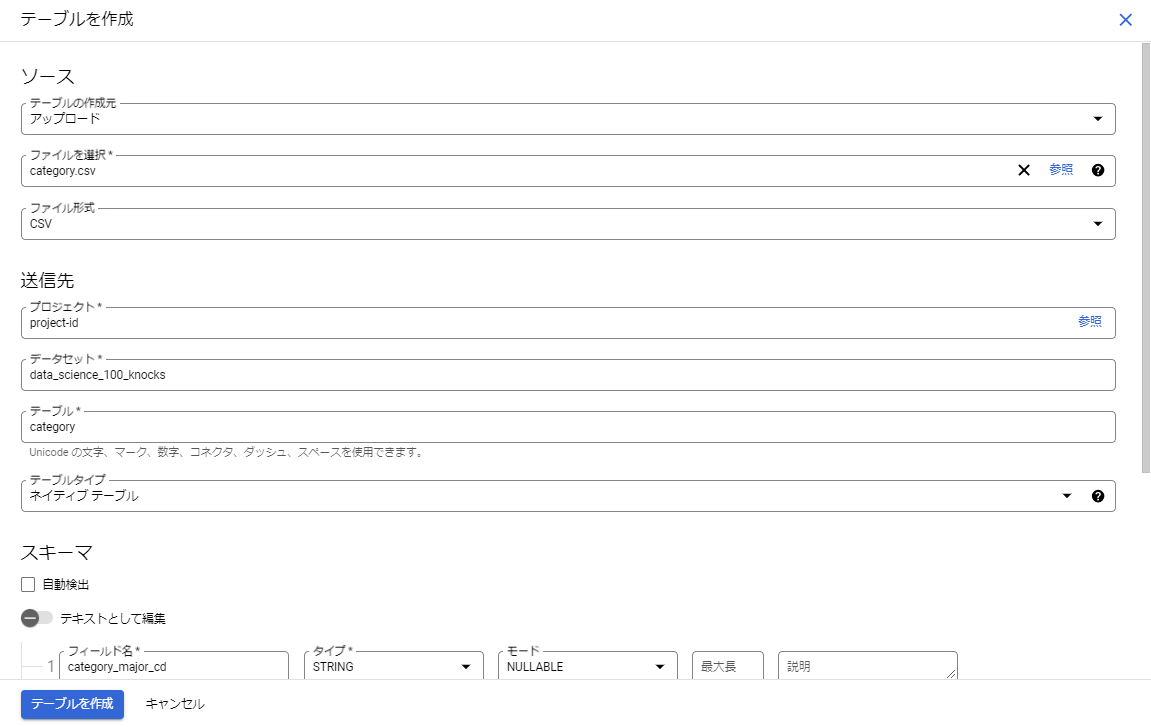
その際、GitHubにあるER図(テーブル間の関係性を示したもの)とデータ型を合わせるように注意してください。
下記のようなクエリでデータが抽出できれば準備は完了です。
select
*
from
`project-id.data_science_100_knocks.category`
※なお、この方法でテーブルを作成するとデータ行の順番が変わるというのがあり、結果として書籍にある回答とクエリ結果が一致しないことがありますのでご注意ください。私はこれを合わせようとして、一度Spreadsheetでデータを表示して、そこで行番号を付与して、その順番で並べるようにするという面倒なことをしました・・・。
BigQueryの利用上のTips
データサイエンス100本ノックを進めるときのTipsとして、下記のようなものがあります。
- コメントアウト
- ハイフン2つをつけると、その行のそれ以降がコメントとして扱われる
- /* */で囲まれた部分が行を超えてコメントとして扱われる
- インデント
- 範囲選択をして
Ctlt + ]で下がる - 範囲選択をして
Ctlt + [で上がる
- 範囲選択をして
- 部分実行
- 範囲選択をして
Ctrl + Enter(または実行ボタン)で部分的な実行が行える - ;で区切られた複数のクエリがある状態で範囲選択をしないと、複数あるクエリが上から順番に実行される(;がないとクエリエラーになる)
- 範囲選択をして
- コードの整形
-
Ctrl + Shift + Fでコードが整形される - 予約語(特別な意味を持つ語)を大文字で書くなどのコーディングスタイルはあるが、後で考えればいいので練習のうちは全て小文字で書いても問題ない
-
- クオートの取扱い
- 参照するテーブルを指定する際には、シングルクオート(')ではなくバッククオート(`)を利用する
- 文字列を記載する際にはシングルクオート(')またはダブルクオート(")を利用する
- テーブル名は基本的にサジェストが出るので、それに乗っかればよい
- project_idを省略してdataset_id.table_idの形式にもできるが、あまり省略はしない方がよい
- 参照するテーブルを指定する際には、シングルクオート(')ではなくバッククオート(`)を利用する
- クエリの保存
- 上部の保存>(名前を付けて)クエリを保存で保存ができる
- クエリ結果の保存
- 何もしなくても、ジョブ情報>宛先テーブルで24時間の間は一時テーブルが保存されている
- 永続テーブル化したい場合は、下記のクエリを実行する
create or replace table `project_id.dataset_id.table_id` as
select
hogehoge
from
`project_id.dataset_id.table_id`
さあ開始!の前に・・・
ではハンズオン!と思うところですが、データ分析は生データを理解することが出発点になります。そこで、クエリを叩く前に以下のようなことをしておくのが望ましいです。
- テーブルをダブルクリックしてスキーマ/プレビューを確認する
- スキーマ:特にカラム名(どんな項目があるか)、データ型を確かめる
- プレビュー:ざっとどんなデータが入っているかを眺める
- 左下で表示件数を200に変更するとよい
- テーブル間のリレーション(関係性)も重要なため、ER図を眺めておく
今度こそ、さあ開始!
問題一覧はGitHubのリンクのPDFの15-21ページに記載されています。
また、100本ノックを実施するにあたっていちいち問題を見るのも面倒なので、問題のみ一覧にしたクエリを公開しています。良ければ活用してみてください。なお、このなかで【※】がついているものは、個人的に初心者ではやらなくてもよいのではと思うものになります。
ハンズオンを終えたあとのおすすめ本
参考までに、簡単なSQLを書けるようになったあとに、続けて学習するのにおすすめの本をいくつか取り上げておきます。
- 初級者では出てこないSQLのコツをつかむ
- リレーショナルモデルをベースにSQLを深く理解する
- アプリケーションにおけるSQLのポイントを理解する
- 分析目的のSQLのバリエーションを学ぶ
さいごに
私自身は大体この流れで学んできましたが、PostgreSQLで100本ノックをやったのでBigQueryを使い始めたときに記法全然違うじゃん!となったり、当時このTipsを知っていたら便利だったな~と思ったりするものがあり、その内容をまとめてみました。
当初は私もSQLは難しいと思っていたものの、やってみたらPythonと比べて圧倒的に簡単であり、最近では機械学習も含め利用できる幅が広がっきているのもあって、非常に面白く思いながらクエリを書き続けています。
当分データエンジニアリングの基礎にSQLがあるのは変わらないとも思えるので、このスキルを身に着けてみると、データスキルの幅が広がって良さそうです。