はじめに
Pandasのgroupbyはとても難しく初心者の壁だと思っています。
私も本格的にさわり初めて日が浅く、どこが原因なのかよくわからない or どうやってアルゴリズムを組めば効率的に実現できるのかと模索する日々です。
時間がかかったものに関してはQiitaに記事としてまとめていますのでご覧ください。
今回は、groupbyで想定していない動きになり困っていたのですが、質問サイトに投稿したところデバックをしていくうちに真相にたどり着いたのでまとめたいと思います。デバックしていなかったら解決に至っていなかった危害します。(よかった)
私と同じようなことになった方がすぐに解決できればと思います。
問題
以下のようなDataFrameがあります。
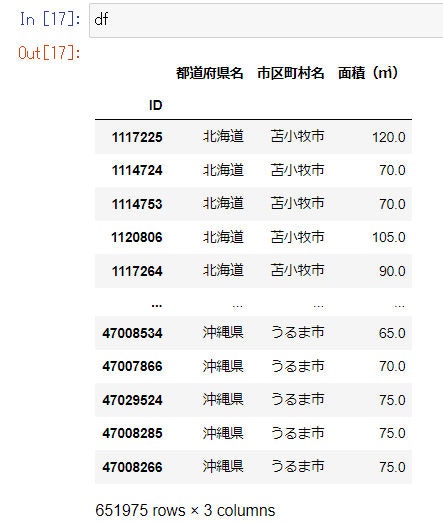
このデータフレームに対して、
「都道府県名が北海道の行だけを抽出して、市区町村名でgroupbyして、市区町村ごとの面積の平均値をだす」という操作を行いました。
df[df["都道府県名"]=="北海道"].groupby('市区町村名').mean()
すると、以下の結果が返ってきました。
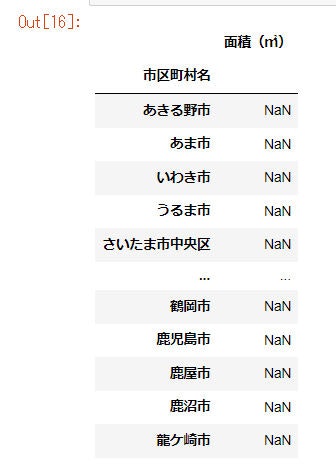
北海道にはあきる市や鹿児島市などはもちろんありません。
また、元のデータフレームは47都道府県、618種類の市区町村があります。
うまく抽出ができていないのかと確認したところすべて北海道、市区町村の数は18個になっていました。
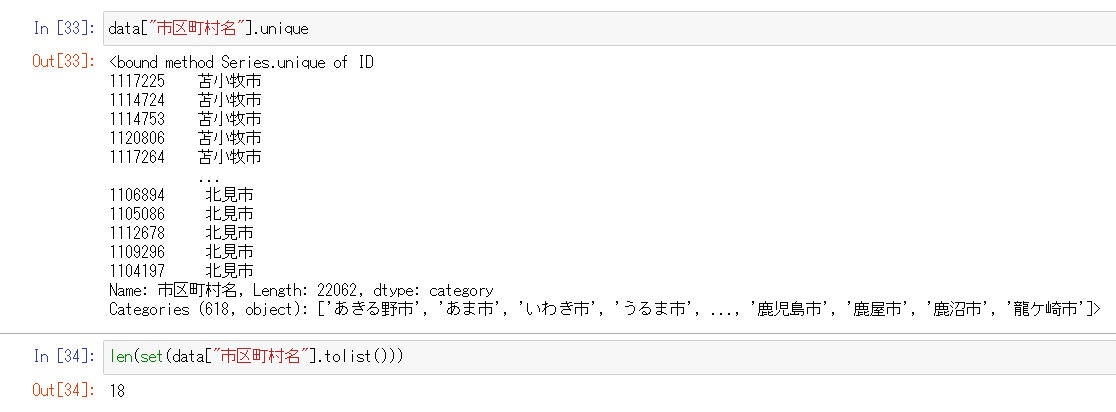
ここでデバックしていて、Categoriesになぜかすべての市区町村名が入っています。おそらくこれが原因なのですが、よくわからずという状態でした。
しかし、このデバックが解決への道となるのでした。
解決方法
原因はこの市区町村名のデータ型がcategory型だったことでした。
実は、LightGBMを動かしており、以下のような処理を前処理として行っていました。

この処理が原因となっていました。
ですので、この処理をしないことで無事、groupbyが成功しました。
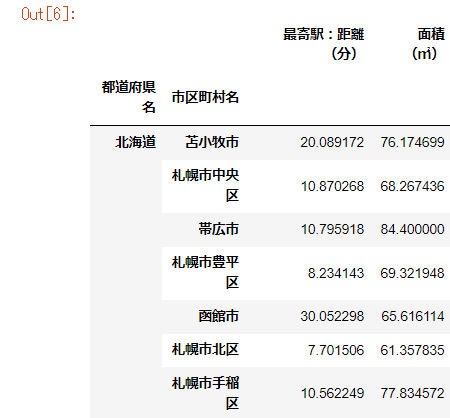
また、どうしてもCategory型で行いたい場合はこのような方法で実現できます。
data.groupby(['都道府県名', '市区町村名'], observed=True).mean()
observed=Trueで実現可能です。
おわりに
DataFrame関係はわからないことばかりですが、同じような問題を例題として用意し、teratailやstack over flowなどで質問してみるとスマートな回答が返ってくることが多いです。
サービスはどんどん活用していくべきだと思います。
参考サイト
Pandasのgroupbyがうまく機能していないので教えていただきたいです。
Pandas groupby with categories with redundant nan