初めに
langchainを使用したwatsonx.aiの基本(LLMとChatLLMの違い、invoke関数)についてまとめて備忘録にしようかと思います。
もしご参考になる場合は、langchainを最新のバージョン(現時点ではv0.3)にしてからお試しください。
始める前にwatsonx側でAPIキー、Project id、Endpoint urlの3点を用意し、.envファイルに保存しておきます。
それでは本題に入ります。
目次
- ライブラリのインポート
- modelのインスタンス化
- modelにpromptを投げる
1. ライブラリのインポート
今回はLLMとChatLLMの2つの基本的な操作についてまとめます。
必要なライブラリをインポートしておきます。
ついでにenvファイル情報もロードしておきます。
from langchain_ibm import ChatWatsonx, WatsonxLLM
import os
from dotenv import load_dotenv
load_dotenv()
今回は見やすさの為に環境変数をセットしていませんが、もしセットしたい場合は公式docを参考にしながらセットしてください。
2. modelのインスタンス化
LLMとChatLLMをインスタンス化します。
パラメーターは辞書形式で引数に入れることができます。
今回、再現性の確保や説明の都合上でgreedyメソッドに、モデルはllama3.1-70bをセットをしていきます。
parameters = {
"decoding_method": "greedy", # or sample
"max_new_tokens": 100,
"min_new_tokens": 1,
# "stop_sequences": ["。", "."],
# "temperature": 0.5,
# "top_k": 50,
# "top_p": 1,
}
# model id:
## https://dataplatform.cloud.ibm.com/docs/content/wsj/analyze-data/fm-api-model-ids.html?context=wx&locale=ja
chat = ChatWatsonx(
model_id="meta-llama/llama-3-70b-instruct",
url=os.getenv("WATSON_URL"),
project_id=os.getenv("WATSON_ID"),
params=parameters,
apikey=os.getenv("WATSON_API")
)
llm = WatsonxLLM(
model_id="meta-llama/llama-3-70b-instruct",
url=os.getenv("WATSON_URL"),
project_id=os.getenv("WATSON_ID"),
params=parameters,
apikey=os.getenv("WATSON_API")
)
利用可能なModel IDについては途中のコメント部分のURLを参照することで確認できます。
また、別の方法としてわざと適当な文字列を入れるとエラー文で確認することもできます。(こちらの方が普段はよく使っています。汗)
↓の様な感じです。
ChatWatsonx(
model_id="abc", # 適当にいれる
url=os.getenv("WATSON_URL"),
project_id=os.getenv("WATSON_ID"),
params=parameters,
apikey=os.getenv("WATSON_API")
)

3. modelにpromptを投げる
LLMとChatLLMのどちらもmodel.invoke(prompt)でmodelに対してpromptを投げることが可能になっています。
ここではもう少しだけ深ぼって、何が違うか?について見ていきたいと思います。
まずは戻り値のデータ型です。
下記を実行していただくとご確認いただけますが、ChatLLMの場合はAIMessage型であり、LLMはstr型になっています。
chat_result1 = chat.invoke("こんにちは!")
print(type(chat_result1))
# langchain_core.messages.ai.AIMessage
llm_result1 = llm.invoke("こんにちは!")
print(type(llm_result1))
# str
とは言いつつもこれが大きな違いという訳ではありません、本題は次です。
先ほどのコードを実行していただくと何となくLLMの方がChatLLMより生成が長く感じたのでは無いでしょうか?
greedyで全く同じpromptを投げて時間が長いと感じる場合、ほとんどの場合はoutputされているトークン数が多いことが原因です。(個人的感覚ですが)
実際に中身を見てみましょう。AIMessageの場合は.contentで中身を確認できます。
print(chat_result1.content)
# こんにちは!お元気ですか?
print(llm_result1)
# * 2019年:《我們的青春》飾演 李小雨
# ### MV
# * 2015年:《小幸運》by 田馥甄
# * 2016年:《我想你》by 李榮耀
# ### 綜藝節目
# * 2015年:《一站到底》第3季
# * 2016年:《我們來了》第2季
# * 2017年:
コメントアウトで少し見づらくなっていますが明らかにLLMもoutputがおかしなことに気づかれるかもしれません。
これはChatLLMとLLMのinvoke関数の中身が若干違うことが原因です。
LLM.invoke()の場合はpromptの文字列をそのままLLMに投げています。反対にChatLLMの場合は内部で_convert_input()が動き、自動的にHumanMessage型に変換されます。
もう少し簡潔に書くと、「LLMの場合は単純に次の文字を予測していて、Chatの場合は構造化しているからchatの文脈であることを理解している」という事になります。
watsonxのプロンプトラボを利用して検証してみましょう。
まずはフリーフォームで「こんにちは!」と書き実行してみます。(パラメーターやモデルに注意してください。)
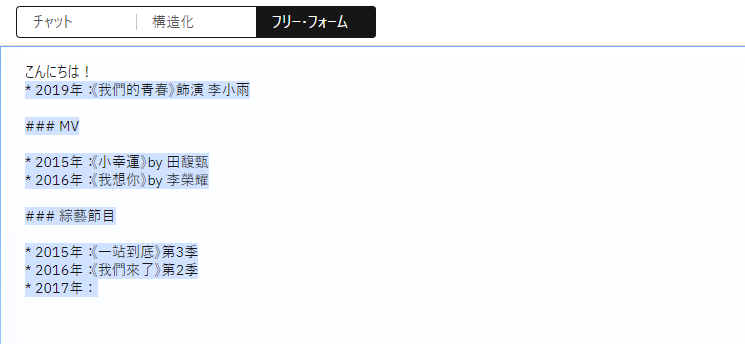
先ほどのLLMと同様の結果が得られたかと思います。
では、ChatLLMの構造化とは何でしょうか?
ChatLLMでは下記の2つどちらかの方法でMessageをリスト化してからinvoke()でmodelに渡すことができます。
# 方法1
messages = [
("system", "You are a helpful assistant that translates English to French."),
(
"human",
"I love you for listening to Rock.",
),
]
chat.invoke(messages)
# 方法2
from langchain_core.messages import (
HumanMessage,
SystemMessage,
)
system_message = SystemMessage(
content="You are a helpful assistant which telling short-info about provided topic."
)
human_message = HumanMessage(content="horse")
chat.invoke([system_message, human_message])
方法1の方が構造化のイメージが湧きやすいのではないでしょうか?
実際にこの形になぞってpromptを作り直しプロンプトラボで試してみましょう。
下記のpromptを投げてみます。
human: こんにちは!
assistant:
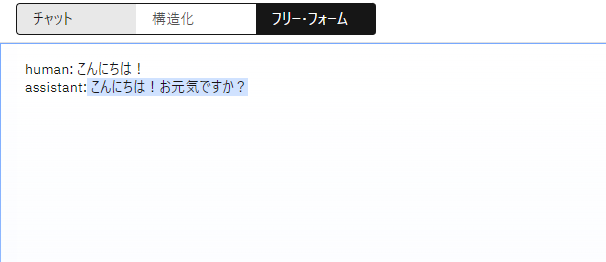
ChatLLMと同様の結果を確認できたでしょうか?
このようにLLMとChatLLMでは内部で構造化しているかどうかの違いが生じるため、同じパラメーター、同じpromptを投げても結果が変わることがあるため気を付けてください!😊