まえがき
今回はRDBMSに障害が発生して、正常に処理が完了しなかった場合のリカバリについて実装していきます。これを実装することにより、Atomicity,Consistency,_Durability_向上へつながります。
ここで、_Consistency_について振り返ります。
トランザクションの実行によって、DBが想定通りの状態へと遷移することを保証すること、これが_Consistency_です。
しかし、様々な理由で、DBは想定通りの状態へと遷移できないことがあります。そういう事象を引き起こすものが 障害 です。そして、障害が発生したとしても、やはり想定通りの状態へ遷移させることを リカバリ と呼びます。(マリオカートでコースを外れた時に、コース上にマシンを連れ戻してくれる「ジュゲム」と同じ役割。)
障害の分類
まず、RDBMSで発生しうる障害の分類をまえとめておきます。「リレーショナルデータベース入門」より引用。
トランザクション障害
トランザクションが、誤った入力を読み込んだり、所望のデータが見つからなかったり、計算の途中でオーバフローしたり、必要な資源が見つからなかったりして、異常終了するような場合である。
システム障害
DBMSやOSの障害でシステムが暴走したりフリーズしたり、あるいはハードウェアの誤動作や電源断などが原因してシステムが止まり、揮発性の主記憶上のデータが霧散して、システムを再スタートしないといけない状況に陥る場合を言う。この場合、ディスクなどの不揮発性メディアに格納されているデータは残っている。
メディア障害
ディスクなどの2次記憶装置の障害をいう。
障害発生時の対処方法
次に、障害が発生した時の対象方法である、UNDO・REDOを説明します。ここではある状態1からトランザクションを実行して、状態2へ遷移する途中で障害が発生したとします。もし、リカバリせずに障害を放置した場合、状態1でも状態2でもない異常な状態になってしまいます。
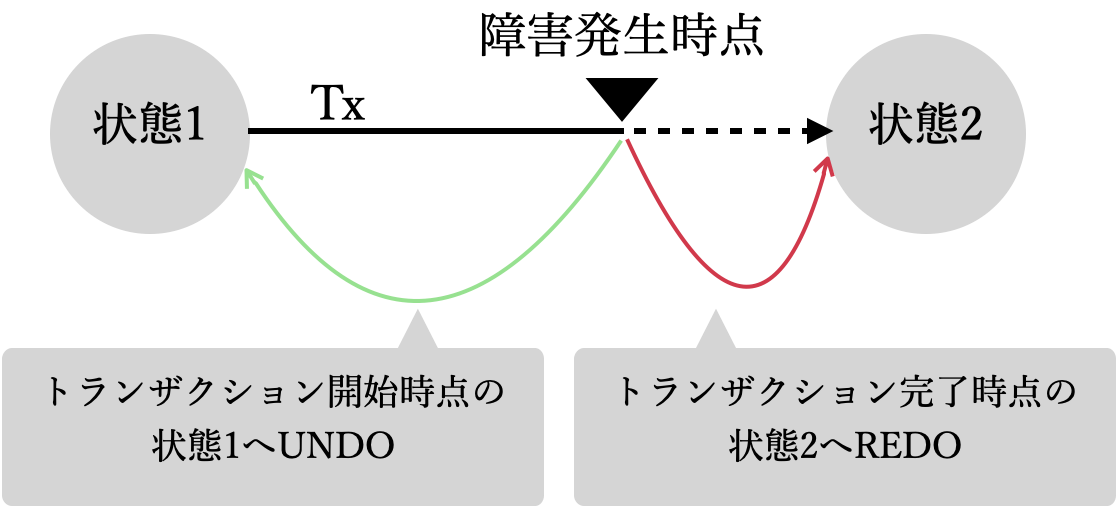
UNDO
UNDOは、状態1に戻す操作です。トランザクションの処理の途中で障害が発生してしまったので、そのトランザクションが起こした作用を無かったことにするため、状態1へ戻します。クライアントに対しては、もう一度トランザクションを実行してね、ということになります。
実装方法としては、どのレコードを何の値から何の値へ書き換えたのか、という情報を逐次UNDOログに保存します。もし障害が発生した場合は、UNDOログを使ってデータを元の値に書き戻します。
REDO
REDOは、状態2に進める操作です。トランザクションの「コミット時点」後、状態2へ遷移が完了する前に障害が発生した場合、頑張って状態2へ遷移させます。この状況が発生する主なケースとしては、トランザクションをコミットし、クライアントに対して処理完了を通知したが、2次記憶装置へのデータ書き込みが完了する前に障害が発生したケースです。
実装方法としては、どのレコードをどの値とするか、といった情報をREDOログに書き込みます。障害発生時はREDOログを元に、あるべき値へレコードを書き換えます。
コミット時点
UNDOすべきか、REDOすべきかの分岐点はなにかというと、障害発生が「コミット時点」より前か、後かということです。「コミット時点」とは何か下図で説明します。
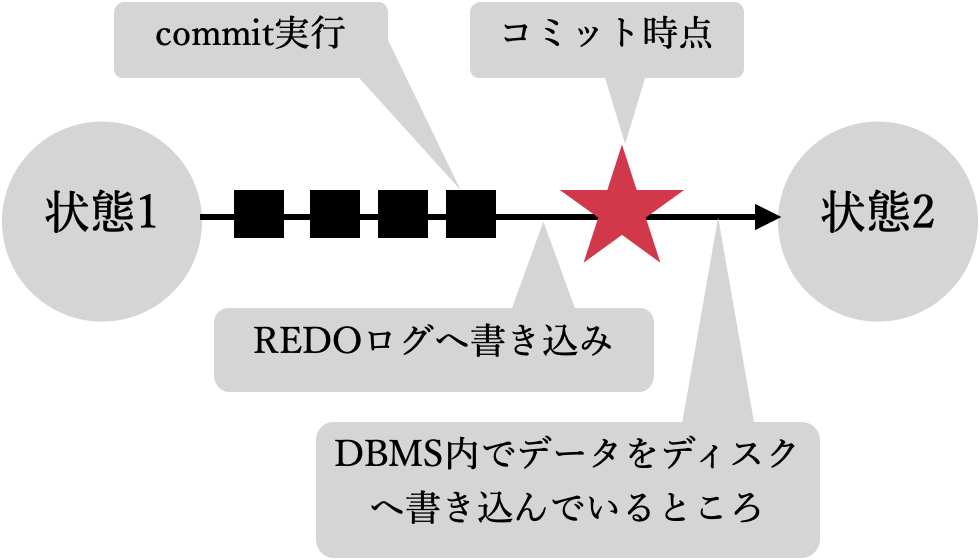
状態1からSQLを実行していき状態2へ遷移するというトランザクションを考えます。線上の■が1つのSQLの実行。4つめの■がcommitクエリ。そして、その後に現れる★が「コミット時点」です。すなわち、commitのSQLを実行してから、実際にDBが状態2へ遷移する間に「コミット時点」が現れます。一般的にコミット時点というものが何かというと、クライアントに対して、commitクエリが成功したことをレスポンスした時点になります。具体的には、commitが実行されると、DBMSはまずREDOログにデータを書き込みます。これで状態2へREDOするための準備ができます。そして、クライアントに対してコミット成功を返します。ここが「コミット時点」です。クライアントから見ると、この時点でコミット処理は完了したように見えるので、以降トランザクションをUNDOすることは許されません。しかし、この時点ではまだ2次記憶装置にはデータは書き込まれていないので、状態2へは遷移していません。バッファのデータがディスクへフラッシュされると状態2へ遷移します。
障害分類ごとの対処方法
それでは、前述のような障害が発生した時、DBはどういう状態になるべきか、どう対処するか考えていきます。
-
トランザクション障害発生時
そのトランザクションをUNDOする。 -
システム障害
システム障害発生時、コミットされていないトランザクションはUNDOする。すでにコミット時点を超えたトランザクションはREDOする。 -
メディア障害
DBデータの入っている永続記憶メディアが読み取り不可などの障害が発生した場合、まずメディアのバックアップ時点へ復元、そして、障害発生時までにコミットされたトランザクションを全てREDOする。
実装方式
UNDO,REDO方式
一般的なRDBMSはUNDO,REDO方式で実装されているでしょう。トランザクション中のSQLの結果は随時共有データ領域に書き込まれていく方式を取ると、トランザクションがアボートした場合に共有データ領域を元の状態へ綺麗にしてあげなければなりません。そのため、障害発生時はコミット完了していないトランザクションに対してUNDOします。
コミット時、データはバッファ上に残したままREDOログだけ保存しておき、2次記憶装置への書き込みは遅延させる方式を取ると、障害発生時は、データが永続化されていなかったトランザクションに対してREDOします。
No-UNDO,REDO方式
今回実装するのはNo-UNDO,REDO方式です。なぜUNDOが必要ないかというと、トランザクションをコミットするまで共有データ領域にデータを書き込まないからです。コミット前に先行して共有データ領域へデータを書き込むと、トランザクションがアボートした場合にディスクに書き込んだ内容を元の状態に綺麗にするためUNDOする必要がありますが、コミットが発行されるまでディスクに書き込まないことでUNDOするというシチュエーションが無くなります。しかしその分、コミット時にまとめて処理をすることになるので、処理が重くなります。
%% RedoLogを順に読み込み、REDOするための操作のリストを作成する
%% do_recoverにてREDOを実行する
recover() ->
recover(start, []).
recover(Cont, RedoList) ->
case log_util:redo_log_chunk(Cont) of
{Cont2, RedoLog} ->
recover(Cont2, RedoLog++RedoList);
eof ->
RedoL = seek_checkpoint(RedoList, []),
do_recover(build_redo_list(RedoL)),
log_util:redo_log_truncate()
end.
%% REDOするための操作のリストを作成する
%% RedoListはすでに読み込んだREDOログのリスト、RedoLogはこれから読み込み解釈するREDOログ
%% checkpointを通過した時は、RedoListを破棄して、RedoListを作成し直すなど。
build_redo_list(RedoList) ->
%% TODO: chunkした結果を解釈してからリカバリを実施するよう修正。特にトランザクションの途中までDISKへのデータ挿入が実行できている場合の考慮など
lists:map(fun(#redo_log{action=Action, table_name=TableName, oid=Oid, val=Val}) ->
{Action, TableName, Oid, Val}
end, RedoList).
%% REDO操作を行う。基本的にはsimple_db_serverにクエリを投げるだけの想定
do_recover([]) ->
ok;
do_recover([{ins, TableName, Oid, Val} | T]) ->
io:format("[REDO][ins]~p,~p,~p~n", [TableName, Oid, Val]),
simple_db_server:insert_data(simple_db_server, TableName, Oid, Val),
do_recover(T);
do_recover([{del, TableName, Oid, Val} | T]) ->
io:format("[REDO][del]~p,~p,~p~n", [TableName, Oid, Val]),
simple_db_server:delete_data(simple_db_server, TableName, Oid),
do_recover(T).
%% チェックポイントをどこで取るか、どのように実装するか
%% -> コミットが正常に完了した時点で、redo_logにcheckpointを書き込む
%% チェックポイント以降のREDOログだけ再実行すれば良いので、checkpointを探す
seek_checkpoint([], Ret) ->
lists:reverse(Ret);
seek_checkpoint([#redo_log{action=checkpoint} | RedoList], _Ret) ->
seek_checkpoint(RedoList, []);
seek_checkpoint([H | RedoList], Ret) ->
seek_checkpoint(RedoList, [H | Ret]).
リカバリが必要となった場合に、呼び出される処理を説明します。REDOログはErlangのdisk_logモジュールでredo_logという名前で実装します。
リカバリをする際は、redo_logを初めから読み込んでいき、一番最後のcheckpoint以降のREDOログのリストを作成します。そして、do_recoverの中で、REDOログのリストの要素を一つずつsimple_db_serverのinsert_data,delete_dataへリクエストを投げてREDOしていきます。
ここで1つポイントになることは、simple_db_serverのinsert_data,delete_dataの処理は冪等でなければならないということです。冪等とは、同じ処理を繰り返し実行しても同じ結果が保証されることです。なぜなら、リカバリ処理の途中で、再度障害が発生し、リカバリする可能性があるためです。特に、リカバリの処理の際はディスク上のアドレスを指定して書き込める必要があります。別々のアドレスに書き込んでしまうと、レコードが2つ生成されてしまうからです。
あとがき
さて、RDBMS実装も良い感じになってきました。次回は、トランザクションを多重に並行実行して、スループットを上げる方法について実装していきます。