Young et al. (2015) "Optimizing deep learning hyper-parameters through an evolutionary algorithm" を読んだので備忘録がてらまとめてみた。
https://www.researchgate.net/publication/301463804_Optimizing_deep_learning_hyper-parameters_through_an_evolutionary_algorithm?enrichId=rgreq-6b2c5de90470641000605ed4fdebe3b6-XXX&enrichSource=Y292ZXJQYWdlOzMwMTQ2MzgwNDtBUzozOTM5MjIyMzgwMDkzNjVAMTQ3MDkyOTc4ODg0OQ%3D%3D&el=1_x_2&_esc=publicationCoverPdf
深層学習に関連したハイパーパラメータ推定はいくつか手法が出ている(強化学習、ベイズ最適化など)が、本論文は遺伝的アルゴリズムを活用してハイパーパラメータの学習を実施している。
(著者は本モデルをMulti-node Evolutionary Neural Networks for Deep Learning (MENNDL)と命名)
論文概要
深層学習のボトルネックとなるハイパーパラメータ調整作業を自動化するため、遺伝的アルゴリズムを活用する。
遺伝的アルゴリズム構成
論文には文章でのみ記述されていたので、図を作成。
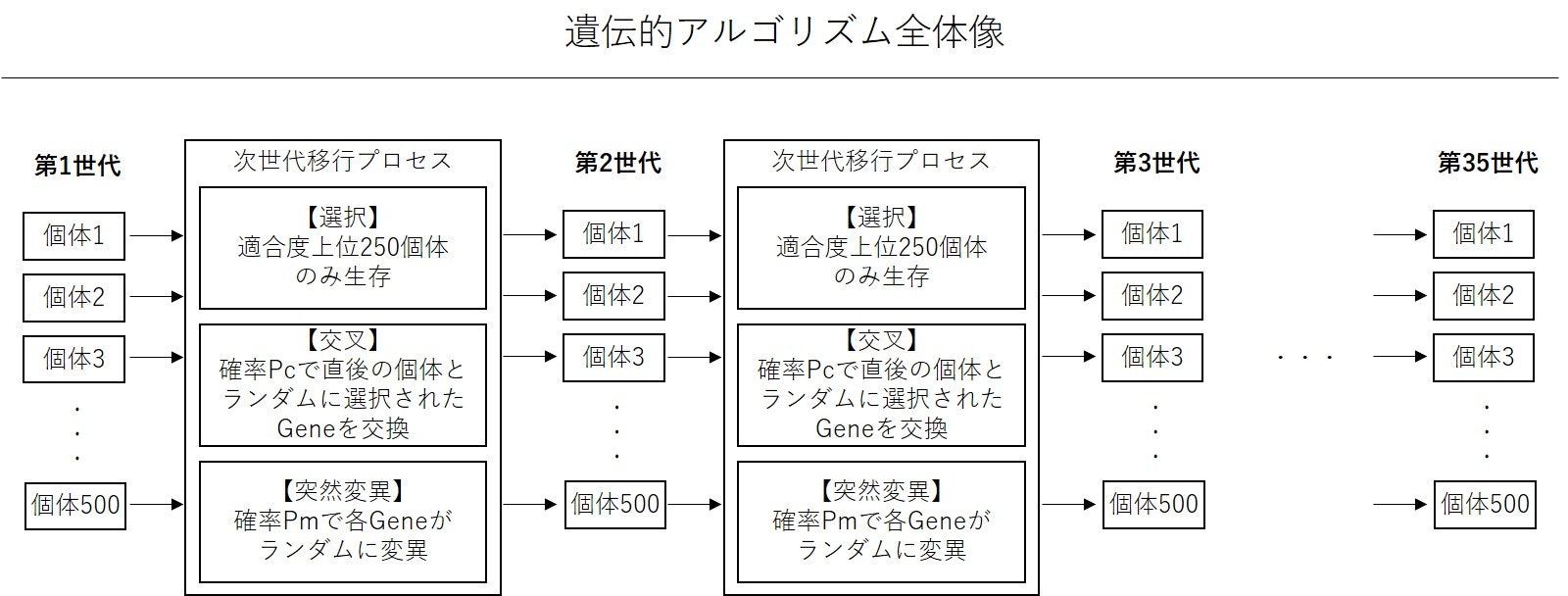
- Gene(学習されるハイパーパラメータ)の数:6 ★詳細は後述
- 世代数:35
- 各世代ごとの個体数:500
- Pc:0.6
- Pm:0.05
選択プロセスにより各世代の500個体から、平均以上のパフォーマンスを残した個体のみを生存される。その後、250個体を元に交叉・突然変異プロセスにより次世代個体500を生成。
第1世代の各個体Gene(初期値)はランダムサンプリングで生成。
論文読んでも分からなかったのが、どうやって選択された250個体から次世代の500個体を生み出すかというプロセスだ。記述がなかったので推測するしかないが、おそらく次世代の個体を生み出す際に、親世代の個体間の交叉で個の個体数を2倍にしているのではないかと想定。
■ 各個体の畳込みニューラルネット(CNN)アーキテクチャ
論文に図があったが、なぜか下から上にネットワーク推定が進む構造になっていたので、90度回転して左から右に進む形に変更した。

近年肥大化する傾向にある畳込みニューラルネットに比べ、かなりシンプルな構造。Caffeを使ったことがないのでわからないが、Caffeのデフォルトアーキテクチャであるとのこと。
図赤字の部分がGeneに相当。第1~3層のフィルタ数、カーネルサイズ、の合計6つ。
プーリング層、全結合層は固定。
赤字の値はCaffeデフォルト値。
後述するが、10カテゴリの判別問題を解く必要があるため、出力層は10個のアウトプット。
4,000回学習を実行しその結果を元に次世代を生成する。
■ モデルの比較・評価
モデル比較・評価にあたって、CIFAR-10データセットを利用。データセットには60,000個の32x32ピクセルのRGB画像データがあり、10個のカテゴリに判別する問題が定義されている。上記うち10,000データはテストデータとして定義されている。
各世代では、このテストデータの10クラス判別問題のエラー率を元に適合度を評価。
モデルの比較対象は上述のCaffeのデフォルトモデル。
恐ろしいことに、Caffeのデフォルトモデルとの比較結果が記述されていない。さすがにデフォルトモデルよりも適合度の高いモデルが生成できたのではないかと想定。。
各世代を比較したところ、世代が進むごとに適合度は向上したとのこと。

上記表ではCaffeのデフォルトモデルと、本モデルの適合度top5モデルとのアーキテクチャを比較している。
著者曰く「興味深いことにカーネルサイズは小さいほうがいいことが示された」とのこと。こ直感的にはカーネルサイズを小さくするとそのレイヤでの表現抽出力が落ちる(あまり複雑な形状は抽出できない)ため、「反直感的」と著者は考えていると推定。。ただ、各レイヤでシンプルな特徴を抽出しながら、それを各層で組み合わせることで複雑な特徴を抽出するのがCNNだ、とも考えられるので、一概に「興味深い」とも言えないかも。自分でモデルを組む際には「カーネスサイズを小さくした方がいいかもしれない」と頭に留めておくことにする。
その他論文では平行座標プロットなどを示しながら結果を記述しているが、果てしなく理解しにくい図である上に、大したことを言っていないため割愛。
コメント
① 比較対象がCaffeのデフォルトアーキテクチャ
そもそも、比較対象がCaffeのデフォルトアーキテクチャという点はいただけない。すでに数多くの画像認識コンテストが開かれていて、トップレベルのアーキテクチャは公開されていたり、他の人が実装していたりするので、それを使って比較するべきだと思う。
著者も言うように、これは遺伝的アルゴリズムでのハイパーパラメータ推定の第1版ともいえる論文なので、将来はそのような比較が実施されるのだろう、きっと。
しかしそれにしても、Caffeデフォルトアーキテクチャと比較してどの程度適合度(エラー率)が改善したか、くらいは載せてほしかった。
② 可変ハイパーパラメータ、アーキテクチャの少なさ
本論文では6つのハイパーパラメータのみが可変となっている。
下記レビューで参照した論文では、各レイヤのアーキテクチャ(畳込み層?プーリング層?など)も可変となっていたためそれと比較するとどうにも少ないという印象を受けてしまう。(論文読む順番間違えたか。。)
https://qiita.com/Soichir0/items/fabf303f00efd22d2c17
③ 遺伝的アルゴリズム x ハイパーパラメータ推定の今後
ハイパーパラメータの推定に関して、強化学習、ベイズ最適化、遺伝的アルゴリズム・・・、どれが優れているかわからない中で、色々試行錯誤がなされている状況。
ただ、遺伝的アルゴリズムの主要プロセスである「選択」「交叉」「突然変異」は人間がハイパーパラメータを試行錯誤して探索するプロセスに似ている気がする。
- いくつかのアーキテクチャを試してみて、結構いいエラー率をはじき出したモデルを中心にさらに検討を進める ≒ 「選択」
- あるアーキテクチャの検討で行き詰った際に、「あ、そう言えば前試したモデルではここをこうしたっけ・・」といった試行錯誤をすることがある ≒ 「交叉」
- さらに行き詰ると、「エイヤッ」であたらしいパラメータをぶち込んでみる ≒ 「突然変異」
そういった意味で、遺伝的アルゴリズムは面白いと思うので、関連文献を引き続き探りながら自分でも実装していきたいと思う。