前提と概要
サブウェイ風の店員さんをAIで作ってみました。
その時の要点、実装を簡単にした方法を記事にまとめました。
Q:なんでサブウェイ?
→ A: 難しいから
ChaliceのAgents for Amazon Bedrock向けの拡張プラグインを作っています。
サンプルプロジェクトを入れる必要があったのですが、どうせなら目一杯難しいサンプルを放り込んでやろうと思いました。
この記事の要点を3行で
- チャットのエージェントはできるだけ細分化したほうがいい
- バリデータのzodを使って、例外ベースで制御するとぐっとシンプルになる
- Agents for Amazon Bedrockのフローは4パターンある
この記事で使う環境の紹介
-
Agents for Amazon Bedrock
AWSのサービスです。対話型のAIを作れます -
Chalice
Agents for Amazon Bedrockのアプリを一瞬かつ簡単に作れます -
CDK
Chaliceを含む、AWSのサービスを一括で管理することができます -
Zod
TypeScript向けのバリデータです
この記事で扱う言語
- TypeScript(Web画面)
- Python(AIチャットのアプリ、CDK)
サブウェイ風の店員さんをAIで作ってみよう
前提:サブウェイ風って何?
パンの種類、ドレッシングを細かくオーダーできるサンドイッチの店です。
注文のフローは正確ではないのですが、こんな感じです。
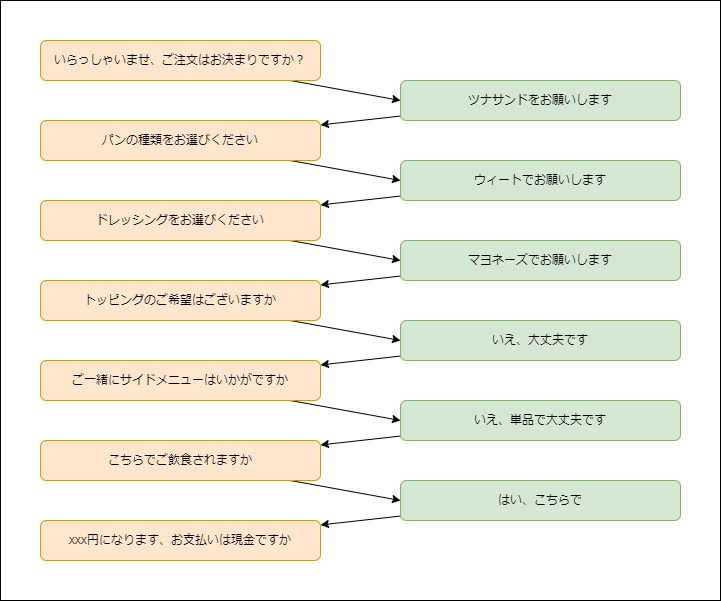
他のファストフード店と比べても長いフローです。
AIで実装した結果
このサブウェイ風の店員さんをAIで実装しました。
以下のキャプチャは、実際に動かしている様子です。
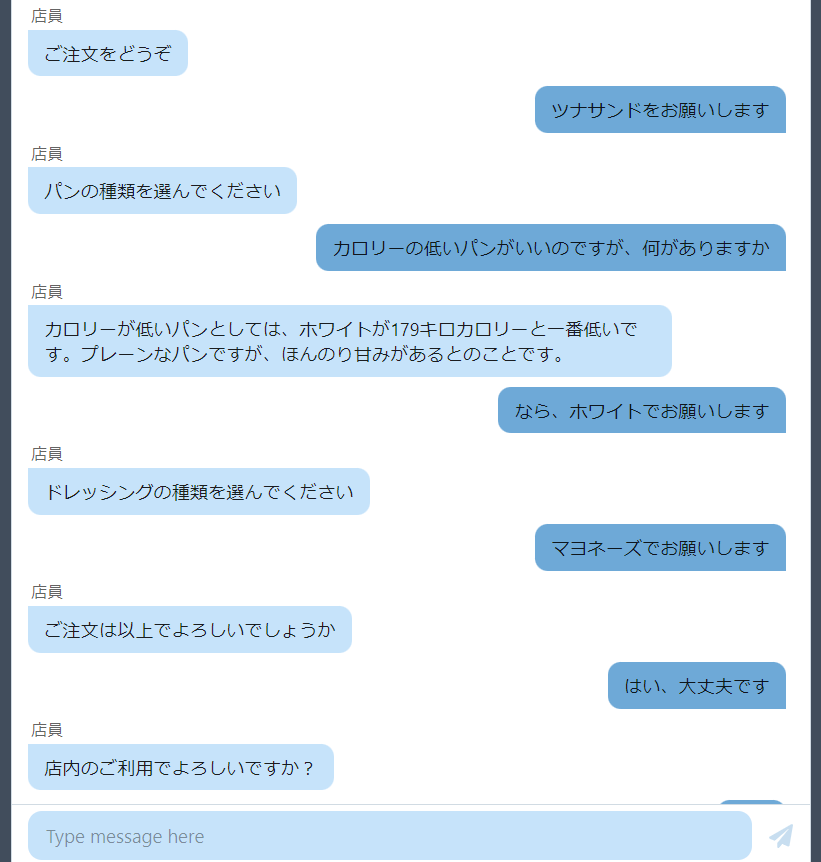
ほぼ人間です。チャットで見る限り、人間と見分けがつかない動きをします。
注文を受けるだけではなく、「何のパンがあるの?」「こういうのはできる?」みたいなやり取りをしながらオーダーを進めることができます。
伝票は画面の右側に表示されて、会話のたびにリアルタイムで更新されます。
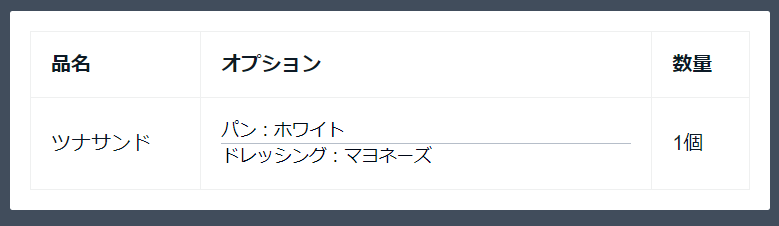
注文完了後、最後の質問に「はい」で答えると、JSON形式の伝票データがLambdaに飛びます。
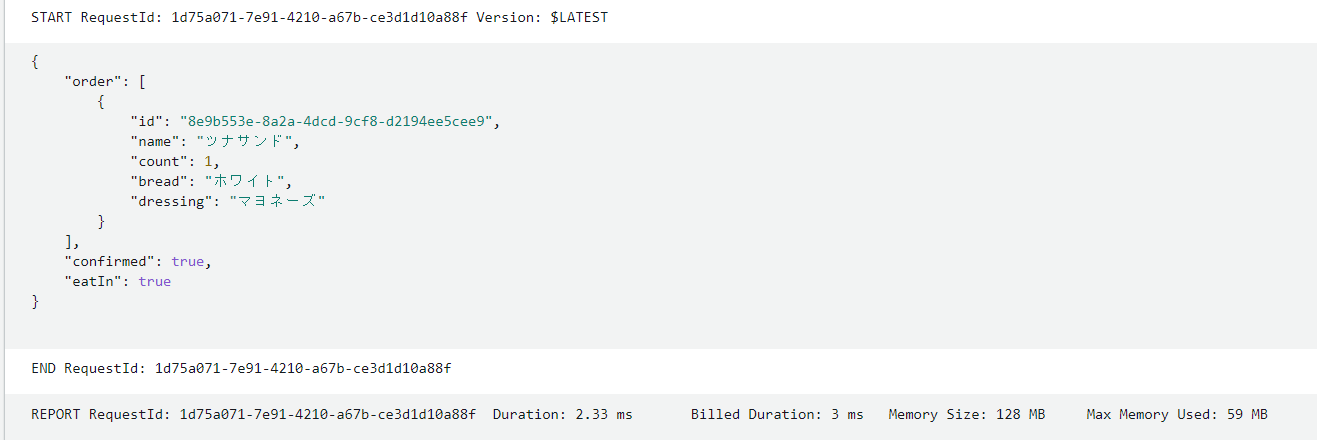
また、慣れた客は店員の会話に先回りして注文をかけることもあるはずです。
まとめた注文も通すことができます。

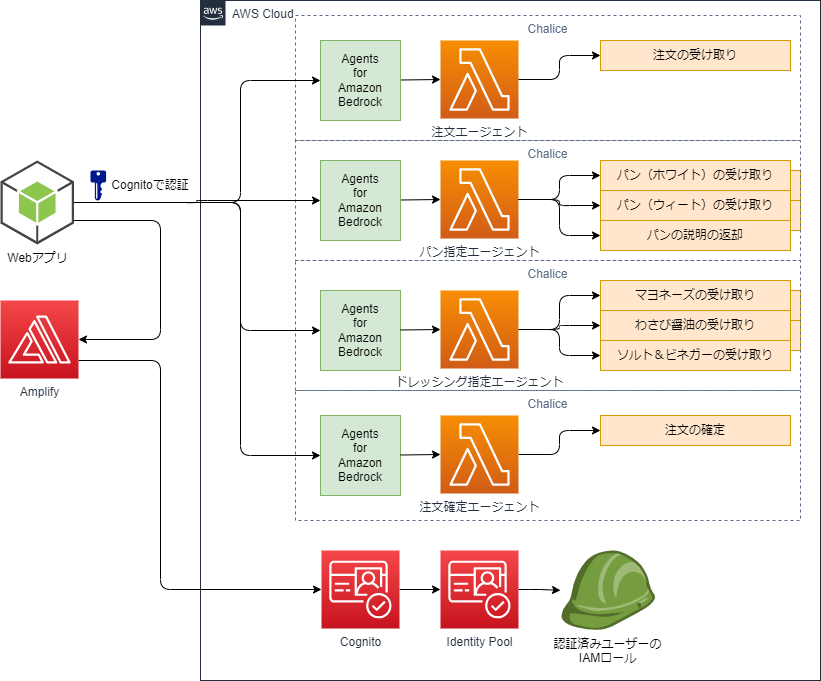
構成図はこちらです。
CDKを使って、Chaliceのエージェントを4つ立てています。
ソースコードがこちらです。
※会話を返すのにかなり時間がかかりますが、Agents for Amazon Bedrockの仕様です。Claude v2 Instantみたいなのに対応するのを待ちましょう。
実装
ソースコード全体はサンプルを見ていただくとよいので、要点だけかいつまんでいきます。
エージェントについて
Agents for Amazon Bedrockでは、質問に回答をする単位のことを「エージェント」と呼びます。
エージェントとLambdaの関係は下の図の通り。エージェントは質問の内容を分析して、Lambdaで定義した適切なAPIに振り分けます。

ChaliceとCDKを使うと、複数エージェントを簡単に作成できます。
※ただ、現状そのまま連携できる状態になっていないので、いくらか手を入れる必要があります。
- Chaliceが上手く動かないので、aws-cdk-libのバージョンを2.72.0まで下げるようにしてください。
- 同じスタックにchaliceを複数立てるとリソース名が衝突するので、スタックを分けて、cdkの--allオプションで連携するようにしてください
- 出力先がchalice.outで固定されているので、スタックごとに違う出力先にできるように修正してください。
エージェントを神にしない
なんとなくエージェントを作るとこうなりがちです。
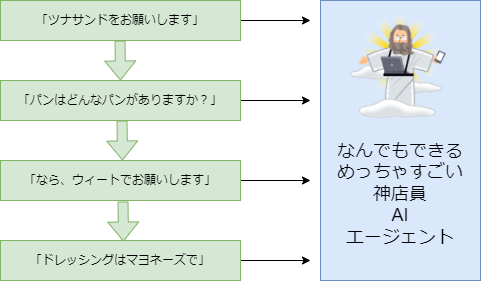
「神が全部答えてくれるエージェント」を立てるのはかなり難しく、メリットがありません。
Agents for Amazon Bedrockの料金はリクエストに対してかかるため、エージェントの数が増えても減ってもAWSの料金は変わりません。精度は上げづらく、わずかにプロンプトを変えただけで全体を巻き込んで挙動が変わります。調整もメンテナンスも難しくなります。
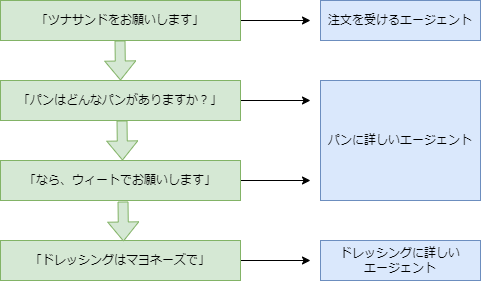
下の図のように、エージェントはできるだけ分業させるほうがいいです。
また、1つのエージェントにぶら下げることのできるAPIの数は多くありません。
QuotaのThe maximum number of APIs that you can add to an Agentにある通り、紐づけることができるAPIは5つまでです。
ですので、エージェントはできるだけ細分化します。
投げた質問に合わせて、ユーザーからの返答を受けるエージェントも変えるべきです。
フローを考える
サブウェイの注文の実装のフローを考えます。
赤線を店員から客への応答、黒線を客から店員への入力として、会話が飛ぶ可能性のある場所を線で結びます。
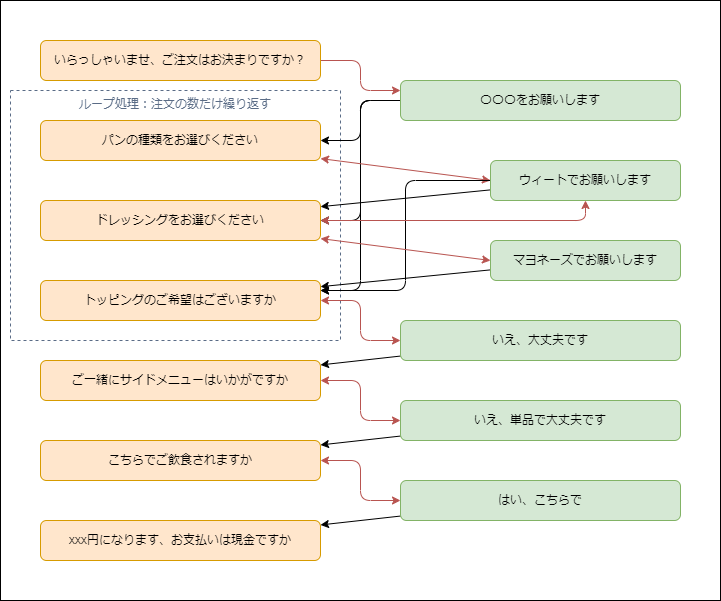
割り込み、ショートカット、聞き返しを繰り返します。そのせいで、ぐるぐると複雑に入り組んだ線が伸びます。
サンドウィッチを注文する仕組みを作るまでもありません、もう実装を始める前からスパゲティでお腹いっぱいです。ですが…

少し考え方を変えると一気にすっきりします。
サンドイッチの注文を受けるには、「①サンドイッチの注文を聞く」「②パンの種類を確認する」「③ドレッシングの種類を確認する」のだと考えるのではなく、サンドウィッチには必須属性の「パン」と「ドレッシング」がある、その必須チェックでエラーなら客にたずねる手順が発生すると考えます。
そうすると、シンプルなフローになります。
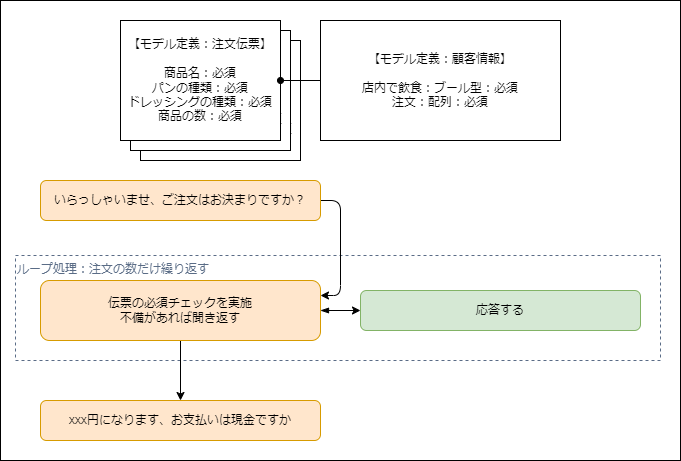
バリデータのZodにはsuperRefineの機能があるため、この形のフローを簡単に実装できます。
エラー情報のデータを独自に定義することができる機能です。
import z from "zod";
// ドレッシングの定義
const AgentDressingType = (parameter: { [key: string]: AgentModelParameter }) =>
z
.string()
.optional()
.superRefine((val, ctx) => {
if (val === undefined) {
ctx.addIssue({
code: z.ZodIssueCode.custom,
message: parameter.aiMessage,
aiMessage: "ドレッシングのご注文をどうぞ",
priority: 1000, // 優先順
agent: {
"agentId": "xxxxxxxxxxx",
"agentAliasId": "xxxxxxxxxxx"
},
} as any);
return z.INVALID;
}
});
function checkDressing(dressing: string | undefined) {
try {
// ドレッシングをチェックする
AgentDressingType.parse(dressing);
} catch (e: any) {
// ドレッシングが未定義なら、issueにaddIssueで格納したデータが入る
const issueList = e.issues
.filter((issue) => (issue.priority ?? 0) >= 1) // 独自定義したissueだけをフィルタする
.sort((a, b) => a.priority - b.priority); // 優先度を数字の小さい順に並べる
if (issueList.length >= 1) {
return issueList[0] as any; // 優先度の数字が最も小さい値を返す
}
}
}
このように書けば、必須チェックエラーの結果として、
{
aiMessage: "ドレッシングのご注文をどうぞ",
priority: 1000, // 優先順
agent: {
"agentId": "xxxxxxxxxxx",
"agentAliasId": "xxxxxxxxxxx"
},
}
このデータが取れます。
これを、TypeScriptのAWS-SDKで、エージェントに対して送信するだけです。
// リクエストを送信する
// agentは必須チェックのエラーからとったエージェント情報
// stateは顧客情報
const send = async (agent, state) => {
let result = "";
// 認証情報をAmplifyから取得する
const creds = await Auth.currentUserCredentials();
// AWS-SDKのクライアントを取得する
const client = new BedrockAgentRuntimeClient({
region: "us-east-1",
credentials: creds,
});
// エージェントにリクエストを送信する
const { sessionId, completion } = await client.send(
new InvokeAgentCommand({
agentId: agent.agentId,
agentAliasId: agent.agentAliasId,
sessionId: v4(), // uuidライブラリから取得したUUID
endSession: false, // セッションの終了宣言はfalse
inputText: inputText, // ユーザーの発言
})
);
if (completion) {
// 結果を取得する
const decoder = new TextDecoder();
for await (const itr of completion) {
result += decoder.decode(itr.chunk?.bytes, {
stream: true,
});
}
}
if (result.length >= 1) {
// JSONとして解析して、分割代入でstateを更新する
const data = JSON.parse(result);
state = {
...state,
...data
}
}
// 処理完了後、再度stateに必須チェックをかける
return state;
}
必須チェック→送信を繰り返すだけで実装できるので、実装が非常にシンプルになりました。
Agentsへのリクエストには4パターンある
シンプルに使う
Agents for Amazon Bedrockをシンプルに使うと、以下のようなデータの流れになります。
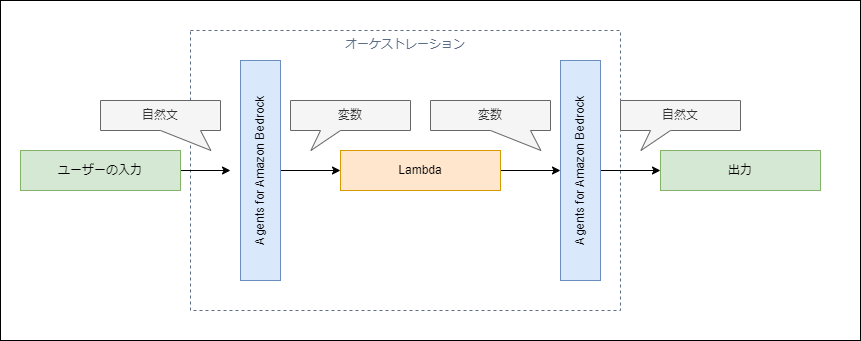
①自然文を受け取って、②Agents for Amazon BedrockがPython向けの変数に変換、③Lambdaが変数を処理して、④処理した結果をAgents for Amazon Bedrockが自然文に変換します。
セッションステートを使う
セッションステートを使うと、以下のようなデータの流れになります。
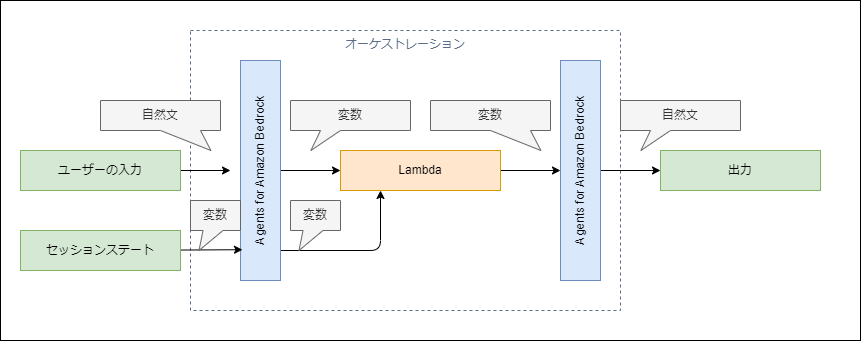
セッションステートの渡し方は以下の通りです。
// エージェントにリクエストを送信する
const { sessionId, completion } = await client.send(
new InvokeAgentCommand({
agentId: agent.agentId,
agentAliasId: agent.agentAliasId,
sessionId: v4(), // uuidライブラリから取得したUUID
endSession: false, // セッションの終了宣言はfalse
inputText: inputText, // ユーザーの発言
// ------------------
// セッションステートを追加する
// -----------------
sessionState: {
sessionAttributes: {
STATEKEY: JSON.stringify(value), // キーと値の形で渡す
},
},
})
);
セッションステートとして受け取った値は、Agents for Amazon Bedrockは何も変換せず、Lambdaにそのままスルーパスされます。認証情報、JSONデータ、時刻など、自然文で渡したくない情報を受け渡す場合に利用します。
Parser Lambdaを使って、スキップする
Parser Lambdaを使うと、以下のようなデータの流れにすることができます。
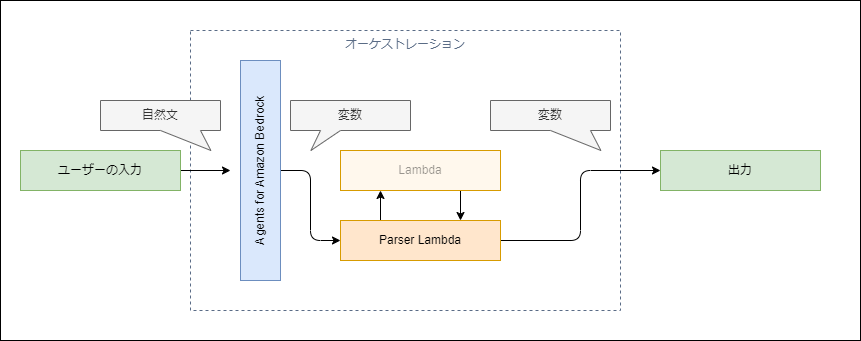
プログラムで変数を作成して、変数をそのまま返すことができます。
自然文を変数にパースするところまではAgents for Amazon Bedrockを利用しますが、変数から自然文に変換するフローを省略します。
Parser Lambdaを使うが、スキップしない
本来のLambdaの実行はスキップすることもできますが、本来のLambdaを呼ぶ場合は以下のようなフローになります。
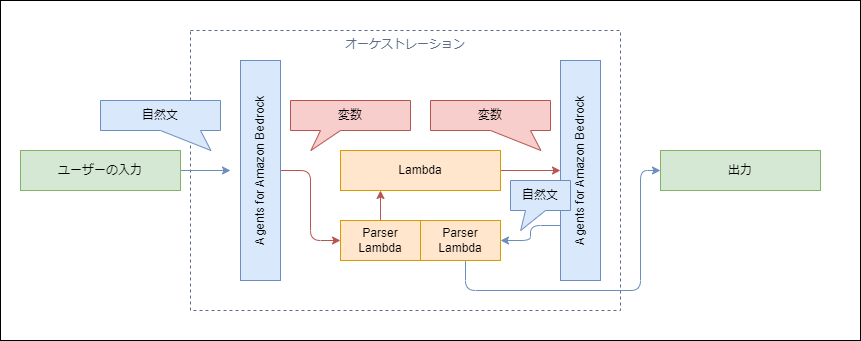
この場合は、返す自然文をプログラム側で整形できます。
どうやって使い分けるの?
上のそれぞれのケースを、出入力に着目して表にまとめるとこうなります。
| パターン | 入力 | 出力 |
|---|---|---|
| シンプルに使う | 自然文 | 自然文 |
| セッションステート | 自然文 変数 |
自然文 |
| Parser Lambdaでスキップする | 自然文 | 変数 |
| Parser Lambdaでスキップしない | 自然文 | 変換した自然文 |
| (API Gateway) | 変数 | 変数 |
- 例:注文をしたあと、内容を確定する場合
→ セッションステートを使う
AIの質問:「出荷してよろしいですか?」
ユーザーの入力:「はい、お願いします」
この「はい、お願いします」と一緒に、セッションステートで注文情報を渡します。
「はい、お願いします」のLambdaの中で出荷処理をすれば、確認を取ったうえで出荷フローに流すことができます。
- 例:注文データを画面側で分割代入させる場合
→ Parse Lambdaを使う
AIの質問:「パンはどのような種類にしますか?」
ユーザーの入力A:「ウィートでお願いします」
ユーザーの入力B:「どんなパンがありますか?」
ユーザーの入力がAとBが考えられるため、AIのプロンプトはBに合わせて作ります。
AのパターンはParser Lambdaを使ってJSON形式で返します。Parser Lambdaを通るとLLMの影響を半分しか受けないため、プロンプトの作りがシンプルになります。
画面と密接に連携をするのならParser Lambdaを、送信するデータが多いのならセッションステートを、RAGのように使うのならシンプルな使い方をします。
まとめ
Agents for Amazon Bedrockは、かなり人間らしい動きをするエージェントが作れます。
開発にかかる時間も短く、GPUを積んだ高価な機材も不要です。今回のサンプルプロジェクトも4万円のChrome bookを使って3日ほどでコーディングしました。
ChaliceはCDKと連携も(現時点ではいくつか改善すべき場所があるものの)できますので、レベルの高いシステムを作っていくこともできると思います。
ChaliceとAgents for Amazon Bedrockの連携の紹介はこちらです。