1 アセンブラのすすめ
C言語を学ぶにあたって「ポインタが理解できない」という声を聞くことがある。自分の記憶をたどってみると「ポインタが理解できない」と考えたことは一度も無かった。何故なのか、答えは簡単である。C言語をやる前にアセンブラをやっていたからだ。そしてアセンブラをやることによってポインタで必要となるアドレスの概念だけでなく、レジスタやスタックという高水準言語では直接使うことの無い重要な構造を学ぶことが出来るのだ。今回はx86系32bitを前提に話を進めていきたい。
2 アセンブラを使うにはどうしたらいいのか
統合環境でデバッグまで考えた場合、VisualStudioから扱うのが一番楽だ。
VisualStudio2017のダウンロード先
https://visualstudio.microsoft.com/ja/downloads/
MASMのドキュメント
https://docs.microsoft.com/ja-jp/cpp/assembler/masm/microsoft-macro-assembler-reference?view=vs-2017
VisualStudioは無料のコミュニティ版で十分だ。インストール時は「C++ によるデスクトップ開発」にチェックを入れるべし。これでマクロアセンブラ(MASM)が一緒にインストールされる。実行コマンドはml.exeだ。
3 早速アセンブラに触れてみよう
これから行う流れは、C言語からアセンブラを呼び出す形となる。オールアセンブラで作っても良いのだが、初学でそこから入ると混乱が生じるであろうことは想像に容易い。MS-DOS時代ならそれでも良かったのだが、Windowsを相手にすると作業量が増える。何のことだか一部の人にしか分からないと思うが「INT 21H」で解決していた時代は過ぎ去ったのだ。
3.1 プロジェクトの作成
Windowsコンソールアプリケーション(Visual C++)を作成する。VisualC++2017ではコンソールアプリを作ると、プリコンパイル済みヘッダを利用するための余計なコードが自動生成されてしまう。余計なお世話ではある。しかし空のプロジェクトを作って、リンカの設定をコンソールアプリに直すのも面倒なので、そのままいくことにする。また、デフォルトで生成されるのが32bitの構成なので、アセンブラもそれにあわせて32bitを前提とする。
3.2 アセンブラのソースを作成
Sample.asmというファイルをプロジェクトに追加する。新しい項目の追加から拡張子付きでファイル名を指定すれば、ダイアログ上のファイルの種類が別のものになっていても大丈夫だ。ビルドの設定は後ほど行う。
;WindowsでC言語の命名規則を適用
.model flat, c
;コード領域を宣言
.code
;int sample01(int a,int b)を宣言し引数は自動生成
sample01 PROC a:DWORD,b:DWORD
MOV EAX,a
ADD EAX,b
RET
sample01 ENDP
END
.modelで指定しているのはメモリモデルと命名規則&引数のスタック順序の扱いだ。MS-DOS用のプログラムで無ければflatにしておく。そしてC言語から呼び出されるのが前提ならCとするのが無難だ。C言語の関数の命名規則に従いプロシージャの名前が調整され、引数がスタックに積まれる順序が決定される。何のことだか分からない人は装飾名を見て欲しい。今回の内容ではそれほど重要では無いので、スルーでもかまわない。
.codeはプログラムを置くためのコード領域を指す。他に.dataもあるが、そちらはデータ領域用だ。領域に関しての詳細は後述する。
MOVはデータの代入を行う命令で、右から左へ代入される。ADDは加算命令だ。そして一般命令ではオペランドに以下の規則が適用される。
○ レジスタとレジスタ
○ レジスタとメモリ
× メモリとメモリ
メモリ上にあるデータ同士を足したい場合、最低限どちらかをレジスタに読み出す必要がある。
戻り値は32bit値の場合、EAXレジスタに格納することによって呼び出し元に返すことが出来る。
3.3 C言語(C++)側のソースを作成
# include "stdafx.h"
extern "C" int sample01(int,int);
int main()
{
int a = sample01(10,20);
printf("%d\n",a);
return 0;
}
C言語は外部の関数を呼び出すのにプロトタイプ宣言が必要となる。またexternでCの規則を使うことを宣言しないとデフォルトでC++の規則が適用されてしまい面倒なことになる。
最終的に出力結果が30となれば正解だが、この時点で実行するとエラーになるはずだ。何故ならアセンブラのソースがアセンブルされていないからだ。
3.4 アセンブルの設定
ソリューションエクスプローラからSample.asmのプロパティを出す。
構成をすべての構成に変更後、項目の種類でカスタムビルドツール選択し適用を押す。
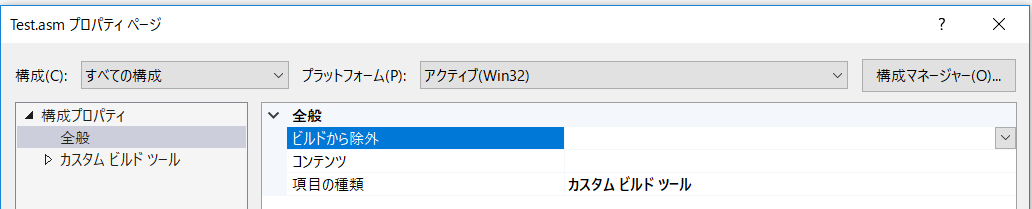
すると構成プロパティにカスタムビルドツールが追加されるので、そこにアセンブル用のコマンドを設定する。
コマンドライン ml /c /coff /Zi /Fo"$(OutDir)%(Filename).obj" "%(Identity)"
出力ファイル $(OutDir)%(Filename).obj
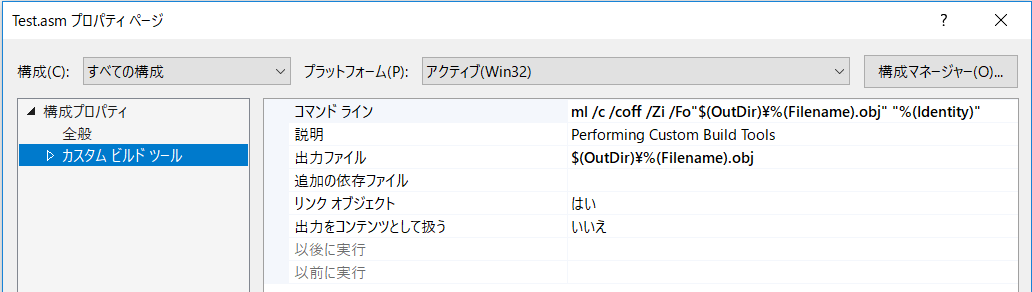
ここまでやると、実行結果を確認することが出来る。うれしいことにアセンブラのソースにブレークポイントを設置すると、デバッグ時にきっちりそこで止まってくれる。アセンブルするためのプログラムも標準で入っているのだから、いっそのこと拡張子との関連付けをデフォルトで行って欲しいところだ。
3.5 実行結果
30
4 レジスタ(32bitの場合)と型
ここではアセンブラを扱う前の前提知識、レジスタとデータ型に関して確認する。
4.1 レジスタの種類
| 種類 | 名前 |
|---|---|
| 汎用 | EAX EBX ECX EDX |
| インデックス | ESI EDI |
| スタック | ESP EBP |
| フラグ | 直接扱わない |
| 実行場所 | EIP |
汎用とインデックス用のレジスタは一部命令で専用の役割を担うものがあるが、演算で必要であれば好きなように使ってかまわない。ただしEAX,ECX,EDX以外はプロシージャから戻る前に、元の値を復元する必要がある。やらなかった場合は、呼び出し元に戻った後に誤作動する可能性がある。
4.2 汎用レジスタの分解
_____________
| EAX | 32bit
| | AX | 16bit
| |AH|AL| 8bit×2
汎用レジスタは16bitや8bitの演算を行うために分解して使用できる。
4.3 データ型
数が多いので主要なものだけ
| 種類 | 内容 |
|---|---|
| BYTE | 1バイト |
| WORD | 2バイト |
| DWORD | 4バイト |
| SBYTE | 1バイト(符号付き) |
| SWORD | 2バイト(符号付き) |
| SDWORD | 4バイト(符号付き) |
符号付きか否かで、演算命令を実行した後のフラグレジスタの扱いが変わる。フラグレジスタは演算結果がマイナス、プラス、ゼロ、オーバーフローなどを判断し、分岐するのに利用される。基本情報に出てくるCASLだと命令の種類で符号ありなしを切り替えるが、MASMでは.ifなどの疑似命令使用時に型を参照して命令を切り替える。
5 領域
| 種類 | 内容 |
|---|---|
| コード | 命令を格納する領域(書き込み不可、データも格納可能だが読み込み専用) |
| データ | 静的なデータを格納する領域(読み書き可能、命令は格納不可) |
| スタック | 一時変数や関数呼び出し時のリターンアドレス、レジスタの値の待避など |
| ヒープ | OSが動的に割り当ててくる領域 |
コード領域はOSによって書き込みが制限されている。MS-DOS時代は自己改変しながら動く芸術的なコードを書くことも出来たのだが、残念ながら現代ではそんなコードはとんでもないとされる。そんな過去の時代にはコード領域に入り込む、狭義の意味での本当のコンピュータウイルスというのが存在した。今ウイルスと呼ばれているのはマルウエアの何かであり、ウイルス以外の別物である。
6 サンプルから学ぶアセンブラ
6.1 スタックの動きを学ぶ
今回はMASMの便利機能を使わず、スタックレジスタを操作して値を取得している。最初のサンプルではPROCの後ろに引数を指定しており、このあたりの処理を自動化していた。
# include "stdafx.h"
extern "C" int sample01B(int a,int b);
int main()
{
int a = sample01B(10,20);
printf("%d\n",a);
return 0;
}
;WindowsでC言語の命名規則を適用
.model flat, c
;コード領域を宣言
.code
;int sample01B(int a,int b)を宣言し引数を自動生成しない
sample01B PROC
PUSH EBP
MOV EBP,ESP
MOV EAX,[EBP+8] ;a
ADD EAX,[EBP+12] ;b
POP EBP
RET
sample01B ENDP
END
このプログラムのPUSH EBP実行後のスタックの状態は以下のようになっている
[EBP+00] EBPを保存した値
[EBP+04] リターンアドレス
[EBP+08] aの値
[EBP+12] bの値
このスタック構造はC言語側から関数を呼び出す時点で作成が始まる
int sample01B(int a,int b);
1 引数bをPUSH
2 引数aをPUSH
3 リターンアドレスをPUSH
4 関数へ飛ぶ
VisualCの標準関数は後ろから前に向かって積まれるが、Win32APIなどは前から後ろに積まれる。今回は標準関数と同じ方式を使っている
アセンブラ側で引数を取り出すときは、PUSH命令によってESPの値が変化するので、スタック内の値の取り出しに直接使うのは適切ではない。そのため一定範囲のスタックの値を取り出したいときはESPの値をEBPに代入し、以降はEBPからスタックのアドレスを指定する
6.2 名前の装飾も自分でやる
# include "stdafx.h"
extern "C" int sample01C(int,int);
int main()
{
int a = sample01C(10,20);
printf("%d\n",a);
return 0;
}
;Windowsで命名規則を使用しない
.model flat
;コード領域を宣言
.code
;int sample01C(int a,int b)を宣言し引数を自動生成しない
PUBLIC _sample01C
_sample01C:
PUSH EBP
MOV EBP,ESP
MOV EAX,[ESP+8] ;a
ADD EAX,[ESP+12] ;b
POP EBP
RET
END
.modelでCを指定しなかった場合、各関数名には自分で先頭に「_」を入れる必要がある。これはMicrosoftのCコンパイラの仕様であり、MS-DOS時代からの伝統である。またPROCキーワードを使用せずにラベルという形で関数名を定義すると、PUBLICキーワードで外部から呼び出される関数だと言うことを知らせなければならない。
6.3 文字列を扱う
# include "stdafx.h"
extern "C" void sample02(char* buff);
int main()
{
char buff[10];
sample02(buff);
printf("%s\n",buff);
return 0;
}
;Windowsで命名規則を使用しない
.model flat,c
;コード領域を宣言
.code
;void sample02(char* buff)
sample02 PROC buff:DWORD
MOV EAX,buff
MOV EDX,'A'
MOV [EAX],EDX
MOV EDX,'B'
MOV [EAX+1],EDX
MOV EDX,'C'
MOV [EAX+2],EDX
XOR EDX,EDX
MOV [EAX+3],EDX
RET
sample02 ENDP
END
アセンブラ側でbuffに"ABC"を書き込むソースだ。[]を使うと対象アドレスへ値を書き込むことが出来る。また、文字列の終端には0が必要となるのでDXレジスタをXORで0にして代入している。
6.4 文字列の転送
# include "stdafx.h"
extern "C" void sample03(char* buff);
int main()
{
char buff[10];
sample03(buff);
printf("%s\n",buff);
return 0;
}
;Windowsで命名規則を使用しない
.model flat,c
;コード領域を宣言
.code
;void sample03(char* buff)
sample03 proc buff:DWORD
PUSH ESI
MOV EAX,buff
XOR ESI,ESI
@@: MOV DL,[DATA+ESI]
MOV [EAX+ESI],DL
INC ESI
AND DL,DL
JNZ @B
POP ESI
RET
DATA BYTE 'ABC',0
sample03 endp
END
データとして文字列を定義し、終端コードの0を転送するまで処理を繰り返す。ちなみにAND DL,DLという一見無意味な処理をしているのは、フラグレジスタに0フラグをセットするためだ。JNZはフラグレジスタのゼロフラグが立っていなかった場合にジャンプする。つまり終端コードを発見するまで繰り返すループが作れるのだ。また@@は汎用ラベルとなっており、「@B」で一つ前の@@へバックし、「@F」で一つ後の@@へとぶ。いちいちラベルの名前を考えるのが面倒なときに重宝する。