座標圧縮とは
値の大小関係を保ったまま小さな自然数に変換することを、座標圧縮と呼びます。
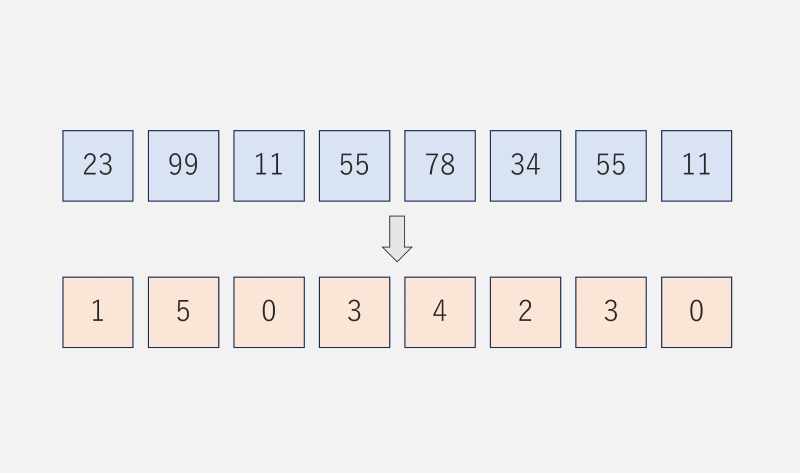
座標圧縮によって値の範囲を小さくすることで、その後の処理にかかる時間を短縮することができる場合があります。特に競技プログラミングの場面では、本質的な操作の前処理として座標圧縮を行うことが多いです。
座標圧縮をライブラリとして設計する場合、関数として設計することが一般的だと思います。以下にC++での実装例を示します。
// O(NlogN)
template<class T>
vector<T> compress(vector<T> &vec){
auto vals = vec;
sort(vals.begin(), vals.end());
vals.erase(unique(vals.begin(), vals.end()), vals.end());
for(int i = 0; i < vec.size(); i++){
vec[i] = lower_bound(vals.begin(), vals.end(), vec[i]) - vals.begin();
}
return vals;
}
引数として配列の参照&vecを受け取り、その中身を圧縮する実装です。返り値のvalsは元の配列に含まれる値を重複を除いて昇順に並べたものです。上の例ではvals = [11, 23, 34, 55, 78, 99]となります。
座標圧縮をクラスとして実装するメリット
座標圧縮を行う際、圧縮前の値を使う予定がないのであれば上に示した実装で十分です。ただし圧縮前の値と圧縮後の値の相互変換が必要な場合は、少し面倒になります。
圧縮前→圧縮後
int idx = lower_bound(vals.begin(), vals.end(), 55) - vals.begin();
cout << idx << endl; // 3
圧縮後→圧縮前
cout << vals[3] << endl; // 55
以上のようにvalsを用いることで目的を達成することはできますが、valsをスコープ内に保持しておかなくてはいけなかったり、圧縮前から圧縮後への変換の文字数が多かったり、あまり積極的に書きたい処理ではありませんでした。特に座標圧縮したのちにセグメントツリーに乗せるような実装では圧縮前から圧縮後への変換が頻出し、実装の煩雑さと可読性の低さに悩んでいました。
そこで座標圧縮クラスを設計することで、上記の処理を次のように書くことができるようになりました。
圧縮前→圧縮後
cout << comp.get_index(55) << endl; // 3
圧縮後→圧縮前
cout << comp.get_value(3) << endl; // 55
ライブラリ全体(CC0 License)
// data と comp の値の相互変換のために get_index, get_value を用意
// comp へのアクセスのために operator[] を用意
// ex)
// data [3, 7, 1, 4, 6, 4, 3, 1]
// comp [1, 4, 0, 2, 3, 2, 1, 0]
// vals [1, 3, 4, 6, 7]
template<typename T>
class Compressor{
vector<T> vals;
vector<int> comp;
public:
// コンストラクタ
// O(NlogN)
Compressor(const vector<T> &data) : vals(data), comp(data.size()){
sort(vals.begin(),vals.end());
vals.erase(unique(vals.begin(), vals.end()), vals.end());
for(int i = 0; i < comp.size(); i++){
comp[i] = lower_bound(vals.begin(), vals.end(), data[i]) - vals.begin();
}
}
// 圧縮前の値 value に対応する圧縮後の値 index を返す
// O(logN)
int get_index(T value){
auto lb = lower_bound(vals.begin(), vals.end(), value);
assert(lb != vals.end() && *lb == value);
return (int)(lb - vals.begin());
}
// 圧縮後の値 index に対応する圧縮前の値 value を返す
// O(1)
T get_value(size_t index){
return vals.at(index);
}
// 圧縮前の配列の index 番目の値を圧縮後の値で返す
// O(1)
int operator[](size_t index) const {
return comp.at(index);
}
// 圧縮後の配列を返す
// O(N)
vector<int> get_compressed_vector() const {
return comp;
}
// 圧縮後の配列のサイズを返す
// O(1)
int size() const {
return vals.size();
}
};
処理も簡潔で読みやすくなりましたし、valsをクラスのメンバ変数にしたことで管理すべき変数を減らすことが出来ました。(圧縮前の値をvalue、圧縮後の値をindexと命名しているのはセグ木に乗せる際に圧縮後の値がインデックスになることが由来です)
まとめ
私は座標圧縮クラスを設計してから、座圧してセグ木に乗せる方針を選択することに抵抗が減りました。些細な改善だとは思いますが、限られた時間でバグらせずに実装するには重要なことだと考えています。
前処理に座標圧縮を行う問題の実装に手間取った経験がある方は、一度使ってみてはいかがでしょうか。
参考:座圧してセグ木に乗せる問題の提出(ネタバレを含みます)
さらなる改善
vector<vector<T>>を入力に受け取れるようにしたら便利そうだなぁ