まえがき
今回はDurability向上のため、ディスク(HDD、SSD等の2次記憶装置)への読み書きを実装します。今まではErlangのETSというメモリ上のキーバリューストアに保存していましたが、プロセスが死ぬとデータが全て吹っ飛んでいくので、Durabilityもなにもなかったわけです。実装のポイントは、「ファイル編成」と「バッファ・キャッシュ」です。
さて、みなさんRDBを使っている中で、どれだけディスクへの読み書きを意識しているでしょうか。ほとんどないですよね。当たり前です。ディスクへどんな風に書き込んでいるか、どんな風に呼び出しているのか、気にしなくて済むためにRDBMSがいるのですから。RDBを触る時は表形式のテーブルを頭の中にイメージするのが普通です。
逆に、RDBMSを実装する側はどのようにディスクへデータを書き込み、読み込むのか管理しなければならない。そこで出てくるのがファイル編成です。
ファイル編成
『ファイル編成法(— へんせいほう)とはコンピュータがディスク装置やテープ装置などの2次記憶装置上に、レコードをどのように配置しアクセスするかについての方式である。』(Wikipediaより)
例えば、XMLのようにタグをつけてなんのデータかわかるように構造化して書き込むか。1レコード1行となるように改行を使って書き込むか。じゃあどうやってデータを取り出すか。全行読み込んで必要なレコードを探すのか??
そういったことを考えていきます。
ディスク上でのデータの持ち方
RDBMSもOS上で動くアプリケーションですから、ディスク読み書きとはファイルへの読み書きと言えます。Erlangではfileモジュールによって、様々なファイルアクセスメソッドが利用できます。fileモジュールのmanページ
ここでは、指定された場所に対してデータの読み書きはできるものとします。
- 先頭からxバイト目からyバイト目までのデータを読み込む
- 指定された場所にデータを書き込む(テキストエディタに文字を書き込むようなデータ挿入のイメージではない。上書きするイメージ。)
具体例を使って、どうファイルを編成するか考えてみます。
1テーブル1データファイルという構成で想定してください。
検討ポイントはいくつかあります。
- レコードは新規挿入・更新・削除される
- 1レコードのデータ長はとても短いかもしれないし、バイナリデータなど長いものかもしれない
- レコード更新の際は、データ長が短縮、もしくは伸長するかもしれない
- レコードは100万行・1000万行と大量になるかもしれない
- カラム名称やサイズの変更、カラム追加、カラム削除されるかもしれない
- 指定のデータに高速にアクセスできる必要がある
一方、ファイルはバイトストリームですから、ファイルの途中を削除した場合、それ以降のデータは削除された分だけ前に詰められます。逆に、ファイル途中にデータを挿入した場合、それ以降のデータは挿入された分だけ後ろに移動します。
そこで考えられたのが下のようなファイル編成です。
ファイルは、ページという固定長バイト列(4KB)を1ページ、2ページと積み重ねることで構成します。図中一つのセルが1バイトとします。今回は簡単のため1ページ256バイトとしています。

ページはページヘッダ、スロット、パディング、データから成ります。
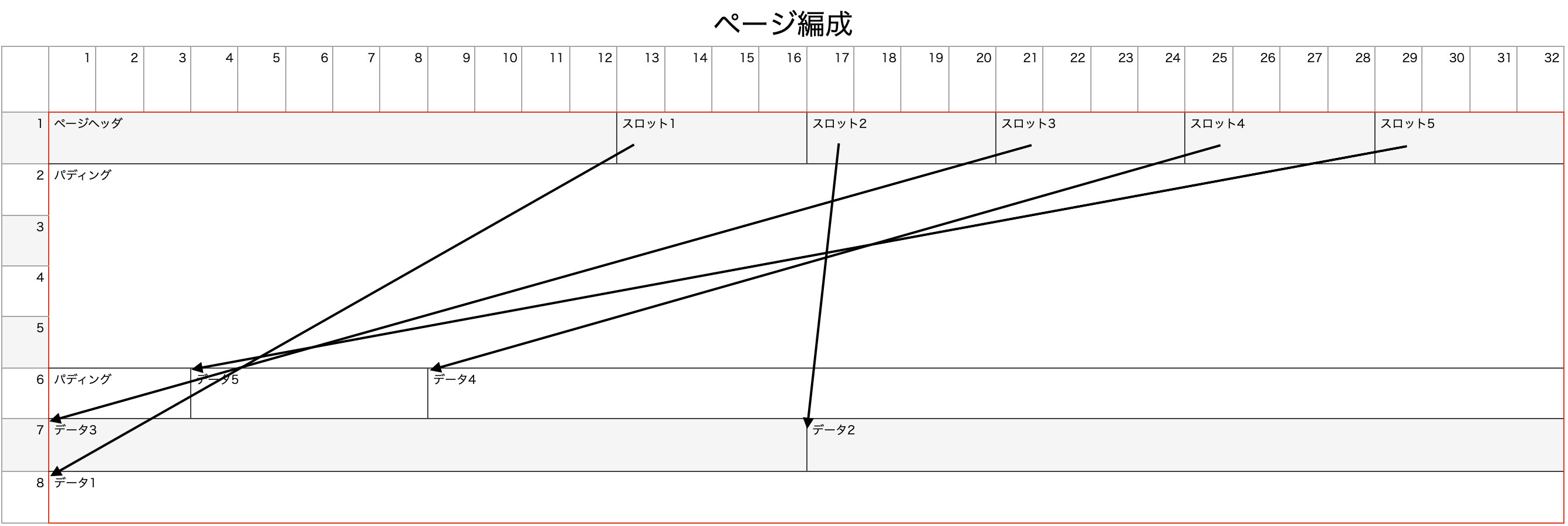
- ページヘッダは固定長のデータで、空き容量、保持しているスロット数などのメタデータを保持する
- スロットは各データへのページ内のオフセットを保持する。データとスロットは1対1で存在する。1ページに5レコード保持しているならスロットも5個。各スロットが各データへのオフセットを保持する
- データはそのままレコードデータのこと
- パディングはページが固定長になるよう調整する役
例えば、データ5個入ったページは下記のような構成になります。
ヘッダ→スロット1→スロット2→スロット3→スロット4→スロット5→パディング→データ5→データ4→データ3→データ2→データ1
スロット1はデータ1へのオフセットを保持します。(図中の矢印)
以下、あるページに対して、データのCRUDを行う際の挙動を説明します。
データ挿入
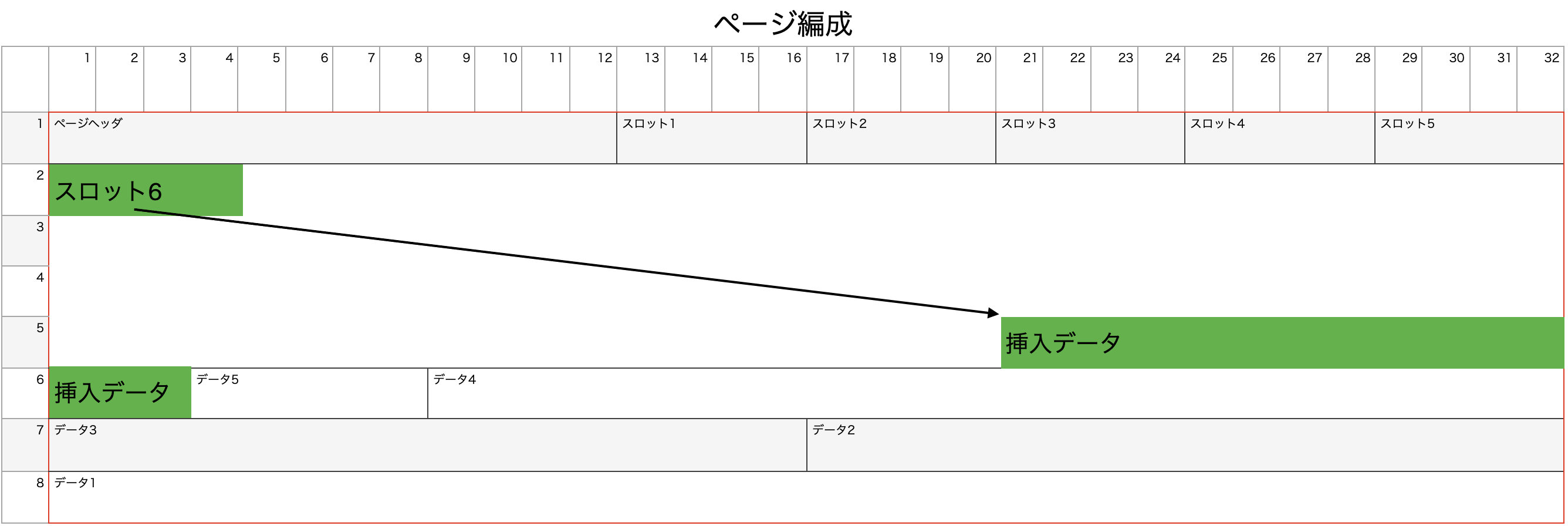
上図のように、データを挿入する場合、挿入データとそこへのオフセットを表すスロットの2つのデータを挿入します。スロットはページ内を右側に伸びるようにデータを書き込んでいきます。データは左側に伸びるように書き込んでいきます。これは、今までに格納されているデータ位置を変更したくないからです。
ページが一杯になるまで(パディングが無くなるまで)、このページへデータを書き込むことができます。
%%----------------------------------------------------------------------
%% データをディスクに書き込むページに変換する関数
%%----------------------------------------------------------------------
data2page(#disk_data{data_list=SlotDataList}) ->
% SlotList = [{2,["orange","120"]},{1,["apple","100"]}]
{EmptySize, SlotCount, BinData} = construct_data(lists:reverse(lists:keysort(2, SlotDataList))),
[construct_header(SlotDataList, EmptySize, SlotCount), BinData].
%% ヘッダを作成する(12バイト)
construct_header(_Data, EmptySize, SlotCount) ->
<<0:32, EmptySize:32/integer, SlotCount:32/integer>>.
construct_data(Data) ->
[#slot{slot_n=SlotCount} | _] = Data,
{{OffsetList, DataList}, DataSize} = slot2page(Data, SlotCount, {[], []}, 0),
PaddingSize = ?PAGE_SIZE - (?HEADER_SIZE + DataSize),
Ret = [lists:map(fun (X) -> <<(X+PaddingSize):(?SLOT_SIZE*8)/integer>> end, OffsetList),
<<0:(8*PaddingSize)>>,
DataList],
{PaddingSize, SlotCount, Ret}.
%% [{2,["orange","120"]},{1,["apple","100"]}]
%% -> {[15, 0], ["orange 120", "apple 100"]}
slot2page(_Rest, 0, {OffsetList, DataList}, CurOffset) ->
{{OffsetList, lists:reverse(DataList)}, CurOffset};
slot2page([#slot{slot_n=SlotCount, data=Data} | Rest], SlotCount, {OffsetList, DataList}, CurOffset) ->
PlainData = list_to_binary(lists:join(?DATA_DELIMITER, Data)),
DataByteSize = byte_size(PlainData),
slot2page(Rest, SlotCount - 1, {[CurOffset | OffsetList], [PlainData | DataList]}, CurOffset + DataByteSize + ?SLOT_SIZE);
slot2page(Rest, SlotCount, {OffsetList, DataList}, CurOffset) ->
slot2page(Rest, SlotCount - 1, {[CurOffset | OffsetList], DataList}, CurOffset + ?SLOT_SIZE).
slot2pageは[apple, 100]と[orange, 120]というデータを挿入するとしたら、下記のように{[15,0],["orange 120", "apple 100"]}というデータに変換する。タプルの左の項はデータへのオフセットのリスト、右の項はデータのリストで、ページに書き込む順序になるよう逆順になっている。オフセットはパディングを含まない状態のオフセットである。下記のように。
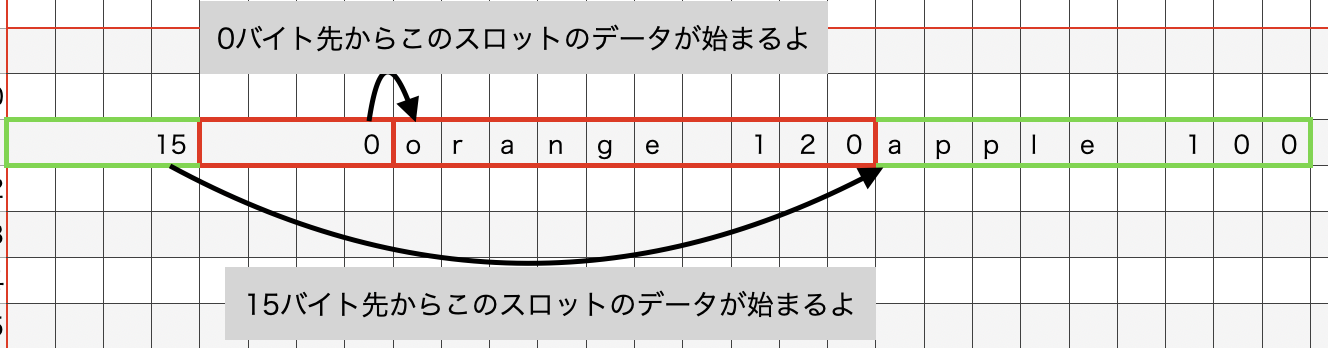
construct_dataでページサイズが規定のサイズになるようパディングを詰めて、オフセットリストの全要素をパディングの分だけ増やす。
construct_headerでヘッダをつけて1ページ分のデータが出来上がり。
データ取得
データはページとスロット番号を指定することで特定できます。実装としては、指定のページの指定のスロットから所望のデータへのページ内オフセットを求めて、そのデータを取得し返却する、ということになります。
%% スロットが2つの場合のデータのイメージ<<0,0,0,15,0,0,0,0,"orange 120apple 100">>
%% 初めの4バイトがスロット1のデータへのオフセット、次の4バイトがスロット2のデータへのオフセットを保持
read_slot(_Data, 0, _) ->
[];
read_slot(<<Offset:(?SLOT_SIZE*8)/integer, Rest/binary>>, SlotCount, SlotNum) ->
<<RestData:Offset/binary, Data/binary>> = Rest,
[#slot{slot_n=SlotNum, data=parse_data(binary_to_list(Data))} | read_slot(RestData, SlotCount - 1, SlotNum + 1)].
オフセットを元にデータを取り出していきます。データ構造としてはslot1,slot2,padding,data1,data2のバイト列になっているので、ちょうど玉ねぎの皮をむいていくイメージで、左端からオフセット、右端からデータを取り出していきます。
データ更新
データ更新は少し厄介です。できれば、更新するデータ以外のデータに関してはファイル上の位置を動かしたくないですが、更新によって新しいデータ長が長かったり、短かったりする場合があるからです。
様々な方法が考えられますが、更新データを保持するページを再構築するように実装します。
例えば、データが5個入ったページに対して、1つのデータを更新するとします。他の4つのデータと新しいデータをページ上に再配置・再構築します。
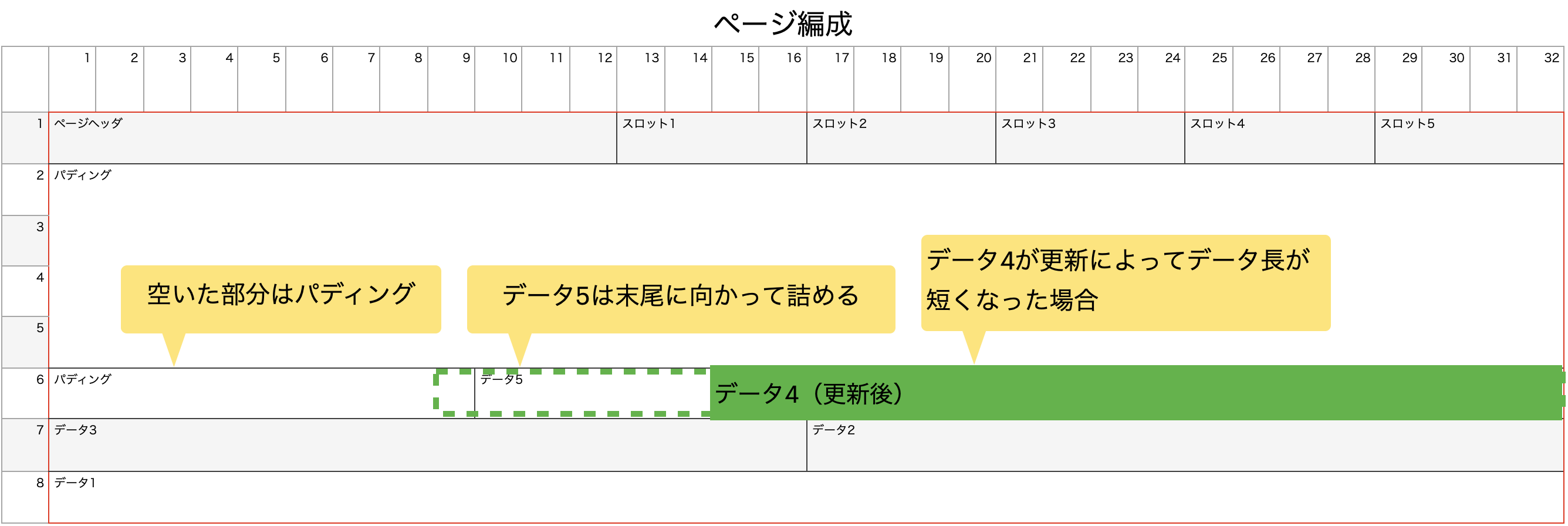
データ削除
データ削除の場合も更新と同じで、ページ内でデータを再配置・再構築します。
バッファ・キャッシュ
ディスクへの読み書きにはとても時間がかかります。そのため、SQLクエリを発行するごとに、ディスクへアクセスしているととても効率が悪いです。そこで、ディスクの手前にバッファ・キャッシュと呼ばれる仕組みを導入します。この仕組みについてとても良い説明があります。『データベースバッファキャッシュは、同じブロックの読み出しを効率化するための「キャッシュ」としての役割と、メモリとディスクの処理速度の差を補い、書き込みを効率化するための「バッファ」としての役割を持っています。』(Oracleアーキテクチャ入門より)
(以降、簡単にバッファと呼びます。)
ファイル編成に比べると、バッファについて意識されている方は多いのではないでしょうか。例えば、データベースの性能テストのため、トランザクションをたくさん発行し、テーブル読み書きを大量に実行する場合に、毎回バッファをクリアすることを忘れないようにしよう、など。
実際のところ、バッファの読み込みと、ディスクからのデータ読み込みでは、山手線で一駅移動するのと、地球から月へ行くぐらい差があります。
しかし、記憶装置にとって、データ容量が大きいことと読み書き速度が早いことはトレードオフになるので、全てのデータをバッファに置いておくことはできず、バッファ⇆ディスクへのデータのやり取りが必ず発生します。そこで問題になるのが、いかにバッファ⇆ディスクのやり取りを減らせるか、ということになります。
今回の実装では、ページ単位でバッファに読み込みます。バッファサイズを10ページ分とすれば、10ページまで同時にバッファ上に読み込むことができます。バッファ上に無いデータを取得するときは、バッファ上の一番古いページをバッファから破棄し、指定のページをバッファ上にロードします。
バッファ上にデータが無いことをキャッシュミスと呼びます。
バッファ上からどのページを破棄するかという戦略はいくつかあります。いかにキャッシュミスがないようにバッファ上にページを構えておくか、ということになります。
バッファ上の各ページごとに参照される度にその時間を保持しておき、キャッシュミスが発生した場合、参照された時間が一番古い(最近参照されていない)ページをバッファから追い出す戦略を、LRU(Least Recently Used)と呼びます。参照時刻が一番古いページは、将来的にも参照される可能性が低いだろうということです。
それでは、クライアント⇆バッファ⇆ファイルのCRUDを説明しましょう。
データ挿入
データの挿入も必ずバッファを介して行います。クライアントからデータ書き込み要求があれば、そのデータを書き込む空き容量があるページをバッファ上に読み込み(すでに読み込んでいればそこに)、挿入データを書き込みます。そして、そのページをディスクへ書き込みます。一般的なRDBMSでは、バッファ上にデータを書き込んだ時点でクライアント側には書き込み成功を返します。そして、いくつかのデータ挿入をまとめてディスクに書き込みます。そうすることで、ディスクへの書き込み回数を減らすことができます。しかし、今回はDurabilityを向上させたいので、1データ挿入ごとにバッファ書き込み→ディスク書き込みまで完了した後に成功を返します。
データ取得
データ挿入は上の方で記載しましたが、ページとスロットを指定します。そのページがすでにバッファ上にあれば、そのページから指定のスロットのデータを返します。キャッシュミスであれば、ディスクから指定のページをバッファ上に読み込み、その中から指定のスロットのデータを返します。
データ更新
データ更新はそのページをバッファにロードし、データを更新してディスクへ書き込みます。
データ削除
データ削除は、そのページをバッファにロードし、データを削除して、ディスクへ書き込みます。
あとがき
バッファやディスク読み書きはRDBMSの性能に直結する部分です。できるだけディスクへの読み書き回数を減らせるか、というところは深いですね。いかにキャッシュミスを減らせるか、いかにまとめて読み書きできるか、といったところがポイントでした。
次回、障害発生時のリカバリです。