0.Prologue
暇つぶしに、興味を引いた DNNアプリを *Interpに移植して遊んでいる。
本稿はその雑記&記録。
先日、拙作TflInterpを用いて "DeepFill v2"というDNNモデルを Elixirで動かす記事を書いた:「*Interp移植録 - 消しゴムマジック / DeepFill v2 (TflInterp)」
実のところ、移植作業の心臓部は Tensorflow liteのカスタム演算子の作成だったのだが、C/C++でごにょごにょという内容で、あの記事の趣旨からは外れるので詳細は割愛した。とはいえ小生のこと、せっかく調べた作成法をすぐに忘れてしまいそうなので、ここに外伝として書き留めておこうと思う![]()
1."ExtractImagePatches"の仕様
ここで実装するカスタム演算子は、"DeepFill v2"の移植に必要な ExtractImagePatchesだ。正しくは、ExtractImagePatchesはカスタム演算子ではなく、Tensorflow liteで選択可能なTF2演算子のひとつなのだが……公式ドキュメントによると、選択可能演算子の組み込みには、共有ライブラリ"tensorflowlite_flex"が必要なうえに、バイナリサイズが 5~25倍になるかもしれないとのことだった。たった一つの演算子を使いたいだけなのに、この対価は大き過ぎる。そんな訳で、ExtractImagePatchesはカスタム演算子だと偽って、より軽量に組み込もうという魂胆である![]()
さて、ExtractImagePatchesの公式仕様は下記のリンク先にある。
tf.compat.v1.extract_image_patches(
images,
ksizes=None,
strides=None,
rates=None,
padding=None,
name=None
)
ExtractImagePatchesの作用をちゃんと理解するために、Pythonで少し試してみよう。
入力は {1, 2, 3,..., 100}が並んだ [1 x 10 x 10 x 1]の Tensorとする。サンプリング・ポイントksizesは [3 x 3]、サンプリング・ウインドの移動量stridesは全方向 1、サンプリング・ポイントの間隔ratesは全方向 1、最後にパディングpaddingは"SAME"(サンプリング・ウインドが入力Tensorからはみ出すことを許し、はみ出した部分は 0と見做す)としよう。
Pythonでの実行結果は次の通り。
>>> import numpy as np
>>> import tensorflow as tf
>>> t = tf.constant(np.arange(1,101), shape=(1,10,10,1))
>>> t.shape
TensorShape([1, 10, 10, 1])
>>> patches = tf.compat.v1.extract_image_patches(t, ksizes=[1,3,3,1], strides=[1,1,1,1], rates=[1,1,1,1], padding="SAME")
>>> patches.shape
TensorShape([1, 10, 10, 9])
>>> patches[:,0:3,0:3,:]
<tf.Tensor: shape=(1, 3, 3, 9), dtype=int32, numpy=
array([[[[ 0, 0, 0, 0, 1, 2, 0, 11, 12],
[ 0, 0, 0, 1, 2, 3, 11, 12, 13],
[ 0, 0, 0, 2, 3, 4, 12, 13, 14]],
[[ 0, 1, 2, 0, 11, 12, 0, 21, 22],
[ 1, 2, 3, 11, 12, 13, 21, 22, 23],
[ 2, 3, 4, 12, 13, 14, 22, 23, 24]],
[[ 0, 11, 12, 0, 21, 22, 0, 31, 32],
[11, 12, 13, 21, 22, 23, 31, 32, 33],
[12, 13, 14, 22, 23, 24, 32, 33, 34]]]])>
図示すると下記の様になる。要するに、入力Tensorからサンプリングした要素をズラッと並べたベクトルを、そのサンプリング位置(row/col)における要素とする Tensorを作る演算子ということのようだ。
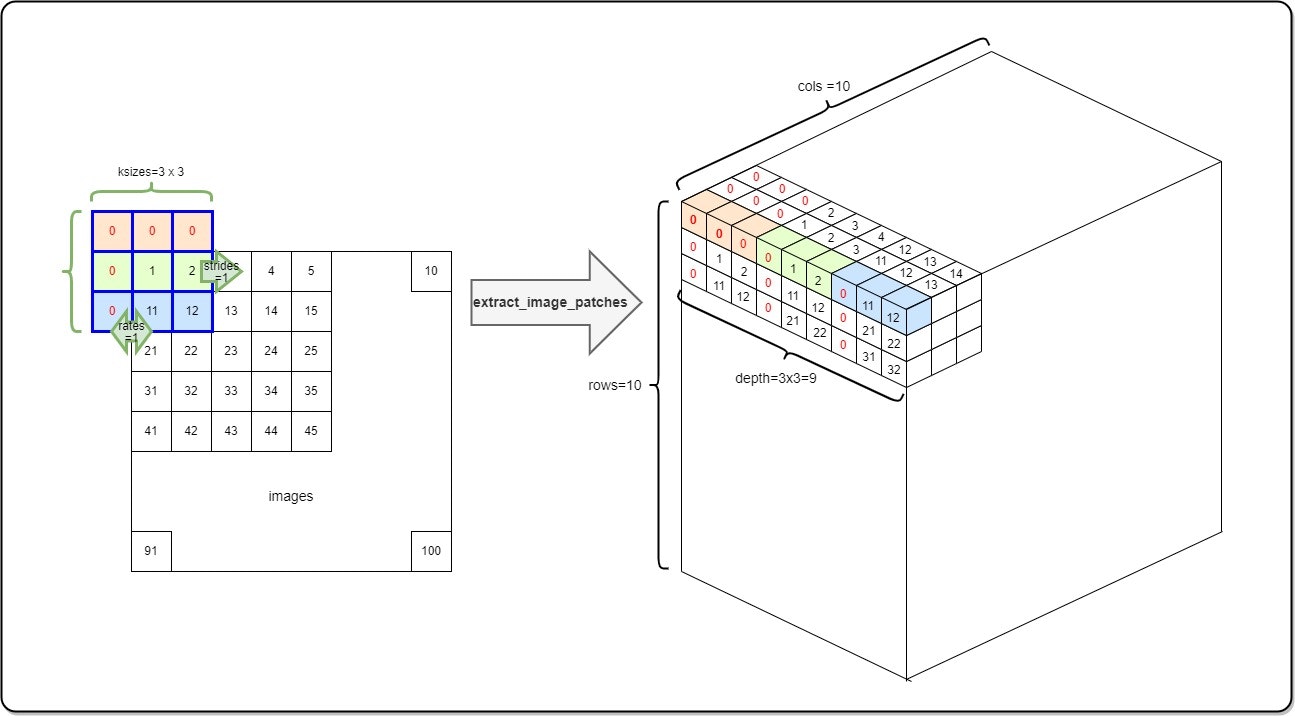
尚、"DeepFill v2"は、rates=[1,1,1,1], padding="SAME"固定で ExtractImagePatchesを呼び出すので、ちょっと手抜きして実装しても良いだろう。
2.カスタム演算子の作成手順
カスタム演算子の公式ドキュメントは下記のリンク先にある。このドキュメントでは、簡単なカスタム演算子の例をあげてその作成手順を説明しているのだが……残念ながら小生にはよく分からなかった。
他に詳しい情報はないかと探しみるもののこれといったモノは見当たらず、結局 Tensorflow liteのソースファイルに同梱のMaxPoolWithArgMaxのコードを参考にした。
カスタム演算子の作成では4つの関数 - Init,Free,Prepare,Eval - を用意する。前者2つは演算子の仕様によっては要らないこともある。
-
void* Init(TfLiteContext* context, const char* params, size_t length):
tfliteインタプリタがモデルを読み込む際、そのグラフのノードにカスタム演算子が現れる度に呼び出される関数。引数paramsにはカスタム演算子のパラメタが渡されるので、後続の処理のためにパースして状態変数(構造体)に保存する用途に用いる。引数paramsに渡されるパラメタのフォーマットは FlatBuffersの flexbuffer形式。 -
void Free(TfLiteContext* context, void* state):
Init関数で作成した状態変数を破棄する用途に用いる。 -
TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node):
演算子の実行に先立ち、ノードの入力テンソルのサイズが通知されるので、それに合わせて出力テンソルのサイズを調整する用途に用いる。Init関数で作成した状態変数はnode->user_dataで参照できる。 -
TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node):
演算子の実行。nodeから入力テンソル、node->user_dataから状態変数(パラメタ)を取り出し、演算結果をnodeの出力テンソルに返す用途に用いる。
これら4つの関数を構造体TfLiteRegistrationにまとめ、tfliteインタープリタの resolverに登録すればカスタム演算子が利用できるようになる。
尚、flexbuffer形式のパースや nodeからの入出力テンソルの取り出し等の処理は、Tensorflow liteのコードの中に用意されているので、それを借用するのが良いだろう。
3.実装
MaxPoolWithArgMaxを真似て書き起こした ExtractImagePatches演算子のコードは以下の様になった。
外部に公開するインターフェイスは、Register関数custom_operations::RegisterExtarxtImagePatchesだけである。それ以外の具体的な実装は無名名前空間(unnamed namespace)の中に隠している。
#ifndef EXTRACT_IMAGE_PATCHES_H
#define EXTRACT_IMATE_PATCHES_H
#include "tensorflow/lite/kernels/internal/types.h"
#include "tensorflow/lite/kernels/kernel_util.h"
namespace custom_operations {
TfLiteRegistration* RegisterExtractImagePatches();
} // namespace custom_operations
#endif
"extract_image_patches.cc"では、2章でみた4つの関数Init,Free,Prepare,Evalを実装している。ExtractImagePatchesの演算の実体は、Evalの中には置かずテンプレート関数として分離している。今回の実装では、dtype=float32のケースにしか対応していないが、将来の拡張に向けての布石である。
Init関数では、パラメタ ksizes,strides,rates,paddingを状態変数 OpDataに保存している。後続処理の Prepare関数、Eval関数は、この状態変数に保存されたパラメタを取り出し、各種計算に利用している。flexbuffer形式のパラメタのパースには、Tensorflow liteに用意されている flexbuffers::GetRootを借用した。
Prepare関数では、入力テンソルのサイズとパラメタから出力テンソルのサイズを計算しているのだが、paddingを考慮したこの計算は少々面倒である。そこで、Tensorflow liteに用意されているtflite::ComputePaddingHeightWidthを借用することにした。この関数は出力テンソルのサイズのほかに、padding="SAME"の場合のパディング量を返してくるので、その値を状態変数経由で Eval関数に渡してサンプリングの調整に利用している。
あとは、コードを読めば何をしているか分かるかな![]()
#include "extract_image_patches.h"
#include "flatbuffers/flexbuffers.h" // from @flatbuffers
#include "tensorflow/lite/kernels/internal/tensor.h"
#include "tensorflow/lite/kernels/padding.h"
namespace custom_operations {
namespace {
/*** Module Header ******************************************************}}}*/
/**
* ExtractImagePatchesの実体
* @par description
* 入力テンソルと与えられたパラメタから image patchテンソルを作成する。
**/
/**************************************************************************{{{*/
// パラメタは構造体ExPatchParamsにパッキングして渡す
struct ExPatchParams {
int filter_height; // <= ksizis[1:3]
int filter_width;
int stride_height; // <= strides[1:3]
int stride_width;
int rate_width; // <= rates[1:3]
int rate_height;
tflite::PaddingValues padding_values; // <= padding
};
template <typename T>
inline void ExtractImagePatches(
const ExPatchParams& params,
const ::tflite::RuntimeShape& input_shape,
const ::tflite::RuntimeShape& output_shape,
const T* input_data,
T* output_data)
{
TFLITE_DCHECK_EQ(input_shape.DimensionsCount(), 4);
TFLITE_DCHECK_EQ(output_shape.DimensionsCount(), 4);
const int32_t batches = MatchingDim(input_shape, 0, output_shape, 0);
const int32_t input_height = input_shape.Dims(1);
const int32_t input_width = input_shape.Dims(2);
const int32_t input_depth = input_shape.Dims(3);
const int32_t output_height = output_shape.Dims(1);
const int32_t output_width = output_shape.Dims(2);
const int32_t stride_height = params.stride_height;
const int32_t stride_width = params.stride_width;
for (int32_t batch = 0; batch < batches; batch++) {
for (int32_t out_y = 0; out_y < output_height; out_y++) {
for (int32_t out_x = 0; out_x < output_width; out_x++) {
// 出力テンソルの(out_y, out_x)の位置に書き込む image patchを入力テンソルからサンプリングする
const int32_t in_x_origin = (out_x * stride_width) - params.padding_values.width;
const int32_t in_y_origin = (out_y * stride_height) - params.padding_values.height;
T* patch = output_data + Offset(output_shape, batch, out_y, out_x, 0);
for (int32_t filter_y = 0; filter_y < params.filter_height; ++filter_y) {
for (int32_t filter_x = 0; filter_x < params.filter_width; ++filter_x) {
const int32_t in_x = in_x_origin + filter_x*params.rate_width;
const int32_t in_y = in_y_origin + filter_y*params.rate_height;
if ((0 <= in_x && in_x < input_width) && (0 <= in_y && in_y < input_height)) {
for (int32_t channel = 0; channel < input_depth; ++channel) {
*patch++ = input_data[Offset(input_shape, batch, in_y, in_x, channel)];
}
}
else {
// 入力テンソルからはみ出す部分の値は 0と見做す
for (int32_t channel = 0; channel < input_depth; ++channel) {
*patch++ = 0;
}
}
}}
}}}
}
// flexbuffer形式等のデータから情報を取り出すためのインデックス
constexpr int kDataInputTensor = 0;
constexpr int kDataOutputTensor = 0;
constexpr const char kSizesStr[] = "ksizes";
constexpr const char kStridesStr[] = "strides";
constexpr const char kRatesStr[] = "rates";
constexpr const char kPaddingStr[] = "padding";
constexpr const char kPaddingSameStr[] = "SAME";
constexpr const char kPaddingValidStr[] = "VALID";
// 状態変数: パラメタから演算に必要な情報だけを取り出して保持する
struct OpData {
int k_height;
int k_width;
int stride_height;
int stride_width;
int rate_height;
int rate_width;
TfLitePadding padding;
struct {
TfLitePaddingValues padding;
} computed;
};
/*** Module Header ******************************************************}}}*/
/**
* Init関数
* @par description
* パラメタを解析し、演算に必要な情報を状態変数OpDataに保存する
**/
/**************************************************************************{{{*/
void* Init(TfLiteContext* context, const char* params, size_t length)
{
// Tensorflow liteに用意されている'flexbuffers::GetRoot`を借用して paramsをパースする
const flexbuffers::Map& m =
flexbuffers::GetRoot(reinterpret_cast<const uint8_t*>(params), length)
.AsMap();
OpData* op_data = new OpData;
// The first and last element of sizes are always 1.
const auto sizes = m[kSizesStr].AsTypedVector();
TFLITE_CHECK_EQ(sizes.size(), 4);
TFLITE_CHECK_EQ(sizes[0].AsInt32(), 1);
TFLITE_CHECK_EQ(sizes[3].AsInt32(), 1);
op_data->k_height = sizes[1].AsInt32();
op_data->k_width = sizes[2].AsInt32();
// The first and last element of strides are always 1.
const auto strides = m[kStridesStr].AsTypedVector();
TFLITE_CHECK_EQ(strides.size(), 4);
TFLITE_CHECK_EQ(strides[0].AsInt32(), 1);
TFLITE_CHECK_EQ(strides[3].AsInt32(), 1);
op_data->stride_height = strides[1].AsInt32();
op_data->stride_width = strides[2].AsInt32();
// The first and last element of rates are always 1.
const auto rates = m[kRatesStr].AsTypedVector();
TFLITE_CHECK_EQ(rates.size(), 4);
TFLITE_CHECK_EQ(rates[0].AsInt32(), 1);
TFLITE_CHECK_EQ(rates[3].AsInt32(), 1);
op_data->rate_height = rates[1].AsInt32();
op_data->rate_width = rates[2].AsInt32();
const std::string padding = m[kPaddingStr].AsString().str();
if (padding == kPaddingValidStr) {
op_data->padding = kTfLitePaddingValid;
}
else if (padding == kPaddingSameStr) {
op_data->padding = kTfLitePaddingSame;
}
else {
op_data->padding = kTfLitePaddingUnknown;
}
return op_data;
}
/*** Module Header ******************************************************}}}*/
/**
* Free関数
* @par description
* 状態変数を破棄する
**/
/**************************************************************************{{{*/
void Free(TfLiteContext* context, void* state)
{
delete reinterpret_cast<OpData*>(state);
}
/*** Module Header ******************************************************}}}*/
/**
* Prepare関数
* @par description
* 入力テンソルのサイズに合わせて出力テンソルのサイズを調整する
**/
/**************************************************************************{{{*/
TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node)
{
// Init関数で保存したパラメタを取り出す
OpData* op_data = reinterpret_cast<OpData*>(node->user_data);
TF_LITE_ENSURE_EQ(context, ::tflite::NumInputs(node), 1);
TF_LITE_ENSURE_EQ(context, ::tflite::NumOutputs(node), 1);
TfLiteTensor* output =
::tflite::GetOutput(context, node, kDataOutputTensor);
const TfLiteTensor* input =
::tflite::GetInput(context, node, kDataInputTensor);
TF_LITE_ENSURE_EQ(context, ::tflite::NumDimensions(input), 4);
TF_LITE_ENSURE_EQ(context, input->type, kTfLiteFloat32);
TF_LITE_ENSURE_EQ(context, output->type, kTfLiteFloat32);
int batches = input->dims->data[0];
int height = input->dims->data[1];
int width = input->dims->data[2];
int channels_out = input->dims->data[3];
// Tensorflow liteに用意されているtflite::ComputePaddingHeightWidthを借用して paddingを考慮した出力テンソルのサイズを計算する
int out_height, out_width;
op_data->computed.padding = ::tflite::ComputePaddingHeightWidth(
op_data->stride_height, op_data->stride_width,
op_data->rate_height, op_data->rate_width,
height, width,
op_data->k_height, op_data->k_width,
op_data->padding,
&out_height, &out_width);
TfLiteIntArray* output_size = TfLiteIntArrayCreate(4);
output_size->data[0] = batches;
output_size->data[1] = out_height;
output_size->data[2] = out_width;
output_size->data[3] = channels_out * op_data->k_height * op_data->k_width;
return context->ResizeTensor(context, output, output_size);
}
/*** Module Header ******************************************************}}}*/
/**
* Eval関数
* @par description
* 演算を実行する (注意:dtype=float32のみ対応)
**/
/**************************************************************************{{{*/
TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node)
{
// Init関数で保存したパラメタを取り出す
OpData* op_data = reinterpret_cast<OpData*>(node->user_data);
ExPatchParams op_params;
op_params.filter_height = op_data->k_height;
op_params.filter_width = op_data->k_width;
op_params.stride_height = op_data->stride_height;
op_params.stride_width = op_data->stride_width;
op_params.rate_height = op_data->rate_height;
op_params.rate_width = op_data->rate_width;
op_params.padding_values.height = op_data->computed.padding.height;
op_params.padding_values.width = op_data->computed.padding.width;
TfLiteTensor* output =
::tflite::GetOutput(context, node, kDataOutputTensor);
const TfLiteTensor* input =
::tflite::GetInput(context, node, kDataInputTensor);
// 演算実体のテンプレート関数を呼ぶ
switch (input->type) {
case kTfLiteFloat32:
ExtractImagePatches<float>(op_params, ::tflite::GetTensorShape(input), ::tflite::GetTensorShape(output),
::tflite::GetTensorData<float>(input), ::tflite::GetTensorData<float>(output));
break;
default:
TF_LITE_KERNEL_LOG(context, "Type %s not currently supported.", TfLiteTypeGetName(input->type));
return kTfLiteError;
}
return kTfLiteOk;
}
} // namespace
/*** Module Header ******************************************************}}}*/
/**
* Register関数
* @par description
* 上記4つの関数Init,Free,Prepare,Evalを構造体TfLiteRegistrationにまとめる
**/
/**************************************************************************{{{*/
TfLiteRegistration* RegisterExtractImagePatches() {
static TfLiteRegistration reg = { Init, Free, Prepare, Eval };
return ®
}
} // namespace custom_operations
tfliteインタープリタへのカスタム演算子の組み込みは概ね次のコードの様になる。インタープリタを生成する前に、resolverにカスタム演算子の名前と共に上で用意した TfLiteRegistration構造体を登録すればよい。
std::unique_ptr<tflite::Interpreter> interpreter;
// tfliteモデル(FlatBuffers)の読み込み
std::unique_ptr<tflite::FlatBufferModel> model = tflite::FlatBufferModel::BuildFromFile(tfl_model.c_str());
// カスタム演算子の組み込み
tflite::ops::builtin::BuiltinOpResolver resolver;
resolver.AddCustom("ExtractImagePatches", custom_operations::RegisterExtractImagePatches());
// tfliteインタープリタの生成
tflite::InterpreterBuilder builder(*model, resolver);
builder(&interpreter);
if (interpreter->AllocateTensors() != kTfLiteOk) {
std::cerr << "error: AllocateTensors()\n";
exit(1);
}
4.動作テスト
では、実装した ExtractImagePatchesが思い通りに動くか少々試してみよう。テストケースは1章のモノと同じでよいかな。
tfliteインタープリタでの動作確認なので、テスト用の tfliteモデルが必要になる。次のPythonスクリプトで作成する。カスタム演算子を有効にするために、converterのallow_custom_opsを Trueに設定している。モデル・ファイルの名前は"test_eip.tflite"。
import tensorflow as tf
from tensorflow import keras
inputs=keras.Input(shape=(10,10,1))
outputs = tf.compat.v1.extract_image_patches(inputs, ksizes=[1,3,3,1], strides=[1,1,1,1], rates=[1,1,1,1], padding='SAME')
model = keras.Model(inputs, outputs)
model.save('test_eip')
converter = tf.lite.TFLiteConverter.from_saved_model('test_eip')
converter.allow_custom_ops = True
tflite_model = converter.convert()
open('test_eip.tflite', 'wb').write(tflite_model)
手持ちの環境では、拙作のTflInterpでテストするのが最も楽なので、ちょこちょこっとテスト用のモジュールTestEipをElixirで書く。
defmodule TestEip do
alias TflInterp, as: NNInterp
use NNInterp,
model: "./model/test_eip.tflite",
inputs: [f32: {1,10,10,1}],
outputs: [f32: {1,10,10,9}]
def apply(t) do
# prediction
output = session()
|> NNInterp.set_input_tensor(0, Nx.to_binary(t))
|> NNInterp.invoke()
|> NNInterp.get_output_tensor(0)
|> Nx.from_binary(:f32) |> Nx.reshape({1,10,10,:auto})
end
end
1.0~100.0が並んだ入力テンソルtを用意して、TestEip.apply/1に喰わせてみる……ふむ、結果は上々のようですな![]()
iex> t = Nx.linspace(1, 100, n: 100) |> Nx.reshape({1,10,10,:auto})
#Nx.Tensor<
f32[1][10][10][1]
[
[
[
[1.0],
[2.0],
[3.0],
[4.0],
[5.0],
[6.0],
[7.0],
[8.0],
[9.0],
[10.0]
],
...
]
]
>
iex> patches = TestEip.apply(t)
#Nx.Tensor<
f32[1][10][10][9]
[
[
[
[0.0, 0.0, 0.0, 0.0, 1.0, 2.0, 0.0, 11.0, 12.0],
[0.0, 0.0, 0.0, 1.0, 2.0, 3.0, 11.0, 12.0, 13.0],
[0.0, 0.0, 0.0, 2.0, 3.0, 4.0, 12.0, 13.0, 14.0],
[0.0, 0.0, 0.0, 3.0, 4.0, 5.0, 13.0, 14.0, 15.0],
[0.0, 0.0, 0.0, 4.0, 5.0, 6.0, 14.0, 15.0, 16.0],
[0.0, 0.0, 0.0, 5.0, 6.0, ...],
...
],
...
]
]
>
iex> patches[0][[0..2, 0..2]]
#Nx.Tensor<
f32[3][3][9]
[
[
[0.0, 0.0, 0.0, 0.0, 1.0, 2.0, 0.0, 11.0, 12.0],
[0.0, 0.0, 0.0, 1.0, 2.0, 3.0, 11.0, 12.0, 13.0],
[0.0, 0.0, 0.0, 2.0, 3.0, 4.0, 12.0, 13.0, 14.0]
],
[
[0.0, 1.0, 2.0, 0.0, 11.0, 12.0, 0.0, 21.0, 22.0],
[1.0, 2.0, 3.0, 11.0, 12.0, 13.0, 21.0, 22.0, 23.0],
[2.0, 3.0, 4.0, 12.0, 13.0, ...]
],
...
]
>
5.Epilogue
ExtractImagePatchesを題材として、Tensorflow liteのカスタム演算子の作成を紹介した。
Prologueで述べた通り「消しゴムマジック」のような画像処理を試したくて始めた取り組みだが、カスタム演算子の作成方法がなかなか分からず随分と時間が掛かってしまった。まぁ、当初の目的は達成できたので、良しとしよう![]()
Appendix
-
*Interp移植録 - 消しゴムマジック / DeepFill v2 (TflInterp)
https://qiita.com/ShozF/items/218a49841c47b2f360d7 -
ExtractImagePatchesの動作テスト・モジュール
https://github.com/shoz-f/tfl_interp/tree/main/test_eip