はじめに
こんにちは、イトーです。
Github Actions はこれまで PR を出した際にテストをかけてその成否でマージをブロックしたり、タグを打つとかマージとか何かしらのイベント発生をトリガーとしてアプリケーションをビルドしてクラウドにデプロイしたりするために使ってきました。要するに CI/CD ですね。チェックのためにテストをかけるとかテストステージや本番ステージにデプロイを行うとか定型的な作業をガッツリ削れることになり、怠惰なるエンジニアとしては大変ありがたい限りです。
さて、今回はこの「楽できる仕組み」を機械学習に持っていけないかと思いまして、最近 GA した Azure Machine Learning CLI v2 と Github Actions を組み合わせる方法を思いつきました。
機械学習もソフトウェア開発の一種、もっと言うとデータから関数を作成するある種の自動プログラミングと捉えることができそうです。エンジニアはデータの前処理やモデルの構造を定義し、モデルを作る学習の工程は計算機上で自動実行されます。なんだか「ビルド」っぽくないですかね。そういうことなら、機械学習モデルを定義するコードを書いてリモートリポジトリに push した場合に自動で「ビルド」(つまり学習)が走るようになれば機械学習エンジニアは楽できそうです。そういう環境を1つ構築してみようと思います。
そしてこちらが試しに構築したリポジトリです。まずコード見せろという方はこちらをご覧ください。
方針
Github の main ブランチに変更があった場合に自動で機械学習ジョブを発行して、 Azure Machine Learning 上で実行するようにしたいと思います。
そこで Azure Machine Learning CLI v2 を使います。これは az ml のコマンドとジョブの定義を記述した yaml によって Azure Machine Learning に対して機械学習ジョブを発行したりその他にも色々できるというもので、シンプルなコマンド実行と静的なファイル群でジョブを定義して実行できるあたりが Github Actions と相性が良さそうと思いました。
Azure Machine Learning CLI v2 についてはつい先ほど記事を書いたので、使い方の一例を見てみたい方は以下をどうぞ。
構築
事前準備
Azure Machine Learning CLI v2 ジョブ準備
こちらの記事で使用した train.py に対してハイパーパラメーターチューニングをかけるジョブを使い回そうと思います。事前準備や前提条件なども含めて以下記事に沿います。
まず、Azure Machine Learning Workspace デプロイ後にその名前と Workspace が所属するリソースグループの名前を Github のリポジトリにシークレットとして登録します。絶対に隠さなければならない情報というわけでもない気がしますしこれらの情報をコードやワークフロー定義にべた書きしてもそれほど害はないと思いますので、お好みで。
あるいは組織のシークレットとして登録しておくと後で Azure Machine Learning Workspace を別のものに変える場合などに一括で変更出来て楽かもしれないですが、このあたりは運用体制によりそうです。今回はリポジトリにシークレットとして登録しておきます。
名前は
- AZURE_RESOURCE_GROUP_NAME
- AZURE_ML_WORKSPACE_NAME
としておきます。
続いて job/search_hyperparameter.yml として以下 yaml を用意しておきます。
コードは src/train.py として保存されている想定です。(同じ内容なので記載しません、上記記事を参照してください)
$schema: https://azuremlschemas.azureedge.net/latest/sweepJob.schema.json
type: sweep
trial:
code: ../src
command: >-
python train.py
--input_dataset_name ${{inputs.dataset_name}}
--boosting_type ${{inputs.boosting_type}}
--metric ${{inputs.metric}}
--num_iteration ${{inputs.num_iteration}}
--learning_rate ${{search_space.lr}}
--num_leaves ${{search_space.num_leaves}}
--min_data_in_leaf ${{search_space.min_data_in_leaf}}
environment:
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:20220504.v1
conda_file: ../environment.yml
inputs:
dataset_name: nyc_taxi_dataset
boosting_type: gbdt
metric: rmse
num_iteration: 300
compute: azureml:cpu-cluster
sampling_algorithm: bayesian
search_space:
lr:
type: uniform
min_value: 0.001
max_value: 0.5
num_leaves:
type: uniform
min_value: 10
max_value: 200
min_data_in_leaf:
type: uniform
min_value: 1
max_value: 100
objective:
goal: minimize
primary_metric: best_rmse
limits:
max_total_trials: 100
max_concurrent_trials: 8
timeout: 7200
experiment_name: job_nyc_taxi_regression_cli_v2_parameter_tuning
description: Hyper-parameter tuning job
# https://docs.microsoft.com/en-us/azure/machine-learning/reference-yaml-job-sweep
ジョブで使用する依存ライブラリを定義する environment.yml は root 直下に配置する想定で、以下のように準備します。
name: env-ml-reposiotry-azureml-cli-v2
channels:
- conda-forge
- defaults
dependencies:
- python=3.8
- lightgbm=3.3.2
- pandas=1.4.2
- numpy=1.22.4
- scikit-learn=1.1.1
- mlflow=1.26.1
- pip:
- azureml-core==1.42.0
- azureml-mlflow
- flake8==4.0.1
- isort==5.10.1
- black==22.3.0
- mypy==0.961
- azureml-opendatasets
- types-python-dateutil==2.8.17
- pre-commit==2.19.0
ローカルでの開発時に使うパッケージ依存も含んでいるので色々増えちゃってるあたりがちょっと良くないですね。ジョブはジョブ、ローカル開発はローカル開発で environment.yml も分けた方が良かったかもとは思ってますが、特段問題が出てないので今回はこれでいきます。 (そもそも本当は poetry を使いたいけど機械学習だと色々面倒が多いので諦めたという経緯)
認証設定
Github Actions から Azure 側リソースである Azure Machine Learning に対してジョブを発行するためには、何かしら権限を持ったユーザーとしてログインしている必要があります。
サービスプリンシパルというシークレットや証明書を使って認証する仕組みか OpenID Connect の2択になりますが、シークレット流出事故を回避したいので後者にしようと思います。
こちらに沿って設定を進めていきます。ガイド通りの部分については割愛します。
フェデレーション資格情報で「資格情報の追加」を行う際、以下のように設定しました。
- Entity type: Branch
- Based on selection: main
続いて登録したアプリケーションから以下の情報を Github のリポジトリにシークレットとして登録します。
- AZURE_TENANT_ID
- AZURE_CLIENT_ID
- AZURE_SUBSCRIPTION_ID
アプリの登録→所有しているアプリケーションと辿って登録したアプリケーションを開くと上記情報を確認することができます。
Github Actions ワークフロー定義
.github/workflows 以下に yaml を書いていきます。
name: Run Azure Login with OpenID Connect
on:
push:
branches:
- 'main'
paths:
- src/**
- job/**
permissions:
id-token: write
contents: read
jobs:
job-deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v3
- name: az CLI login
uses: azure/login@v1
with:
client-id: ${{ secrets.AZURE_CLIENT_ID }}
tenant-id: ${{ secrets.AZURE_TENANT_ID }}
subscription-id: ${{ secrets.AZURE_SUBSCRIPTION_ID }}
- name: Install ML extension for az command
run: az extension add -n ml -y
- name: Create ML Job
run: az ml job create -f ./job/search_hyperparameter.yml -g ${{ secrets.AZURE_RESOURCE_GROUP_NAME }} -w ${{ secrets.AZURE_ML_WORKSPACE_NAME }}
main ブランチに push ないしはマージされた際、ジョブ定義ファイルがある job ディレクトリと学習に使うスクリプトがある src ディレクトリ配下に変更があった場合に Azure Machine Learning に対してジョブを submit します。
az ml job create コマンドはジョブの終了を待たずジョブの作成が完了した時点で処理終了となるため、機械学習ジョブが終わるまで延々と Github Actions が動き続けて枠を消費することはありません。
動作確認
src に変更を加えた PR をマージしたところ、ワークフローが動きました。
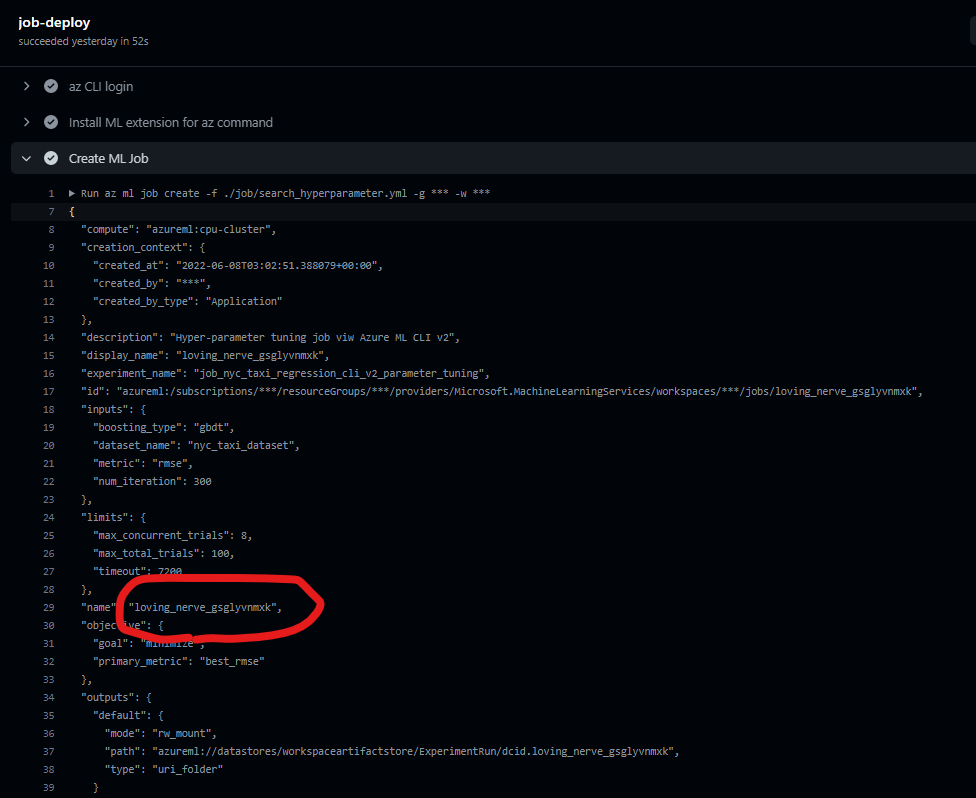
loving_nerve_gsglyvnmxk という名称の Run が生成された様子です。
Azure Machine Learning で確認すると、確かに同名のジョブがあり、学習が行われていました。
実行当時のスクリプトも保存されている様子です。実験の再現性確保の観点では非常にありがたいです。

Git のどのコミットから生じたジョブかも記録されている様子です。

おわりに
Github Actions で機械学習の CD (CT とでも呼べば良いのでしょうか)を行うことができました。
実験の実行についてあまり気を払うことなくモデルやその周辺のコードの変更に集中できる環境への第1歩です。