まえがき
この記事を3行で
- 標準のPythonだけでベクトル検索を実装する方法を紹介します
- 速度、メモリ的に、どのくらいのデータ件数が限界かを調べます
- 埋め込みモデルの利用例(RAG、YES/NOの判別、画像クラス分類)も紹介します
使う環境
- Python 3.12
- AWS Bedrock
※今回はBedrockのtitanを使いますが、OpenAIのEmbeddingも使い方は同じです。
この記事が想定する読者
- AWS(Lambda)がどういうものかを知っている
- Pythonのプログラミングが可能で、LLMに興味がある
- RAGをしようとしているが、ベクトルデータベースの値段が気になる
ベクトル検索に、データベースはマストじゃない
RAGのためにベクトル検索を導入するなら、ベクトルデータベースは必ず導入したほうがいいのでしょうか。
昔、高専生だった時に日雇いのアルバイトをしていました。
組み立て前の段ボールの束を渡されて、「グルーガンで底を組むように」と指示されます。缶飲料の入った段ボールがベルトコンベアで流れてくるので、ひたすらパレットの上に積み上げます。業務知識は朝の数分で伝えられる量だけ、誰にでもできる仕事です。
それをRAGやAIで自動化するとしたら、データベースを使うのは大げさな気がします。
OpenAIの埋め込み(Embeddings)のドキュメントには、こう説明があります。
How can I retrieve K nearest embedding vectors quickly?
(埋め込みベクトルのK近傍はどう取ればいいですか?)
For searching over many vectors quickly, we recommend using a vector database.
(多くのベクトルデータを素早く取るには、ベクトルデータベースの利用をお勧めします。)
OpenAIのドキュメントによれば、ちょっとのベクトルデータを取るか、急がないのなら、ベクトルデータベースは不要だと読み取れます。ですが、

それは数百件?
数千件?
具体的にどのくらいの件数ならベクトルデータベースを導入すべきだろう、と思ったので、計測して記事をまとめることにしました。
先に結論
記事が長いので、先に結論を書きます。
OSSやデータベースを使わずに、pythonの標準ライブラリだけでベクトル検索を実装して、メモリ設定を最小(128MB)にしたLambdaの上で動かしました。
下のグラフは、対象のデータ件数が増えたときに、Lambdaの実行時間とメモリ使用量がどう増えていくのかをまとめたものです。
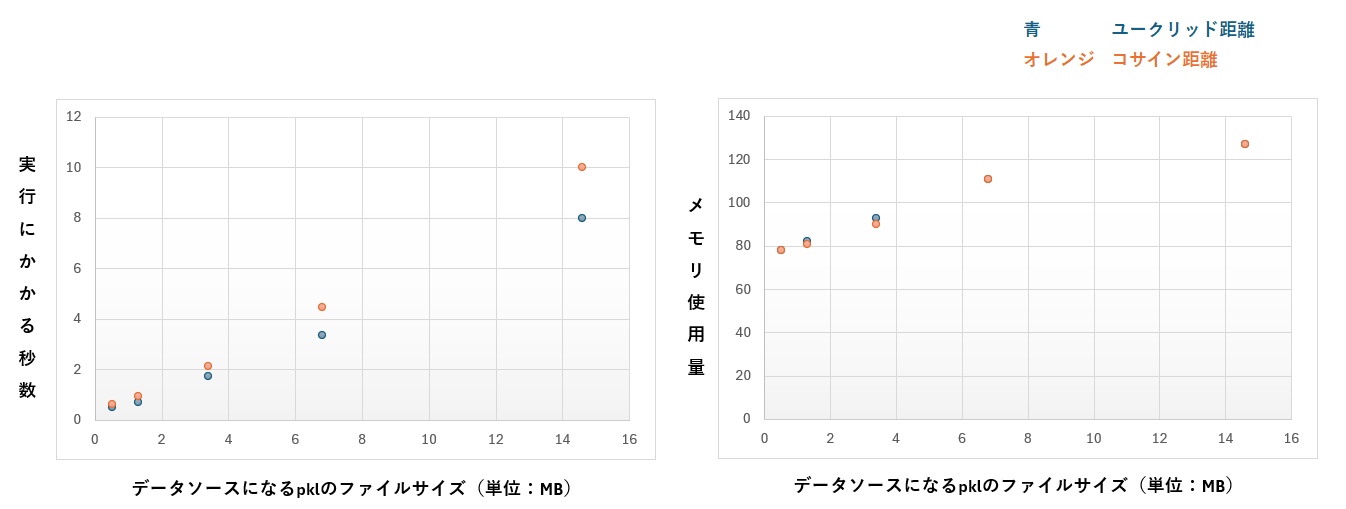
ベクトル検索をする対象のデータは、30件、100件、250件、500件、1071件としました。
【結果から読み取れたこと】
- データソースが100件増えるごとに、実行時間はおよそ1秒長くなりました
- 500件以下であれば、メモリ設定が128MBでも不足しませんでした
【結論】
対象のデータが100件程度であれば、ベクトルデータベースは不要だと考えます。
遅い生成AIと組み合わせるなら、500件程度なら許容できそうです。
500件を超えると、高速化や設定の検討が必要になります。
高速化のためのライブラリか、ベクトルデータベースを導入したほうが良さそうです。
【それから】
また、記事の後半で、ベクトル検索の利用例を紹介しています。
- RAG
- テキストクラス分類:自由入力された文章を渡して、YESかNOかを判定する
- 画像クラス分類:画像を渡して、猫か犬かを判定する
前提になる情報の説明
ベクトル検索の仕組み
このセクションでは、
- ベクトル検索とは何か
- LLMの「埋め込みモデル」とは何か
- 利用するk近傍(KNN)とは何か
を簡単に説明します。知っている方は読み飛ばしてください。
このセクションは以下の記事を元にしています。
1, ベクトル検索とはなんぞや
埋め込みモデルを使ったベクトル検索は、検索のための仕組みです。
文章データがあって、そこから似ているデータを検索します。

2. 似てるって何?
言葉同士が似ているのかは、どうやって判断すればいいでしょうか。
帽子屋の「カラスと書き物机はどうして似ている?」のように、2つの言葉が似ているかを調べる方法には色々な切り口があります。共通点は文字数かもしれないですし、アナグラムかもしれませんし、特定の言語での響きかもしれません。いろいろな方法が考えられます。
LLMの埋め込みモデルは、言葉の意味で判断します。
AIが物事を理解するとき、ジャンルや特徴の連想ゲームで理解しています。たとえば夏のかき氷なら、「食べ物」→「つめたい」→「夏」→「甘い」のように連想して頭の中を進んでいきます。夏のデータは夏の場所に集まって、冬のデータは冬の場所に集まります。

LLMの埋め込みモデルから取るのは、AIの頭の中の座標です。
座標はただの数字の羅列ですが、データ同士が近い場所にあるかどうかを見れば、特徴と意味が似ているか、何か関係性があることが分かります。
3. 埋め込みモデルを使った検索のシーケンス
先ほどの図があります。
このシーケンス図に、埋め込みモデルの操作を書き加えます。
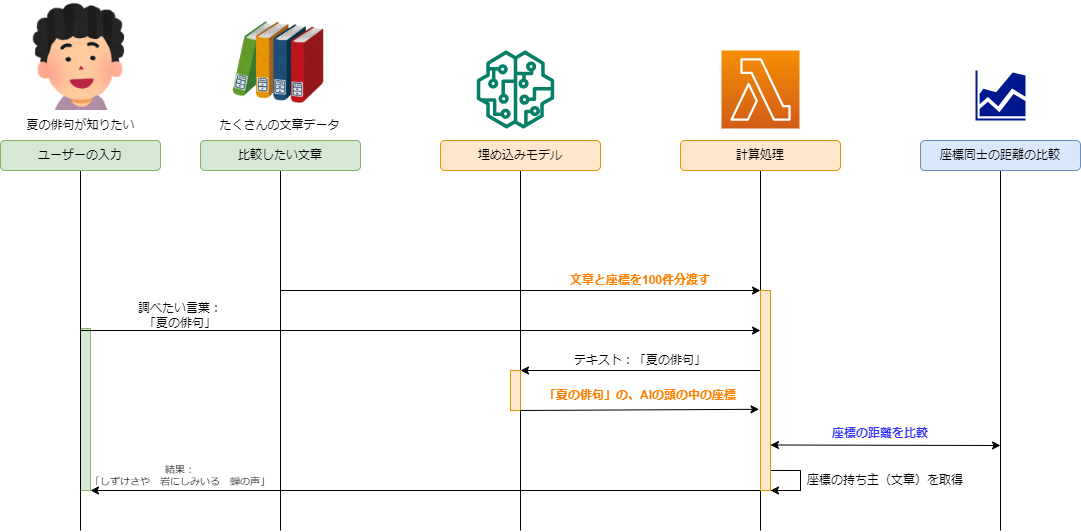
比較したい文章の座標と、調べたい言葉の座標を比べて、最も座標の位置が近い文章を返します。比較したい文章の座標をあらかじめ持っておく必要があるので、前準備も必要になります。
それを足すと下のシーケンスになります。
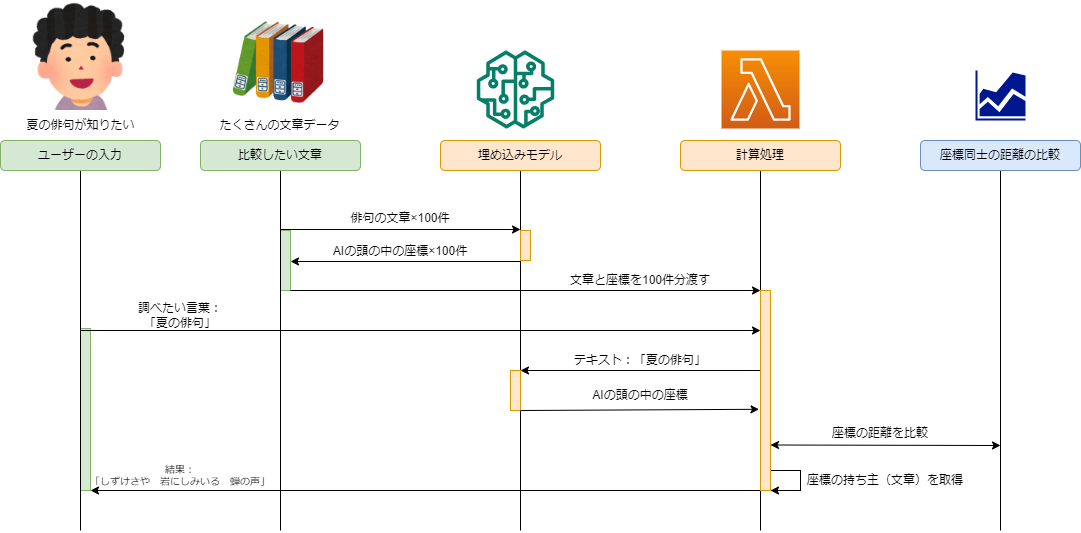
4.似ているものを探す
K件の距離が近いデータを探す操作を(K近傍法)と呼びます。英語で書くとk-nearest neighborなので、頭文字をとってknnと呼びます。「近傍」を柔らかく言えば「ご近所さん」だとか「おとなりさん」です。
下の画像で言えば、緑の●を基準にして、近くにある赤の▲が近傍になります。
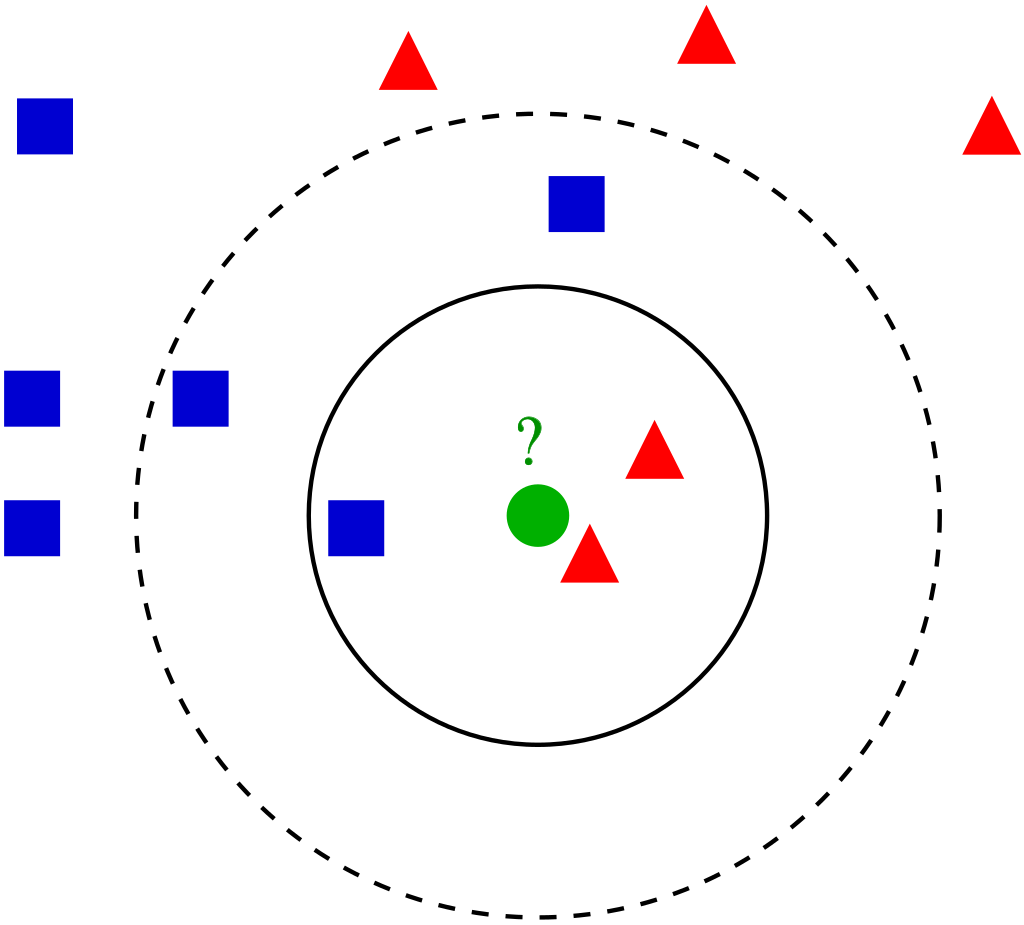
近傍を考えるとき、距離の選び方が話題に出てきます。
たとえば大阪から東京までの距離にも「直線距離」と「移動距離」があります。同じような話で、目的によって使う距離が変わります。
実装の紹介
今回のソースコード、元データ、pklデータはこちらに置いています。
フォルダ構成が分からない、テストデータを作るのが面倒、と思ったらこちらを利用してください。
実装方法
pythonの標準ライブラリだけで実装を進めていきます。
1. 距離の取り方
以下のように、データの近傍(おとなりさん)を取るソースを書きました。
import文はありません。
def distance_pow(vec: list[float]) -> float:
"""
距離の二乗を取得する
vec: 取得する対象のベクトル
"""
return sum([v * v for v in vec])
def cosign_distance(vec1: list[float], vec2: list[float]):
"""
コサイン距離を取得する(似ているほど-1に近い、似ていないほど大きくなる)
"""
# L2を取る(0.5乗するとルートが取れる)
l2_length = (distance_pow(vec1) ** 0.5) * (distance_pow(vec2) ** 0.5)
if l2_length == 0.0:
# L2が異常値になるなら0を返す
return 0.0
# 内積を取る
dot_product = sum([v1 * v2 for v1, v2 in zip(vec1, vec2)])
# コサイン類似度を計算する(変化の方向をユークリッド距離に合わせたいので、1.0から引いてコサイン距離とする)
return 1.0 - (dot_product / l2_length)
def euclid_distance(vec1: list[float], vec2: list[float]) -> float:
"""
ユークリッド距離の二乗を取得する(似ているほど0に近い、似ていないほど大きくなる)
"""
# zipで複数の配列を1つの配列にまとめる
return distance_pow([v1 - v2 for v1, v2 in zip(vec1, vec2)])
def calc_distance_list(
base_point: list[float], reference_points: list[list], distance_function
):
"""
基準点(base_point)を元に、データ点(reference_points)それぞれまでの距離を取得する
"""
return [
# 基準点から対象の点までの距離を求めて、距離リストに追加する
distance_function(blue_point, base_point)
for blue_point in reference_points
]
def nearest(
base_point: list[float],
reference_points: list[list],
distance_function=cosign_distance,
topk: int = 1,
):
"""
基準点から見て、最も距離の近いデータ点を取得する
"""
knn = sorted(
# 距離のリストに、インデックスをつけてソートする
enumerate(calc_distance_list(base_point, reference_points, distance_function)),
# enumerateで、インデックスと値の配列になるので、x[1]で値を取得する
key=lambda x: x[1],
# 距離の昇順でソート、距離が小さいものを先頭に置く
reverse=False,
)
return [{"index": k[0], "score": k[1]} for k in knn[:topk]]
コサイン類似度に比べて、ユークリッド距離のほうが高速に計算できます。
ちょっと精度が欲しいところは、コサイン類似度を使うほうが良いです。
関数を使うときは、以下のように書きます。
from distance import nearest, euclid_distance, cosign_distance
# 入力テキストを埋め込みLLMで座標に変換する
prompt_vector = ...
# 検索対象の座標データの一覧を取得する
data_list = ...
# ユークリッド距離から、最も似ているデータをとる場合
knn_index = nearest(prompt_vector, data_list, euclid_distance, 1)
print(vecdata[index_list[knn_index[0]["index"]]]["data"])
# コサイン距離から、最も似ているデータをとる場合
knn_index = nearest(prompt_vector, data_list, cosign_distance, 1)
print(vecdata[index_list[knn_index[0]["index"]]]["data"])
2. テキストを埋め込みLLMで座標に変換する
テキストを座標に変換する処理は以下の通りです。
import boto3
import json
# バージニアリージョンのLLMを使う
runtime = boto3.client("bedrock-runtime", region_name="us-east-1")
def text_to_vector(prompt: str):
"""テキストを座標に変換する"""
res = runtime.invoke_model(
body=json.dumps({"inputText": prompt}).encode("utf-8"),
contentType="application/json",
accept="application/json",
# モデルは埋め込みTitanのV1を使う。次元数は1536、言語は25言語に対応
modelId="amazon.titan-embed-text-v1",
)
return json.loads(res["body"].read())["embedding"]
Hello Worldをpromptに入れて、text_to_vector関数を実行すると、巨大なfloatの配列が返ってきます。

この数字の集まりが、1つのAIの頭の中の座標になります。
3. 前準備:データを辞書化しておく
前準備のために、データを変換するソースは以下の通りです。
pickleは標準のpythonで使えるファイル形式です。メモリ上にあるデータをそのままファイルにダンプします。jsonのような他の読み込みに比べて、高速にデータを復元することができます。
import pickle
from text2vector import text_to_vector
def convert_text_to_pkl(
resource_file_name: str, export_file_name: str, chunk_size: int = 300
):
"""
テキストデータを埋め込みLLMで座標化、pickleファイルに格納する
resource_file_name: 元データにするテキストファイル
export_file_name: pickleファイルのファイル名、拡張子はpkl
chunk_size: テキストデータを分割する文字数
"""
# テキストデータを読み込む
with open(resource_file_name, encoding="utf8") as fp:
data = [line.strip() for line in fp.readlines()]
# チャンクに分割して、テキストを格納する
vecdata = []
for index, line in enumerate(data):
vecdata.append(
{
"index": index,
"data": line,
"chunk": [
line[l : l + chunk_size] for l in range(0, len(line), chunk_size)
],
"vector": [],
}
)
# チャンクをベクトル化する
for content in vecdata:
for chunk in content["chunk"]:
content["vector"].append(text_to_vector(chunk))
# データをpickleに保存する
with open(export_file_name, "wb") as fp:
pickle.dump(vecdata, fp)
convert_text_to_pkl("data.txt", "vector.pkl")
4: 実行する
ここまで、辞書データを作って、距離の比較用関数を作って、埋め込みモデルを使ったテキストから座標への変換関数を作りました。
それを使って実際に検索します。
import pickle
from distance import nearest, euclid_distance, cosign_distance # noqa
from text2vector import text_to_vector # noqa
def main(prompt: str, top_k: int = 3):
# あらかじめ取得したベクトルの辞書を読み込む
# ※辞書はチャンクごとにベクトルデータがふられているので、入れ子になっている
with open("vector.pkl", "rb") as fp:
vecdata = pickle.load(fp)
# 入れ子になった辞書を、フラットな検索用の配列に移し替える
data_list = []
index_list = []
for content in vecdata:
# 入れ子の中に入る
for vector in content["vector"]:
# ベクトルデータをフラットな配列にまとめる
data_list.append(vector)
# ベクトルデータに対応するインデックスを記録する
index_list.append(content["index"])
# 受け取った質問文をベクトル化する
prompt_vector = text_to_vector(prompt)
# 最も似ているベクトルの上位k件を検出する
knn_index = nearest(prompt_vector, data_list, euclid_distance, top_k)
for k in range(top_k):
print(vecdata[index_list[knn_index[k]["index"]]]["data"])
main("<質問文をここに入れる>", top_k=3)
5: 検証する
検証のために、ゼノギアスの設定をwikipediaから取りました。
件数は30件、文字数は6,591文字、ファイルサイズは20KBです。
データはこちらに置いています。
データをpklファイルにまとめておいて、似たテキストを検索、上位3件を取ります。
まず、距離関数が変わることで結果が変わるのかを確認します。
検索:「伊達杏子がモデルになったアイドルは誰ですか?」
| 類似度 | ユークリッド距離 | コサイン距離 |
|---|---|---|
| 1位 | DK1200 | DK1200 |
| 2位 | 機動端末兵器群 | 起動端末兵器群 |
| 3位 | アーネンエルベ | アーネンエルベ |
距離関数を変えても、どちらも全く同じ結果を返しました。
DK1200はバーチャルアイドルの伊達杏子がモデルになったアイドルですから、期待通りの正解です。
今度は逆の質問をしてみます
検索:「DK1200は誰がモデルになりましたか?」
| 類似度 | ユークリッド距離 | コサイン距離 |
|---|---|---|
| 1位 | DK1200 | DK1200 |
| 2位 | 機動端末兵器群 | オメガ1 |
| 3位 | 刻印 | 生体兵器デウス |
1位は同じ結果ですが、2位以降が異なる結果になりました。
OpenAIの埋め込み(Embeddings)のドキュメントを見ると、こう書いてあります
Which distance function should I use?
(どの距離を使って実装すればいい?)
We recommend cosine similarity. The choice of distance function typically doesn’t matter much.(コサイン類似度をお勧めします。ただ、通常、どの関数を使うのかはあまり重要ではありません)
Cosine similarity and Euclidean distance will result in the identical rankings(コサイン類似度とユークリッド距離は同じ結果を返します)
どちらの関数を使っても良さそうですが、未知語や固有名詞が入るなら、OpenAIがお勧めするコサイン類似度のほうが信頼できそうです。
6: 時間と消費メモリを計ってみる
SAMで作成したlambda環境の上で実行時間を計測します。
使うデータは先ほどと同じ、ゼノギアスの設定データです。
requirements.txtは空ファイルを指定します。Lambdaレイヤーも指定しません。Python 3.12は標準でboto3が1.28.72になっているため、標準のままBedrockが利用できます。
【Lambdaの設定】
| 項目 | 設定値 |
|---|---|
| ランタイム | Python 3.12 |
| タイムアウト | 25秒 |
| メモリサイズ | 128 MB |
| Lambdaレイヤー | - |
| OSSライブラリ | - |
メモリは最も小さなサイズ、タイムアウトはAPIGatewayからの実行を想定して29秒以内にしています。
Lambdaのテスト画面から実行して、以下の3つの条件で実行時間を計測します。
- 何も処理が入っていない状態のLambda
- ユークリッド距離でベクトル検索
- コサイン距離でベクトル検索
デプロイ直後の初回実行はコールドスタートがあるため、必ず時間がかかります。
ですので、正しく測るために続けて3回実行します。2回目と3回目の平均が実行時間です。
結果は以下のようになりました。
【30件のデータに対するベクトル検索】
| 距離関数 | 試行 | Lambdaの実行時間 | 消費メモリ |
|---|---|---|---|
| (初期状態) | - | 0.003秒 | 72MB |
| ユークリッド距離 | 1回目 | 1.192秒 | 77MB |
| ユークリッド距離 | 2回目 | 0.530秒 | 78MB |
| ユークリッド距離 | 3回目 | 0.482秒 | 78MB |
| コサイン距離 | 1回目 | 1.228秒 | 77MB |
| コサイン距離 | 2回目 | 0.627秒 | 78MB |
| コサイン距離 | 3回目 | 0.605秒 | 78MB |
メモリへの負荷はほとんどなく、実行時間も0.5秒前後です。
少しコサイン距離のほうが時間がかかっていますが、体感できるほどの差はありません。
【1071行のデータに対するベクトル検索】
新約聖書のマタイによる福音書の口語訳をデータソースにします。
1071行、ファイルサイズは172KB、pklにしたときのファイルサイズは14.6MBです。
データはこちらに置きました。
「実をつけない木」について尋ねると、「3:10 斧がすでに木の根もとに置かれている。だから、良い実を結ばない木はことごとく切られて、火の中に投げ込まれるのだ。」と、第3章10節が返ってきました。これでパルプ・フィクションごっこができますね!!
| 距離関数 | 試行 | Lambdaの実行時間 | 消費メモリ |
|---|---|---|---|
| ユークリッド距離 | 1回目 | 9.821秒 | 124MB |
| ユークリッド距離 | 2回目 | 8.537秒 | 127MB |
| ユークリッド距離 | 3回目 | 7.424秒 | 127MB |
| コサイン距離 | 1回目 | 11.729秒 | 124MB |
| コサイン距離 | 2回目 | 10.501秒 | 127MB |
| コサイン距離 | 3回目 | 9.547秒 | 127MB |
メモリはほとんど使いきっていて、実行時間も8~10秒かかっています。
コサイン距離とユークリッド距離の実行時間の差は2秒ほどになりました。
【100行のデータに対するベクトル検索】
間のデータを取っていきます。
マタイによる福音書から100件だけ切り出して、再実施しました。
100行、pklにしたときのファイルサイズは1.3MBです。
| 距離関数 | 試行 | Lambdaの実行時間 | 消費メモリ |
|---|---|---|---|
| ユークリッド距離 | 1回目 | 1.611秒 | 81MB |
| ユークリッド距離 | 2回目 | 0.713秒 | 82MB |
| ユークリッド距離 | 3回目 | 0.688秒 | 82MB |
| コサイン距離 | 1回目 | 1.710秒 | 80MB |
| コサイン距離 | 2回目 | 0.964秒 | 81MB |
| コサイン距離 | 3回目 | 0.963秒 | 81MB |
【250件のデータに対するベクトル検索】
マタイによる福音書から250件だけ切り出して、再実施しました。
250行、pklにしたときのファイルサイズは3.4MBです。
| 距離関数 | 試行 | Lambdaの実行時間 | 消費メモリ |
|---|---|---|---|
| ユークリッド距離 | 1回目 | 2.878秒 | 92MB |
| ユークリッド距離 | 2回目 | 1.772秒 | 93MB |
| ユークリッド距離 | 3回目 | 1.722秒 | 93MB |
| コサイン距離 | 1回目 | 2.987秒 | 89MB |
| コサイン距離 | 2回目 | 2.195秒 | 90MB |
| コサイン距離 | 3回目 | 2.111秒 | 90MB |
【500件のデータに対するベクトル検索】
マタイによる福音書から500件だけ切り出して、再実施しました。
500行、pklにしたときのファイルサイズは6.8MBです。
| 距離関数 | 試行 | Lambdaの実行時間 | 消費メモリ |
|---|---|---|---|
| ユークリッド距離 | 1回目 | 4.976秒 | 110MB |
| ユークリッド距離 | 2回目 | 3.379秒 | 111MB |
| ユークリッド距離 | 3回目 | 3.352秒 | 111MB |
| コサイン距離 | 1回目 | 6.133秒 | 110MB |
| コサイン距離 | 2回目 | 4.525秒 | 111MB |
| コサイン距離 | 3回目 | 4.393秒 | 111MB |
【グラフにしてみる】
ここまでのデータをグラフにすると、以下のようになります。
データソースの大きさに正比例して、Lambdaの実行時間は長くなっています。
レコードが100件増えれば、ベクトル検索にかかる時間は1秒増えています。
メモリ使用量もほぼ正比例しているのですが、途中で上がり方が変わっています。
上限の128MBを使い切ると、GCが動いてメモリを確保していたのではないかと思います。
コサイン距離とユークリッド距離の時間の差は高々20%でした。
100件をこえない範囲なら、精度を優先して無視できる差だと考えます。
【ここまでの結論】
100件程度のレコードに対してベクトル検索をかけるなら、Lambdaの実行時間は1秒程度で済むため、ライブラリやデータベースを導入せずに実装して良さそうです。
500件あたりまでなら5秒で済みますし、メモリの窮屈さもありません。データの頻繁な更新がなく、ユーザーを待たせてもいい要件なら、ベクトルデータベースを導入しない形を検討して良さそうです。
そこを越えるとメモリと待ち時間の問題が顕著になります。
自前で高速化を図るのではなく、素直にベクトルデータベースを導入すべきだと考えます。
この検証で使ったYAMLファイルは以下の通りです。
AWSTemplateFormatVersion: "2010-09-09"
Transform: AWS::Serverless-2016-10-31
Description: no-lib-vector-search
Resources:
NoLibVectorSearchFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: vector_search/
Handler: app.lambda_handler
Runtime: python3.12
Timeout: 25
MemorySize: 128
Architectures:
- x86_64
Environment:
Variables:
BEDROCK_REGION: us-east-1
Policies:
- Statement:
- Sid: "BedrockInvokePolicy"
Effect: "Allow"
Action: "bedrock:InvokeModel"
Resource: "arn:aws:bedrock:*::foundation-model/amazon.titan-embed-text-v1"
他の使い方の紹介
ベクトル検索と、埋め込みモデルの使い道を紹介します。
埋め込みは通常の生成AIに比べるとかなり安価で、高速で、レスポンスまでの時間が安定しています。Titan Embeddingsの料金は0.0001ドル、それに対してClaudeは入力だけで80倍の料金(0.008ドル)がかかります。出力は別料金で、必要なトークンも埋め込みモデルよりも長くなります。
Claudeの1%以下の料金で利用できるのは嬉しい点です。
RAG
ベクトル検索の使い道として、最近話題になるのがRAGです。
たとえばゼノギアスの設定を返すベクトル検索をAgents for Amazon Bedrockに入れると、以下のようにチャット形式で質問に答えてくれます。
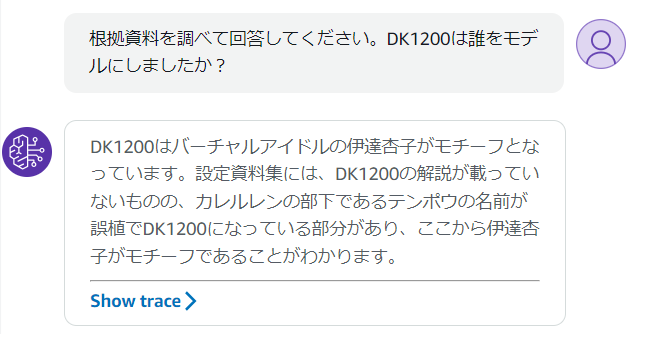
実装は以下の通りです。Pythonの3.11で実行しています。
ソースの変更は、ベクトル検索のソースに日本語のコメントを足したくらいです。
クラス分類(YES/NOを分類する)
クラス分類にも利用することができます。
埋め込みモデルを使って、YES/NOの分類をやってみます。
ソースコードはゼノギアスの検索に使ったソースをそのまま使います。
pklに入れるデータは以下の2件です。
| 番号 | データ |
|---|---|
| 1件目 | YES。はい、そうです。ええ。合っています。正しいです。お願いします。 |
| 2件目 | NO。いいえ。違います。そうではありません。間違っています。 |
雑な分類用データですが、このまま実行してみます。
引数に与えた文字列が、YESとNOのどちらに似ているのかを分類させます。
D:\2024_records\no-lib-vector-search\vector_search>python app.py はい、そうです
YES。はい、そうです。ええ。合っています。正しいです。お願いします。
処理時間: 1.159823秒
「はい、そうです」はYESでした。これは当然な気がします。
(.venv) D:\2024_records\no-lib-vector-search\vector_search>python app.py その形で進めてください
YES。はい、そうです。ええ。合っています。正しいです。お願いします。
処理時間: 1.3375959秒
「その形で進めてください」もYESです。ニュアンスが近いのでYESになるようです。
(.venv) D:\2024_records\no-lib-vector-search\vector_search>python app.py ダメです、止めてください
NO。いいえ。違います。そうではありません。間違っています。
処理時間: 1.3021062秒
「ダメです、止めてください」はNOになりました。正解です。
(.venv) D:\2024_records\no-lib-vector-search\vector_search>python app.py "s'il te plaît"
YES。はい、そうです。ええ。合っています。正しいです。お願いします。
処理時間: 1.3309168秒
フランス語で「お願いします」を投げると、YESになりました。正解です。
言語が違っても正しく検索することができます。
思いつく限りの言葉を投げて、正誤を確認してみます。
| セリフ | 結果 | 正誤 |
|---|---|---|
| はい、そうです | YES | 〇 |
| その形で進めてください | YES | 〇 |
| ダメです、止めてください | NO | 〇 |
| はい | YES | 〇 |
| そうしてください | YES | 〇 |
| 違います | NO | 〇 |
| ストップ | NO | 〇 |
| そうじゃない | NO | 〇 |
| それはよくないです | NO | 〇 |
| s'il te plaît(仏語:お願いします) | YES | 〇 |
| c'est faux(仏語:間違っています) | NO | 〇 |
| Danke(独語:お願いします) | YES | 〇 |
| das ist falsch(独語:間違っています) | NO | 〇 |
また、以下のような言葉だと間違いました。
言い方があいまいになると、もう少しちゃんとした分類用データが必要になるようです。
| セリフ | 結果 | 正誤 |
|---|---|---|
| 正しいです | NO | × |
| ええ | NO | × |
| それでいきましょう | NO | × |
| その通りです | NO | × |
| 大丈夫です | NO | × |
| 素敵ですね | NO | × |
はい、いいえ、お願いします、くらいの簡単な判別なら、埋め込みモデルの分類でできそうです。
マルチモーダルで画像をクラス分類する
AWSのAmazon Titan Multimodal Embeddingsでは、画像とテキストを横断した埋め込みモデルを使うことができます。使い方はテキスト向けの埋め込みモデルとほぼ同じです。2024年1月21日の時点で、OpenAIの埋め込みモデルにはない機能です。 失礼しました、OpenAIではCLIPが相当します。Azureではマルチモーダル埋め込みが相当します。
写真に写っている生き物が、猫か犬かを判定します。
テキストをベクトルに変換する部分の実装だけが少し変わります。
テキストを埋め込みベクトルに変換するときは、以下のように実装します。
def text_to_multimodal_vector(prompt: str):
"""テキストをマルチモーダル向けにベクトル化する"""
res = runtime.invoke_model(
body=json.dumps(
{
"inputText": prompt,
"embeddingConfig": {"outputEmbeddingLength": 384},
}
).encode("utf-8"),
contentType="application/json",
accept="application/json",
modelId="amazon.titan-embed-image-v1",
)
return json.loads(res["body"].read())["embedding"]
画像を埋め込みベクトルに変換するときは、以下のように実装します。
def image_to_multimodal_vector(base64image: str):
"""画像をマルチモーダル向けにベクトル化する"""
res = runtime.invoke_model(
body=json.dumps(
{
"inputImage": base64image,
"embeddingConfig": {"outputEmbeddingLength": 384},
}
).encode("utf-8"),
contentType="application/json",
accept="application/json",
modelId="amazon.titan-embed-image-v1",
)
return json.loads(res["body"].read())["embedding"]
pklに入れるデータは、以下の2件のテキストです。
犬を英英辞書で調べた内容と、猫を英英辞書で調べた内容を登録しました。
| 番号 | データ |
|---|---|
| 1件目 | DOG. dog. a common animal with four legs, fur, and a tail. Dogs are kept as pets or trained to guard places, find drugs. |
| 2件目 | CAT. cat. a small animal with four legs that people often keep as a pet. |
実施してみます。画像を送信します。
パブリックドメインQから、犬と猫の画像を借りてきました。
https://publicdomainq.net


(.venv) D:\2024_records\no-lib-vector-search\vector_search>python app.py <猫の画像>
CAT. cat. a small animal with four legs that people often keep as a pet.
処理時間: 1.9242364秒
猫です。正しく判定できています。
(.venv) D:\2024_records\no-lib-vector-search\vector_search>python app.py <犬の画像>
DOG. dog. a common animal with four legs, fur, and a tail. Dogs are kept as pets or trained to guard places, find drugs.
処理時間: 1.4377737秒
犬です。正しく判定できています。
パブリックドメインQにある画像を集めて、色々な画像で判定してみます。
| 結果 | 正誤 | |
|---|---|---|
 |
DOG | 〇 |
 |
DOG | 〇 |
 |
CAT | 〇 |
 |
CAT | 〇 |
 |
CAT | - |
用意した画像に全て正答しました。
最後は「猫耳」でパブリックドメインQから取った画像です。正答なしのつもりでしたが、AIは猫だと判断したようです。
まとめ
埋め込みモデルは強力な機能です。
動作が早く、料金が安く、色々なことに利用できます。
本当にベクトルデータベースを挟む必要があるのか、自分がやろうとしていることを埋め込みモデルで解決できないか、ベクトルデータベースを使うのならもっと有効活用できないか、ぜひ検討してみてください。