はじめに
Pandasを利用したデータフレームの処理は競技プログラミングてきなアルゴリズムを考えられる能力が必要だと痛感されます。間違ってもfor文を使うなどはできません(基本的には遅いので)
すこし複雑な処理(関数を呼び出すだけでは実現できない)はどのようにすれば効率よく尚且つスマートにできるかということを考えています。
このようなときには、自分でアルゴリズムを考えたうえで、Teratailなどで質問してスマートな回答を募集することでアルゴリズム力を高めるようにしています。
今回もデータフレームの処理でどうにかスマートにできないかと思ったので、まとめたいと思います。
問題
こちらで質問をした内容について以下はまとめていきます。
以下のようなデータフレームがあるとします。
| 属性 | コメント | フラグ |
|---|---|---|
| 患者 | おはようございます。今日もいい天気ですね。どこに行きますか | 1 |
| 患者 | はい | 0 |
| 医師 | かしこまりました。 | 0 |
コメント列には文章が入っていますが、この文章を「。」ごとに区切って複数行に分割します。
最終的にデータフレームは以下のようになります。
| 属性 | コメント | フラグ |
|---|---|---|
| 患者 | おはようございます。 | 1 |
| 患者 | 今日もいい天気ですね | 1 |
| 患者 | どこに行きますか | 1 |
| 患者 | はい | 0 |
| 医師 | かしこまりました。 | 0 |
また条件として、
データフレームは用意されていると仮定していますので、データフレーム作成に利用したリストは利用しないで行いたいです。(ただしto_list()など使えば実現可能なお出それでスマートなら良しとします)
そして、文章分割は3つとは限らず、「。」の数で分割を行います。
このデータフレームを作成するには以下のコードで作成可能です。
import pandas as pd
zoku = ["患者", "患者", "医師", "患者"]
comment = ["おはようございます。今日もいい天気ですね", "はい", "かしこまりました。", "いいえ。そうではないです。"]
flag = [1, 0, 0, 0]
df = pd.DataFrame({'属性':zoku, 'コメント':comment, 'フラグ':flag})
考えたアルゴリズム
私は以下のようなアルゴリズムを考えました。
この方法はTeratailで多くの回答を頂きましたが、その中でもわかりやすくスマートであると思います。(ベストアンサーもよかったので次に紹介します)
import pandas as pd
# データセットの準備
zoku = ["患者", "患者", "医師", "患者"]
comment = ["おはようございます。今日もいい天気ですね。どこに行きますか", "はい", "かしこまりました。", "いいえ。そうではないです。"]
flag = [1, 0, 0, 0]
df = pd.DataFrame({'属性':zoku, 'コメント':comment, 'フラグ':flag})
def split_comment(df, index, index_list, comment_list):
# 日本語の文章では|は利用されないと想定して区切り文字にする
for comment in df["コメント"].replace('。','。|').split('|'):
if comment != '':
index_list.append(index)
comment_list.append(comment)
index_list = []
comment_list = []
df.apply(lambda x: split_comment(x, x.name, index_list, comment_list), axis=1)
comment_df = pd.DataFrame({'コメント':comment_list}, index=index_list)
では詳細を説明します。
まず方針ですが、コメントを分割したものをcomment_list(リスト型)に追加していき、その行のindexをindex_list(リスト型)に追加していきます。
例えば、1行目がsplit_comment関数で処理された後はこのようになります、
comment_list = ["おはようございます。", "今日もいい天気ですね。", "どこに行きますか"]
index_list = [0, 0, 0] # 1行目はindex=0
この処理をすべての行に対して行い、comment_listとindex_listを利用して新たなデータフレームを作成します。

そして、この新たに作ったindexと元のデータフレームのindexをマージして新たなデータフレームを作成することで実現可能です。
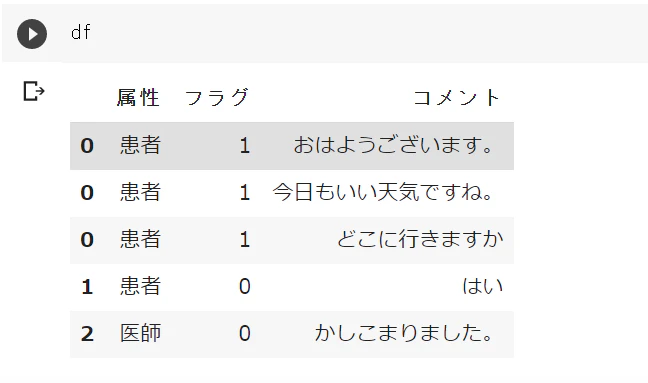
方法1
回答があった方法の一つがこちらです。
import pandas as pd
# データセット準備
zoku = ["患者", "患者", "医師"]
comment = ["おはようございます。今日もいい天気ですね。どこに行きますか。", "はい", "かしこまりました。"]
flag = [1, 0, 0]
df = pd.DataFrame({'属性':zoku, 'コメント':comment, 'フラグ':flag})
# コメントを「。」でリスト分割。リストの長さを変数に代入
df['コメント']=df['コメント'].str.replace('。','。 ').str.split()
df['m']=df['コメント'].apply(lambda x: len(x))
# コメントのリストの長さで複製
df = pd.DataFrame(np.repeat(df.reset_index().values,df.m,axis=0),columns=['インデックス','属性','コメント','フラグ','カウント'])
# リストからの取り出しインデックスを作成
df['カウント']=df.groupby('インデックス').expanding().count()['コメント'] .values.astype('int') - 1
# コメント抽出
df['コメント']=df.apply(lambda x: x['コメント'][x['カウント']],axis=1)
# 不要な列を削除
df.drop(['インデックス','カウント'],inplace=True,axis=1)
内容について詳しく説明していきます。
df['m']=df['コメント'].apply(lambda x: len(x))
この行で1行が何個に分割できるかをデータフレームのm列に追加しています。
上の例ですと、1行目がm=3, 2・3行目がm=1となります。
df = pd.DataFrame(np.repeat(df.reset_index().values,df.m,axis=0),columns=['インデックス','属性','コメント','フラグ','カウント'])
その後、np.repeatを利用して、DataFrame各行をm行複製します。この時、np.repeatを利用するためにdf.reset_index().valuesでarray型にして利用するようにしています。また、reset_index()をすることでインデックス列を新たに追加することができます。前のインデックスはこの後使うことになります。
df['カウント']=df.groupby('インデックス').expanding().count()['コメント'] .values.astype('int') - 1
その後、元のインデックス(の列)でグループ化します。そしてコメント列の同じ要素の数を累積和(expanding().count()['コメント'].values)していきます。累積和-1をすることで、コメント列のリストからどの位置の要素を取ればよいかがわかるようになります。
※ ['コメント']がなくても、インデックスが同じ行はすべてのコメント要素が同じはずですので同じように動作します。
# コメント抽出
df['コメント']=df.apply(lambda x: x['コメント'][x['カウント']],axis=1)
その位置を利用してコメントから該当する要素を取り出してコメント要素に上書きすることで実現しています。
方法2
こちらはとてもシンプルです。
データセット作成は同じです。
import pandas as pd
zoku = ["患者", "患者", "医師", "患者"]
comment = ["おはようございます。今日もいい天気ですね", "はい", "かしこまりました。", "いいえ。そうではないです。"]
flag = [1, 0, 0, 0]
df = pd.DataFrame({'属性':zoku, 'コメント':comment, 'フラグ':flag})
そして、問題を解決するための処理は以下のように行えます。
df.assign(コメント=df['コメント'].str.replace('。', '。 ').str.split()).explode('コメント')
なんと一行でできていしまいました。。。。
こちらも解説します。
df.assign(コメント..をすることで、コメント列の内容を書き換えます。
assign()メソッドで追加・代入
分からない方は参考にしてみてください。
その後で、コメントの内容を先ほどと同じように「。」で分割して、リストに入れます。
df.assign(コメント=df['コメント'].str.replace('。', '。 ').str.split())
ここまでの処理をすると以下のようなデータフレームが作成できます。

※注意: explode()はしていません
そしてとても賢い方法になるのですが(知らなかったのですが)、explodeという関数を利用します。
簡単に説明するとexplode('コメント')とすることで、コメントに配列があった場合にその配列の要素を展開して行に分割してくれます。
今回求めていた処理を関数で一括して行ってくれます。
最後のデータフレームは以下のようになりました。

また、splitの処理を正規表現を用いて表すことも可能です。
df.assign(コメント=df['コメント'].str.split(r'。(?=.)')).explode('コメント')
こちらでも同様の結果が得られます。
正規表現について説明しておきます。
。で「。」があった場合に「。」で文章を分割します。
例えば「おはよう。こんにちは」であれば「おはよう。」「こんにちは」が文章として取り出すことができます。
しかしこの正規表現だけでは問題もあります。
「おはよう。こんにちは。」の場合は「おはよう。」「こんにちは。」「」の三つがリストに入ります。ケーキに2回ナイフを入れるイメージです。
そこで、分割する際にルールとして、「。」で切った後に後ろに1文字以上あるならリストに追加するというルール(?=.)を加えます。
正式には、後ろに一文字以上あるなら「。」にヒットします。

こちらは一部アレンジしました。Teratailでは以下が回答として返ってきています。
df.assign(コメント=df['コメント'].str.split(r'(?<=。)(?=.)')).explode('コメント')
こちらをベストアンサーにしました!
おわりに
今回は、複数行に分割をしましたが同じような処理でつまずく方がいるかと思い参考になればよいなとまとめてみました。
expanding().count()で累積和を求める処理を初めて行ったので大変ためになりました。やはりうまい人のテクニックを学ぶのは大事です。