はじめに

みなさんはPOG(ペーパーオーナーゲーム)をご存知でしょうか?
競馬にまつわるゲームで、デビュー前の2歳馬の仮想馬主となり、1年間の獲得賞金を競います。
このゲームの必勝法はただ一つ。ダービーを勝つ馬を指名することです。
ダービーは同世代の最強の馬を決めるレースで、優勝賞金が2億円とPOG期間中に出走できるレースの中で最も高額なレースになります。
そのためPOG参加者はダービー馬を探すため、本やらネットの情報を必死にかき集め頑張るわけです![]()
今回はそのダービー馬を機械学習で予測してみようという試みです。
既に新馬戦開始から3ヶ月が経過し、出遅れ感はありますが、意外と面白い結果が出たので公開してみることとしました。
手法
RandomForestで回帰を行います。
目的変数には収得賞金を利用しました。
収得賞金とは競走馬のクラス分けに使う基準値で、基本的に高いほど強いという形式が成り立っているため、こちらを採用しました。
使用言語/ライブラリ/ソフトウェア
■TARGET Frontier JV(Windows)
競馬データを自由自在に検索できる有名ソフトウェア。
CSV出力機能があるので、こちらのソフトで競馬データを生成します。
■Microsoft Excel
CSVデータの整形
■Python3
実装言語
Rでも可能かと思いますが、使い慣れているPythonを選択しました。
■sklearn(RandomForestRegressor)
ランダムフォレストの実装
■pandas
CSVのデータ化
(ダミー変数化処理や、numpy arrayへの変換など。)
■matplotlib
予測結果などのグラフ描画
データの準備
- TARGET Frontier JVより競走馬のCSVを出力
- ExcelでCSVを開き、データ処理
- PandasでCSVを開き、データ処理
という順番で、ランダムフォレストで学習できるような形式にデータを整備していきます。
ExcelでのCSV整備はスマートではありませんが、私のPandas力が足りないため、このような手順を踏んでおります![]()
説明変数について
今回予測に利用する説明変数は以下の7つです。
- 性別
- 所属
- 調教師
- 種牡馬
- 馬主
- 生産牧場
- 兄弟勝利数
性別
せん馬、牡馬、牝馬とありますが、こちらはそのまま3カテゴリとしてダミー変数化します。
せん馬は去勢手術をした馬のことで、気性の悪い馬に対して行われるのですが、2歳の段階でせん馬になっている馬は少ないので、特別な考慮は必要無いと判断しました。
なお基本的に、牝馬より牡馬のほうが強い傾向にあります。
所属
競走馬が所属している厩舎が東西どちらにあるか、というデータになります。
美浦が関東、栗東が関西となります。
他にも地方、外国というデータ種別がありますが、特殊なデータとなるため削除した上で、ダミー変数化しました。
調教師
競走馬に調教をつけるのが調教師です。
ハードトレーニングでビシバシやる調教師もいれば、緩めの調教で速い時計を出さない調教師もいます。
やはり一流の調教師と言われるところには、良い馬が入ってくる確率が高くなります。
調教師は200名ほどいて全てダミー変数化すると多いため、勝利数上位の調教師に絞ってダミー変数化し、残りはその他として一括りにしています。
種牡馬
競走馬の父親に当たる馬が種牡馬です。競走馬の場合、同じ馬が1年に100頭以上種づけする場合もあるので、ある程度種類は絞られます。ただ海外から輸入した馬などを含めると、やはり相当な種類となってしまうため、こちらも一部をダミー変数化し、残りはその他としました。
馬主
競走馬のオーナーにあたるのが馬主です。
国内最大のせり市場であるセレクトセールでは、2億、3億という超高価格で競走馬が落札されることもあります![]()
つまりお金持ちです。えぇ。
一番有名な個人馬主である金子真人オーナーは、名馬ディープインパクトをはじめ、ダービー4勝と異常な記録を残しています。有力なオーナーには、せり市場を通さずに直接馬が売買されることもあり(庭先取引といいます)、馬主情報は重要なファクターとなりえます。
こちらも一部をダミー変数化し、残りはその他としました。
生産牧場
競走馬は基本的に、北海道の牧場で生産されます。
中でもノーザンファームという牧場が圧倒的な成績を残しており、1強といった感じです。
こちらも一部をダミー変数化し、残りはその他としました。
兄弟勝利数
成績を残した馬の弟や妹は、人気になりやすく、また結果も残しやすい傾向にあります。
そのあたりは人間と同じでしょうか…?
今回は兄弟馬の中で一番勝利数が多かった馬の勝利数を、整数値(int)として与えています。
兄弟の成績を説明変数としたい場合、兄弟の収得賞金の平均を取るのが良いかと思いますが、今回はTARGETから簡単に出力できるこのデータを利用しました。
予測
競走馬登録されている2歳馬を対象とし、予測を行います。
理由は、競走馬登録されていない馬については、調教師や馬主の情報が入っておらず欠損値になるためです。
頭数としては全体の半分程度(2748頭)になってしまいますが、ダービー目指す馬であればこの時期には登録されている確率は高いため、あまり問題にはならないかと思います。
結果
上位1頭のみを載せてもつまらないので、今回は予測収得賞金が1500万円以上の馬を載せてみます。
ダービーは牡馬/牝馬ともに出走できるのですが、見通しを良くするため、表を分けました。
なお参考として、JRA-VAN POGの指名数の順位を掲載しています。こちらの値が小さいほど、人間の予測上位の馬となります。
牡馬
| 予測収得賞金 | 馬名 | 父 | 母 | POG指名数順位 |
|---|---|---|---|---|
| 8133 | フランクリン | ディープインパクト | ロベルタ | 16 |
| 7910 | アラゴネス | ゴールドアリュール | アンソニカ | 1713 |
| 4736 | リスト | ディープインパクト | シルヴァースカヤ | 14 |
| 3988 | アルテヴェルト | ハーツクライ | アルテリテ | 179 |
| 3774 | ウーリリ | ディープインパクト | ウィキウィキ | 22 |
| 3005 | ミッキースピリット | ディープインパクト | フリーティングスピリット | 130 |
| 2918 | ヴィアロマーナ | ロードカナロア | ローマンエンプレス | 211 |
| 2739 | ブーザー | マンハッタンカフェ | マンドゥラ | 129 |
| 2654 | スマイル | ダイワメジャー | アシュレイリバー | 519 |
| 2649 | ランフォザローゼス | キングカメハメハ | ラストグルーヴ | 41 |
| 2607 | ペルソナデザイン | ハーツクライ | コマーサント | 800 |
| 2601 | ヴァンドギャルド | ディープインパクト | スキア | 132 |
| 2163 | クラージュゲリエ | キングカメハメハ | ジュモー | 52 |
| 2117 | マイネルエキサイト | ブラックタイド | アインライツ | 1924 |
| 1930 | コスモアドム | スクリーンヒーロー | コスモルビー | 2446 |
| 1920 | ミトロジー | ダイワメジャー | リードストーリー | 359 |
| 1882 | アスクフラッシュ | エイシンフラッシュ | レッドデセーオ | 377 |
| 1840 | オメガ | ダイワメジャー | リアリサトリス | 164 |
| 1673 | カントル | ディープインパクト | ミスアンコール | 6 |
| 1671 | エデリー | ディープインパクト | ヴァレリカ | 55 |
| 1651 | ソルドラード | ロードカナロア | ラドラーダ | 2 |
| 1605 | サトノソロモン | ディープインパクト | イルーシヴウェーヴ | 18 |
| 1572 | バイキングクラップ | ハーツクライ | マジックストーム | 26 |
| 1568 | ダノンチェイサー | ディープインパクト | サミター | 8 |
| 1552 | レイズアフラッグ | キングカメハメハ | レディシャツィ | 413 |
牝馬
| 予測収得賞金 | 馬名 | 父 | 母 | POG指名数順位 |
|---|---|---|---|---|
| 6727 | ジョイントベンチャ | スクリーンヒーロー | ヴィエントバイラー | 2690 |
| 6697 | カウディーリョ | キングカメハメハ | ディアデラノビア | 49 |
| 5372 | グランデストラーダ | ハーツクライ | レジェンドトレイル | 238 |
| 5145 | ベルクワイア | ロードカナロア | スカーレットベル | 12 |
| 4906 | ロフティネス | スクリーンヒーロー | フジヤマサクラ | 1323 |
| 3545 | ヴァンランディ | キングカメハメハ | ハッピーパス | 69 |
| 3393 | カレンソナーレ | オルフェーヴル | フィエラメンテ | 240 |
| 3242 | マンドゥーリア | ハーツクライ | アートプリンセス | 1243 |
| 2545 | ブランノワール | ロードカナロア | プチノワール | 172 |
| 2543 | ダイアナブライト | ディープインパクト | チェリーコレクト | 205 |
| 2152 | ヤンチャヒメ | クロフネ | ウエストコースト | 1849 |
| 2021 | グロリアーナ | ハーツクライ | ベネンシアドール | 44 |
| 1765 | ルガールカルム | ロードカナロア | サンデースマイル2 | 207 |
| 1749 | ウイッチクイーン | キングヘイロー | ウイッチトウショウ | 1243 |
| 1568 | フォークテイル | ロードカナロア | フォルクローレ | 373 |
| 1528 | パーソナルビリーフ | ヴィクトワールピサ | パーソナルレジェンド | 600 |
ということで、機械学習で予測するダービー馬は
「フランクリン」(父:ディープインパクト/母:ロベルタ)
となりました!
考察
予測収得賞金1位のフランクリンは、ダービー3着馬アドミラブルと似たプロフィールで、近親に活躍馬がかなり多い血統です。JRA-VAN POGの指名数でも16位と上位で、かなり固めの予測をしてきたな…という感じです。
2位は牝馬のジョイントベンチャという馬でした。特に兄弟に活躍馬はおらず、父スクリーンヒーローが評価ポイントかと思います。スクリーンヒーロー産駒はモーリス、ゴールドアクターと大活躍した馬がいますが、どちらも牝系は優秀ではなく、そのあたりも共通点でしょうか。なお残念ながらこの馬は1走もせず登録抹消してしまったようなので、ダービーで見かけることはないでしょう…。
3位のアラゴネスは、ノーザン×吉田勝己×ゴールドアリュールと、G1馬ゴールドドリームと似たプロフィールで、ダート路線で活躍が見込めそうです。
4位(牝馬2位)のカウディーリョは、母ディアデラノビア、姉ディアデラマドレ共に重賞戦線で活躍した血統馬で、既に新馬戦に出走し快勝しています。ダービーとまではいかなくても、桜花賞・オークスは十分狙えそうです。
なおランダムフォレストでは、特徴量の重要度を算出できますので、グラフ化してみました。
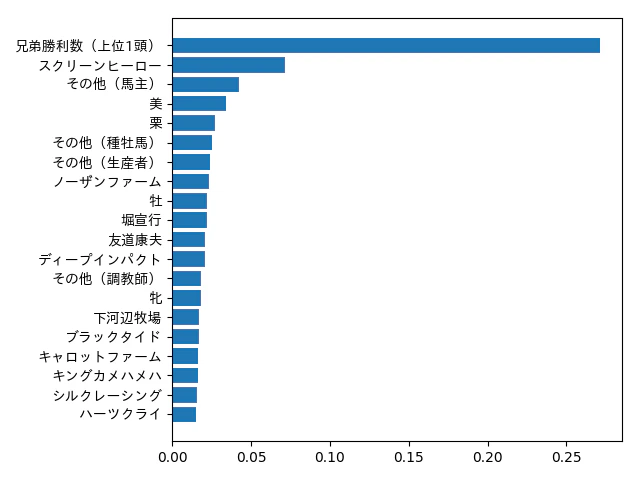
兄弟勝利数の棒が顕著に伸びていますが、これはこの変数だけ整数値であるのが影響しているかと思います(ほかは0,1の論理値)。
またスクリーンヒーロー産駒の重要度が大きいですが、何故でしょうか…?確かに大活躍した馬はいますが、種牡馬ではディープインパクトが一番重要度が大きいと思っていたので、これは意外な結果でした。
コード
今回の予測に使用したコードです。
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
font = {'family':'IPAexGothic'}
horse_table = pd.read_csv('C:/TFJV/TXT/3_7yo.csv',encoding='SHIFT-JIS')
sex_table = pd.get_dummies(horse_table['性別'])
syozoku_table = pd.get_dummies(horse_table['所属'])
trainer_table = pd.get_dummies(horse_table['調教師名'])
sire_table = pd.get_dummies(horse_table['種牡馬名'])
breeder_table = pd.get_dummies(horse_table['生産者名'])
owner_table = pd.get_dummies(horse_table['馬主名'])
analyze_table = pd.concat([sex_table, syozoku_table, trainer_table, sire_table, breeder_table, owner_table, horse_table.loc[:,['兄弟勝利数(上位1頭)','収得賞金']]], axis=1)
X = analyze_table.iloc[:23795, :-1].values
y = analyze_table.loc[:23794, '収得賞金'].values
horse_name = horse_table.loc[:23794, '馬名'].values
# 学習データを使ってモデルを構築する
r_forest = RandomForestRegressor(
n_estimators=500,
criterion='mse',
n_jobs=-4
)
r_forest.fit(X, y)
# 特徴量の重要度の表示
fti = r_forest.feature_importances_
feature_list = []
for i, column_name in enumerate(analyze_table.iloc[:, :-1]):
feature_list.append([column_name, fti[i]])
feature_list = sorted(feature_list, key=lambda x: x[1], reverse=True)
feature_key = []
feature_value = []
for i in range(20):
feature_key.append(feature_list[i][0])
feature_value.append(feature_list[i][1])
feature_key.reverse()
feature_value.reverse()
plt.figure()
plt.barh(range(20),feature_value)
plt.yticks(range(20), feature_key,**font)
plt.tight_layout()
plt.show()
# 2歳馬の予測
X_2yo = analyze_table.iloc[23795:, :-1].values
y_2yo = analyze_table.ix[23795:26522, '収得賞金'].values
horse_name_2yo = horse_table.ix[23795:26522, '馬名'].values
y_2yo_pred = r_forest.predict(X_2yo)
for i, price_predin enumerate(y_2yo_pred.tolist()):
if int(price_pred) > 1500:
print(horse_name_2yo[i],int(price_pred),y_2yo[i])
おわりに
今回はかなりアバウトなデータ整備でしたが、人間の予測と遠くない、もっともらしい結果を出すことができました。
まだまだ予測モデルを詰める余地あると思うので、引き続き研究したいと思います。
また私は機械学習の知識はまだまだですが、競馬については詳しいと思いますので、
プロKagglerの方とタッグを組めれば、かなり魅力的な予測モデルが作れるのではないかと思いました。
もし興味のある方がいらっしゃいましたらご連絡ください![]()