はじめに
AWS Glue は、データレイクとデータパイプラインの作成、管理、実行を支援するフルマネージドサービスです。2023年11月に、AWS Glue にインタラクティブなデータプレビュー機能が追加されました。この機能により、ジョブを保存・実行せずにノードごとにデータパイプラインのデータを簡単にプレビューして、データの品質や整合性を検証できるようになります。
(参考:https://aws.amazon.com/jp/about-aws/whats-new/2023/11/aws-glue-studio-visual-interactive-data-previews/)
メリット
データプレビュー機能を使用すると、以下のメリットがあります。
-
データの品質や整合性を検証しやすくなる
データプレビュー機能を使用すると、データレイクやデータパイプラインのデータを目視で確認できるので、データの品質や整合性を簡単に検証できます。
- データの欠損
- データの重複
- データの不正確さ
- データの整合性
-
ジョブの作成やデバッグが容易になる
データプレビュー機能を使用すると、ジョブ作成・編集時にデータプレビューを表示できるため、ジョブの作成やデバッグが容易になります。具体的には、以下の点を確認できます。- ジョブの処理結果が想定通りであるか
- ジョブの処理に必要なデータがすべて含まれているか
- ジョブの処理に不具合が発生していないか
デメリット
-
料金
- ジョブ作成時のノード追加などによる操作によってリクエストが発生し、想定外の費用の増加につながる場合があります。例:API実行回数の増加、データソースからのデータ取得料の増加など
使用方法
データプレビュー機能を使用するにあたって事前に設定は不要です。
AWS Glue Studio のビジュアルエディター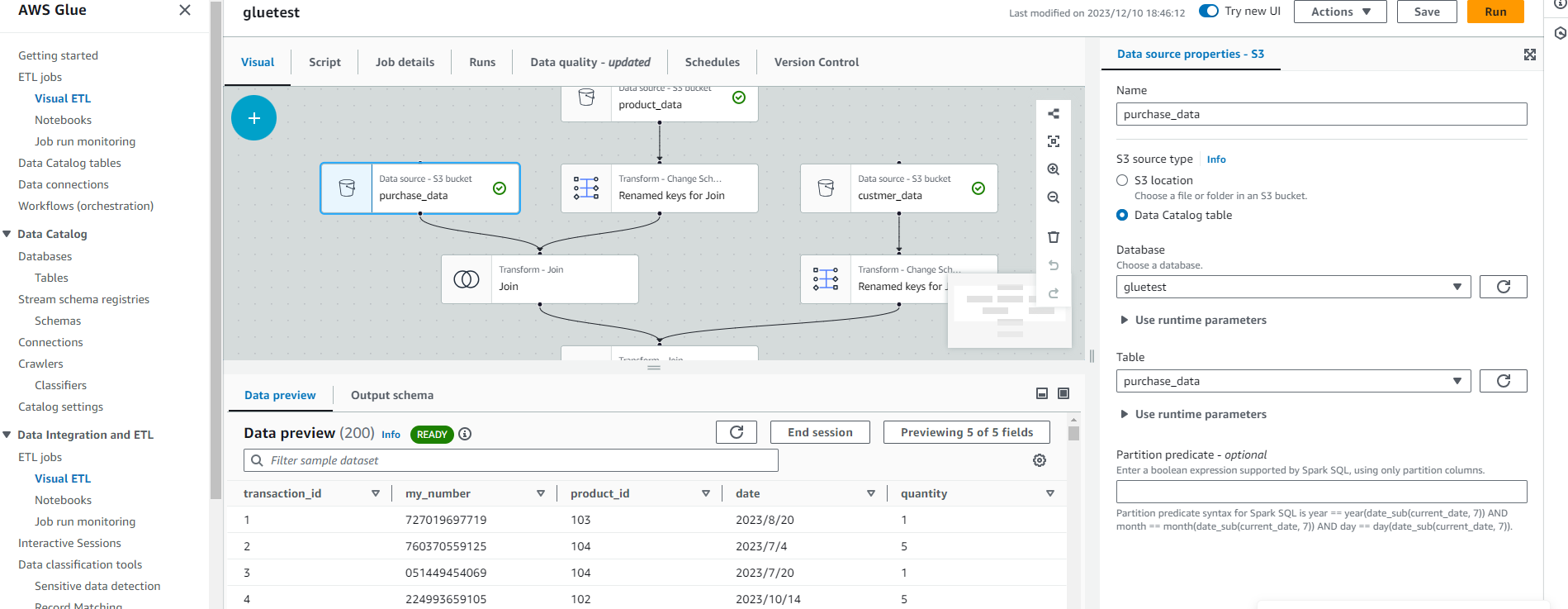
- AWS Glue Studio で、ジョブを作成します。
- ジョブのソース、ターゲット、変換ノードの各ノードに、データプレビューを表示したいデータを選択します。
- ビジュアルエディター上でいずれかのノードを選択することで画面下部にデータプレビュー画面が表示されます。
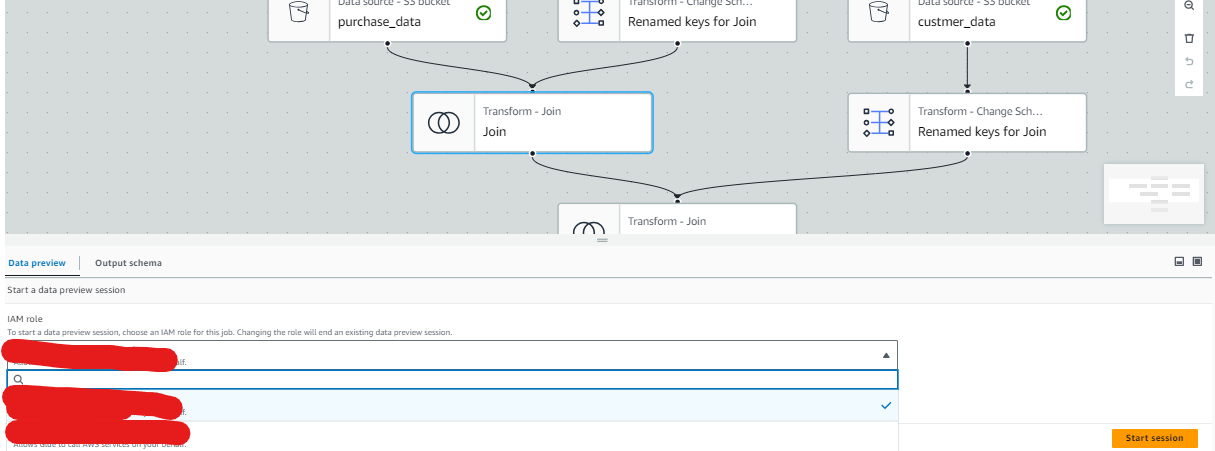
- 必要な権限が付与されたIAMロールを選択します。その後、「Start session」を押下することでセッションを開始できます。一つのセッションで他のノードにおいてもデータプレビューができます。
参考:https://docs.aws.amazon.com/ja_jp/glue/latest/dg/set-up-iam.html
使ってみた
1.サンプルデータの準備
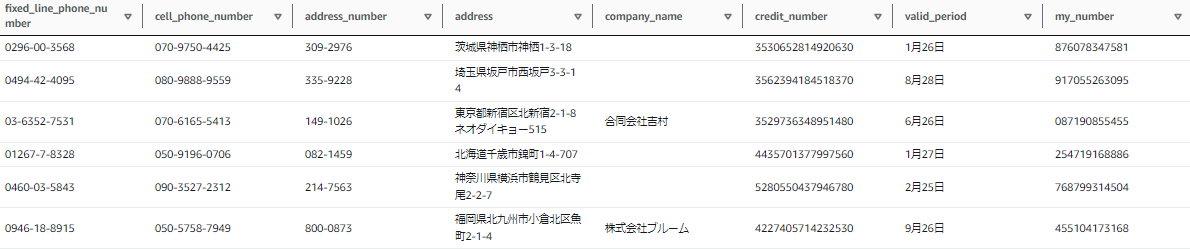
今回はサンプルデータ(csv)をS3に格納し、Glue Data Catalog にテーブルとしてインポート、こちらを入力データとしてジョブを作成しました。サンプルの製品、顧客、販売データ用意し、使用していますので登場する個人情報はすべてダミーです。顧客データは「個人情報テストデータジェネレーター」様から取得、製品・顧客データはChatに丸投げして出てきたpythonコードをColabで実行して作成しました。ちょっとしたことやらせるのにはほんと便利ですね。
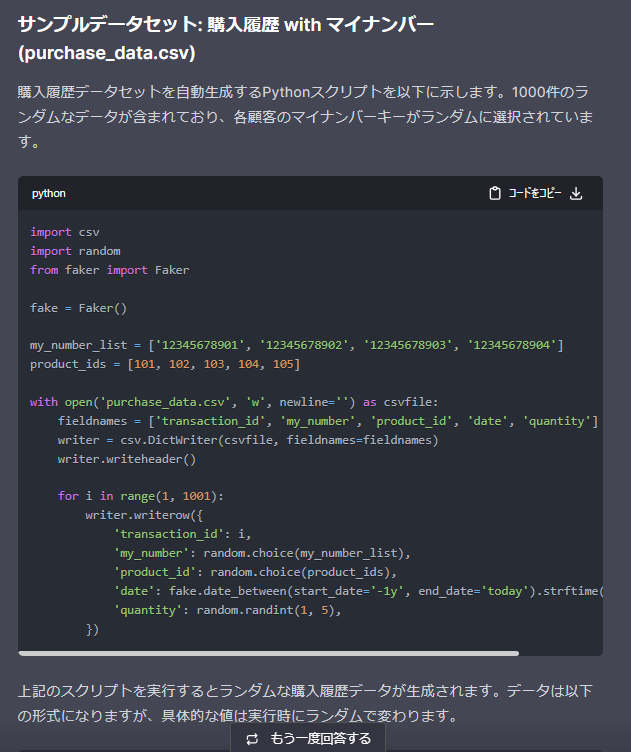
販売データ:purchase_data(1000件中6件のみ表示)
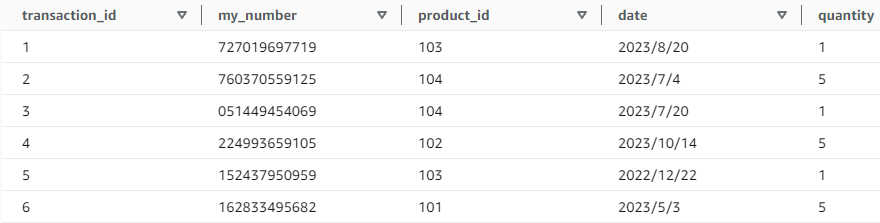
製品データ:product_data
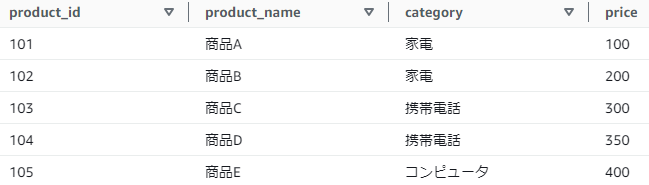
顧客データ:customer_data(ダミーデータにしてはリアル..)

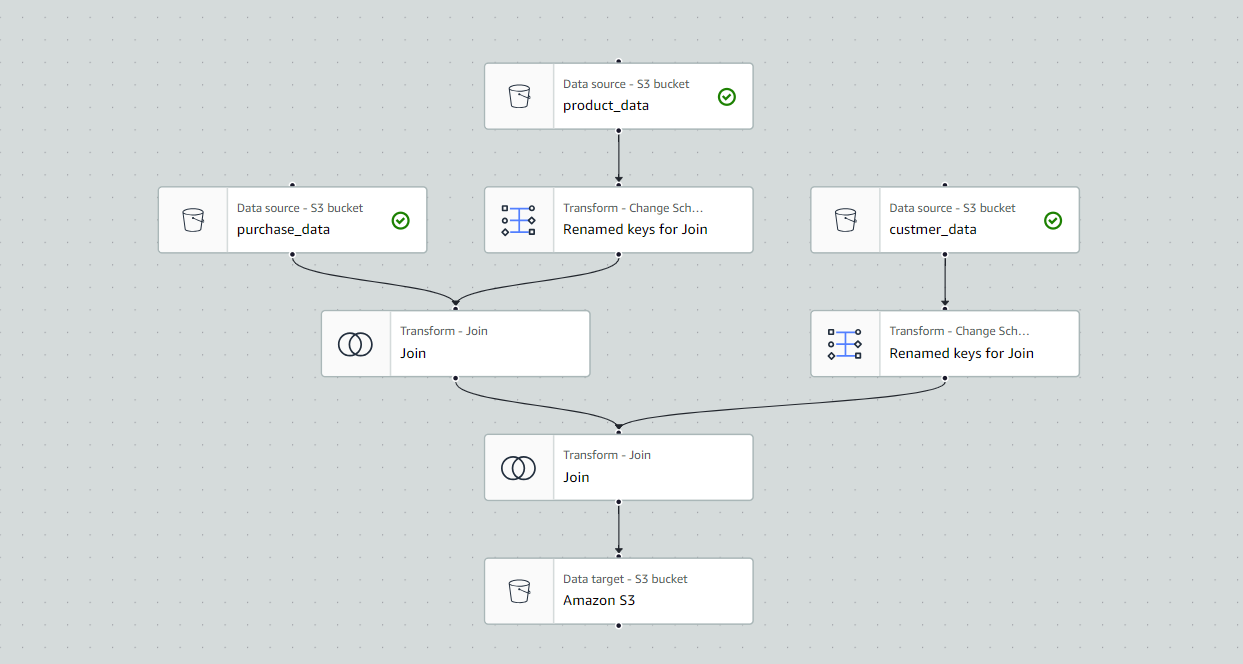
2.ジョブ作成
とりあえず、結合してみました。キーはそれぞれproduct_idとmy_numberです。マイナンバーを販売データ管理のキーにしてるなんてことは現実味ないですが、テストなので良しとします。。
3.データプレビュー開始
先述した手順に従ってセッション開始します。
セッション開始には1~2分程かかります。エディターを閉じると再度セッション開始する必要があり、待機時間の変化は特になし。
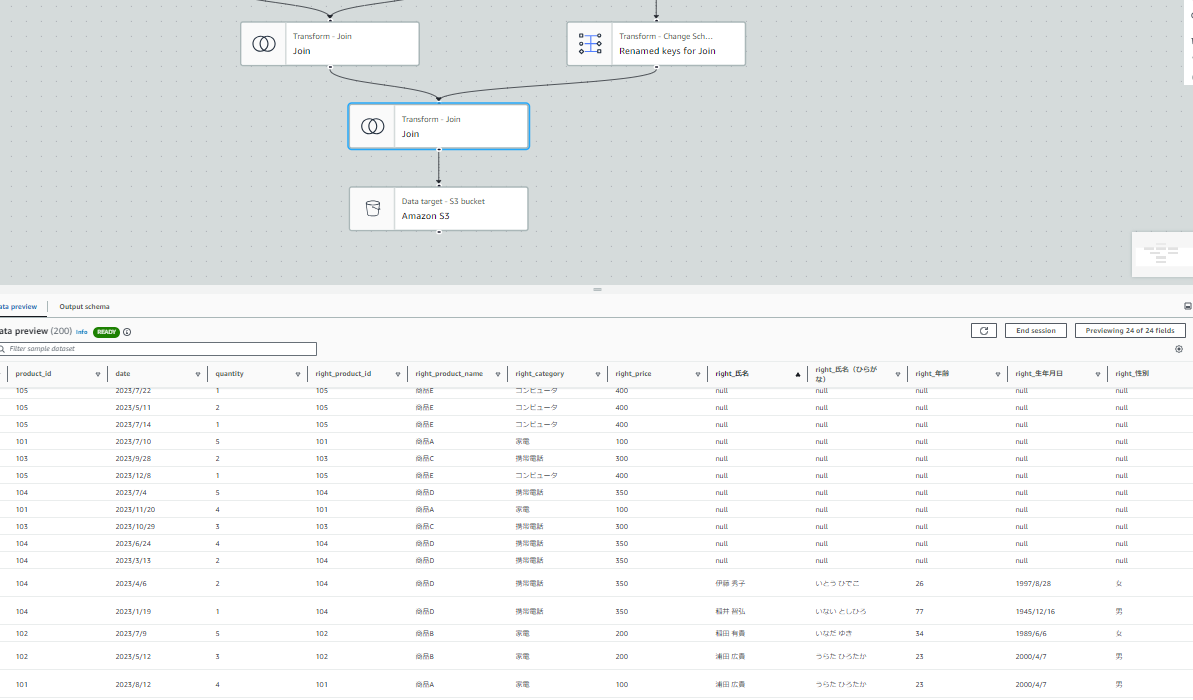
前段階のJOINのノードを参照すると、product_idによる左結合の結果が確認できています。
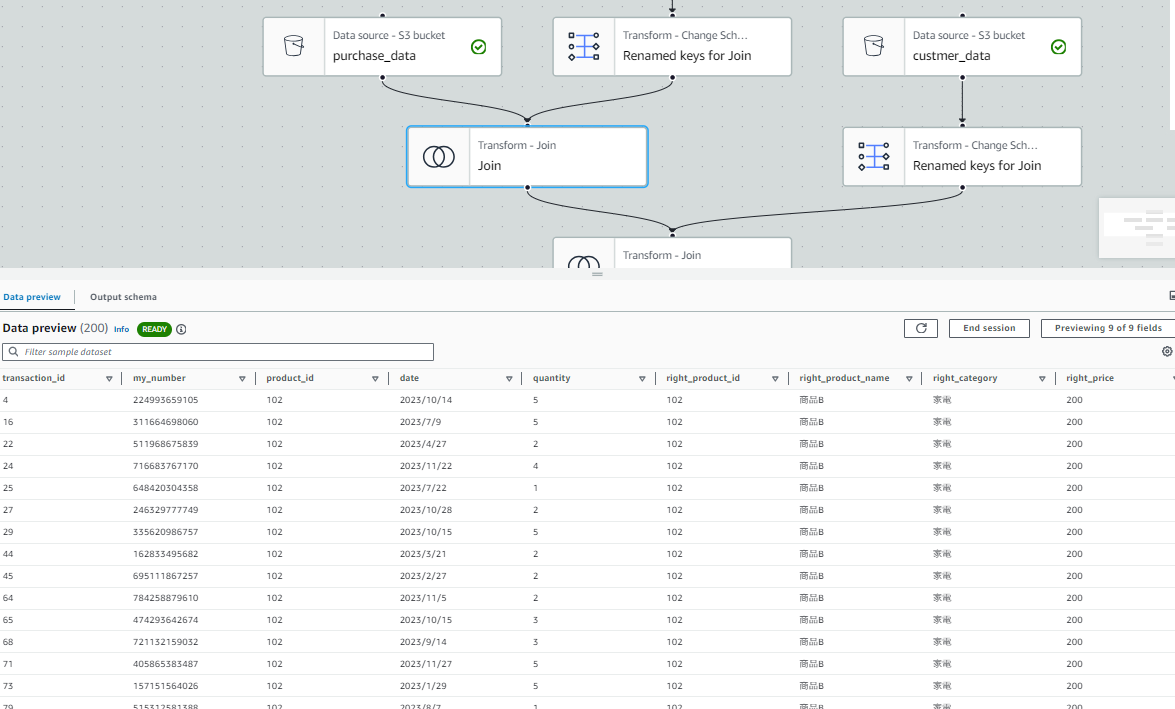
次段階のJOINのノードも問題なく結果が確認できています。データの異常も一目で確認できます。また、ノードごとのデータプレビューの切り替えは数秒で可能です。
まとめ
今回の発表は個人的にはかなり有用な機能と感じました。データプレビュー機能自体は2年程まえからあったようです。しかしながら、一つのセッションで複数のデータセットを確認できないためにノードごとのデータを確認するたびにセッションを開始する必要があり、毎回数分の待機時間が発生してしまっていました。
今後は初回の待機時間のみでストレスフリーなデータプレビューが可能になります。![]()
ユースケース
- これまでは簡単には難しかったレコード単位でのデータ検証
- Custom Transformでコードを用いたデータ変換を行う際のデバッグなど
↓以下はネガティブな内容のまとめです
- エディターが重くなる?
内部的には全体の処理をオンメモリで持っているため?か各ノードの名前変更などの些細な変更であってもかなり重いときがあります。私の場合は使用しているデータは数百KBにも関わらず、データソース:S3の名前をcustomer_dataに変えるキーボード入力が数秒後に反映されるほどにガックガクでした。。
- 料金の増加
基本料金自体はそれなりにします。AWS 公式の料金計算例https://aws.amazon.com/jp/glue/pricing/
を参照するとデータプレビューのセッション中はジョブ実行と同じ料金/DPUが発生します。デフォルトのDPU設定では時間あたり約2.2USD(オハイオ)となり、これに加えてRDSやS3などからのデータ転送量が別途追加されます。