この記事について
この記事では、CloudWatch Logsを使ってセマンティック検索をする方法を紹介します。
CloudWatch Logsでセマンティック検索ができると何が嬉しいのか?
- ログをエラーのニュアンスから検索できる
- 料金が安い(小規模であれば全く料金がかからない)
- スキーマを決めずに雑に運用できる
- Lambdaに元々あるCloudWatch Logsの書き込み権限が使えるため、IAMの権限を増やす必要がない
今回の記事のソース
今回の記事のソース全体はこちらに置いています。
記事では要点だけ触れますので、つながりで不明点のある場所はこちらでご確認ください。
動いている様子
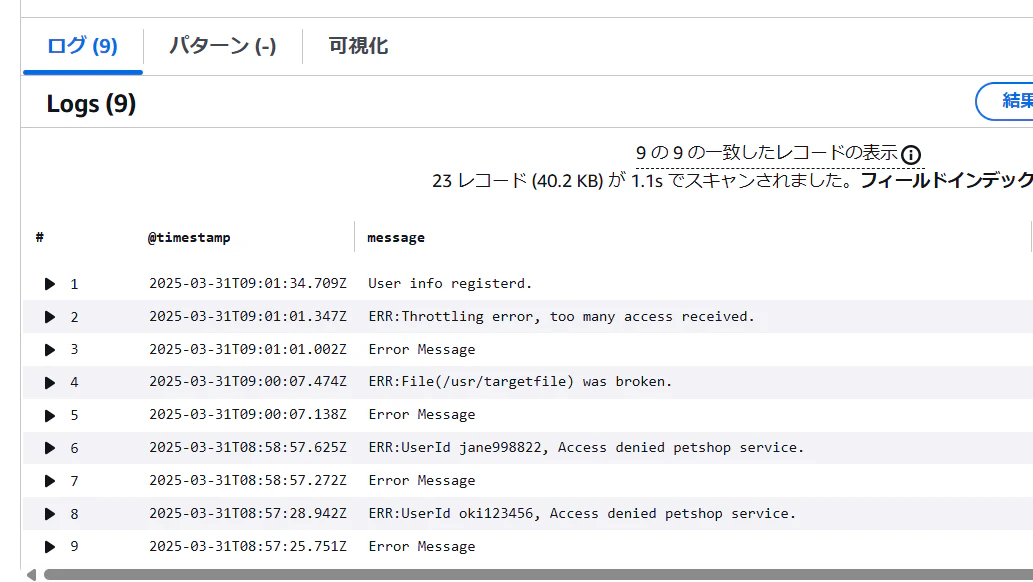
CloudWatch Logsに置いてあるログ
CloudWatch Logsに以下のようなログが登録してあります。
CloudWatch Logs Insightで検索した結果です。
セマンテック検索をする
このログに対してセマンティック検索をかけます。
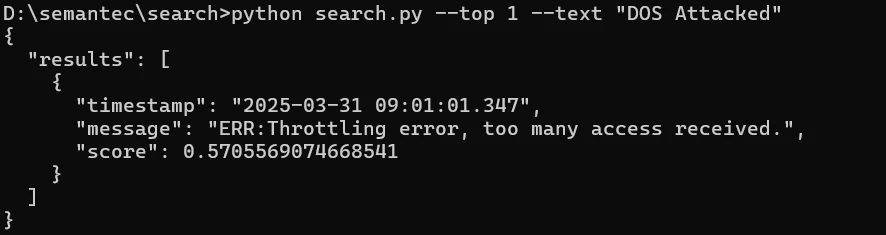
"DOS Attacked"で検索すると、スロットリングエラーのログが返ります。
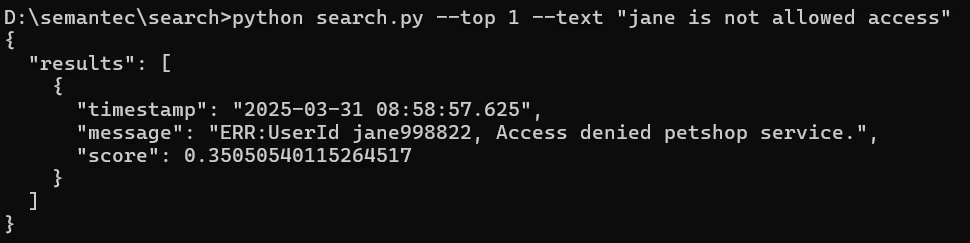
"Jane is not allowed access"で検索すると、jane998822さんのAccess Deniedのエラーが返ります。
セマンティック検索は、言葉のニュアンスで検索をかける検索方法です。
エラーメッセージの仕様がわからなくても、「DOS攻撃をされたっぽい」「なんだかアクセスできない」と検索をするだけで関係するログを返してくれます。
実装: ログの登録
ログの登録は以下のように実施しています。
# ログにベクトル表現をつけて登録する
logger.error(message)
実行時間
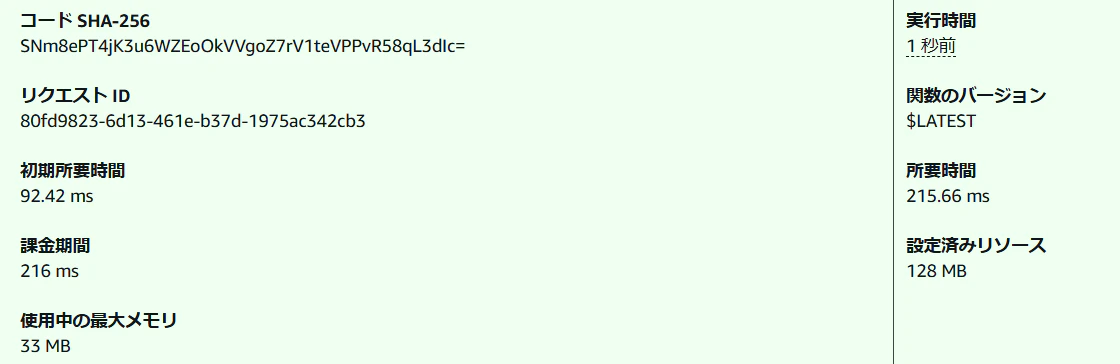
ベクトル表現の変換のために通信が走るため、ログの登録がある時の実行時間は4秒ほどかかります。
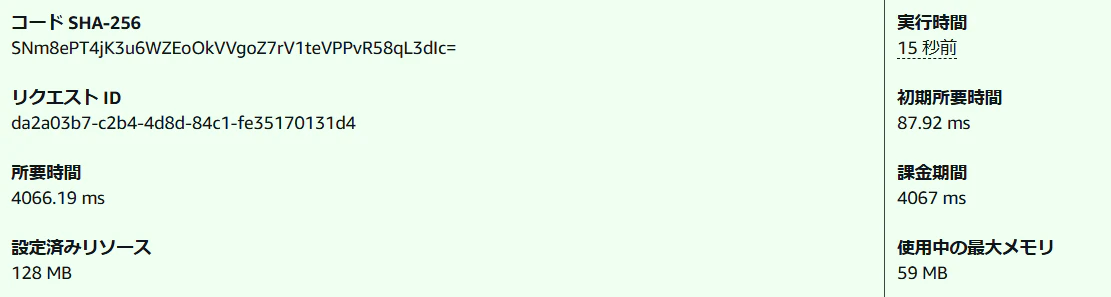
もしログの出力がなかった(上のlogger.errorが呼ばれなかった)なら、200ms程度で処理を完了できます。コールドスタート中、ウォームスタート中、どちらも200msで完了します。
どうやって実現するのか
今回は、無償で使えるGoogleの埋め込みLLM(Text Embedding-004)を使っています。
※マルチリンガルのモデルではないので、英語->英語です。マルチリンガルのモデルを使うと日本語で英語を検索できるようになります。
1.ログにベクトル表現を埋め込む
CDKで必要なリソースを作成します。
CloudWatch LogsとLambdaを作成します。
特別なことを2つしています。
- インデックスポリシーをログに設定する
- Lambda LayerでPowerToolsを指定する
// ロググループを作成する
const asyncLoggingLogGroup = new logs.LogGroup(
this,
"AsyncLoggingLogGroup",
{
// ロググループ名を指定する
logGroupName: `/aws/lambda/async-logging-function`,
// CDKを破棄したときに、ロググループも破棄する
removalPolicy: cdk.RemovalPolicy.DESTROY,
// インデックスポリシー(検索用インデックス)を作成する
fieldIndexPolicies: [
new logs.FieldIndexPolicy({
fields: ["embeddingLevel"],
}),
],
}
);
// ログを出力する関数を作成する
const asyncLoggingFunction = new lambda.Function(
this,
"AsyncLoggingFunction",
{
// ランタイムはPython3.13とする
runtime: lambda.Runtime.PYTHON_3_13,
// 上で作成したログを指定する
logGroup: asyncLoggingLogGroup,
// 環境変数、タイムアウト、ソース指定、ハンドラ指定は普段通りなので中略
...中略
// 公式レイヤーのAWS Lambda Powertoolsを指定する
layers: [
lambda.LayerVersion.fromLayerVersionArn(
this,
"AwsPowerTools",
`arn:aws:lambda:${region}:017000801446:layer:AWSLambdaPowertoolsPythonV3-python313-x86_64:7`
),
],
}
);
CloudWatch Logsにインデックスポリシーが指定してあると、InsightsのクエリでfilterIndexを書くことができます。
これまでのCloudWatch Insightsは期間内のログの総量で料金が決まっていたのですが、filterIndexを指定すると、指定したフィルタ条件に合うログだけが課金対象になります。この指定でInsightsの料金が大幅に安くなります。
また、PowerToolsをレイヤーに指定すると、Lambdaのログの設定をInsightsで扱いやすい形にしてくれます。
2.ログをベクトル表現に変換する
ログの出力処理は以下の通りです。
LambdaからCloudWatch Logsにログを吐き出すだけですから、loggerを確保してinfoやerrorを呼び出すだけで出力できます。
# PowerToolsでロガーを確保する
from aws_lambda_powertools import Logger
# ロガーを設定する
logger = Logger(service="embedding-logging")
# ログを出力する
logger.info(LOG_MESSAGE, extra={
# 埋め込みベクトルを登録
"embedding": b64binary.decode("utf-8"),
# filterIndexにembeddingLevelを指定してあるので、データを入れる
"embeddingLevel": LOG_LEVEL,
})
今回はログのベクトル化が必要ですので、以下のソースでログのメッセージをベクトル化しています。
from string import Template
import struct
import base64
from urllib import request
import json
# PowerToolsでロガーを確保する
from aws_lambda_powertools import Logger
# ロガーを用意する
logger = Logger(service="embedding-logging")
# GeminiのURLを指定する
gemini_url = Template(
"https://generativelanguage.googleapis.com/v1beta/models/${model}:embedContent?key=${GEMINI_API_KEY}"
)
# Geminiに送るPOST Bodyを定義する
body = json.dumps(
{
"model": "models/" + EMBEDDING_MODEL,
"content": {"parts": [{"text": LOG_MESSAGE}]},
}
).encode("utf-8")
# HTTPSリクエストの送信要求を定義する
req = request.Request(
url=gemini_url.substitute(
model=EMBEDDING_MODEL,
GEMINI_API_KEY=GEMINI_API_KEY,
),
data=body,
headers={"Content-Type": "application/json"},
method="POST",
)
# HTTPSでリクエストを送る
with request.urlopen(req) as response:
values = json.loads(response.read().decode("utf-8"))["embedding"]["values"]
# ベクトル表現を32ビット浮動小数点小数でバイナリ化する
binary = struct.pack("0".zfill(DIMENSION).replace("0", "f"), *values)
# バイナリをBase64で文字列に変換する
b64binary = base64.b64encode(binary)
# ログを出力する
if LOG_LEVEL == "INFO":
logger.info(LOG_MESSAGE, extra={
"embedding": b64binary.decode("utf-8"),
"embeddingLevel": LOG_LEVEL,
})
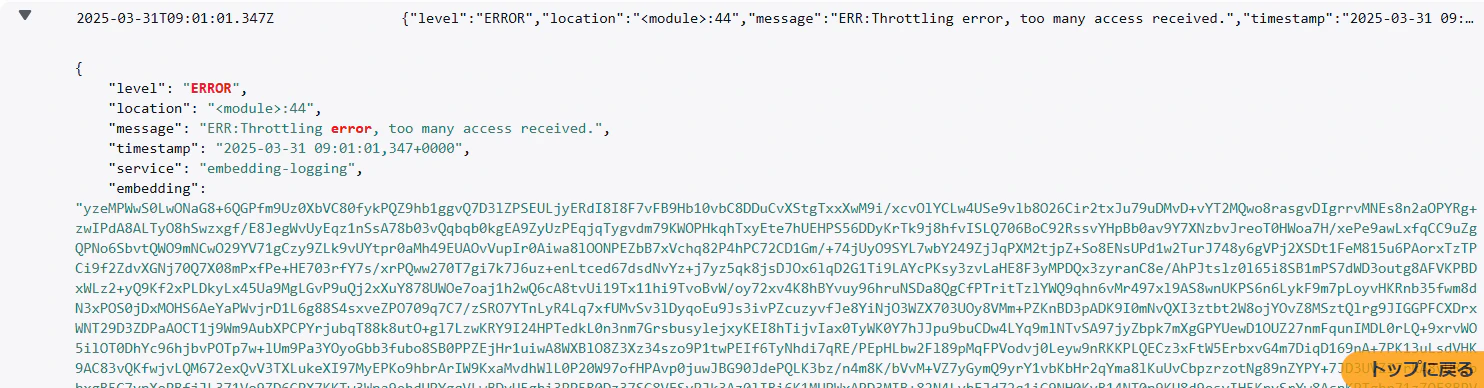
Text Embedding-004は768次元あります。32ビット浮動小数点小数にするため、1次元あたり4バイトになりますから、3072バイトのバイナリになります。さらにbase64で4/3倍になりますから、4KBの文字列でベクトル表現が記録されます。
実際に記録されたところは下記の通りです。
3.検索をする
boto3でInsightsからログを検索するソースは、AWSが公式のドキュメントで紹介しています。
同じソースで良いのでCloudWatch Logsからベクトル表現の一覧を取ります。
検索したい文字列のベクトル表現をコサイン類似度で比較して、最も似ているテキストを検索すれば完成です。
コサイン類似度は以下のソースで判定できます。
def distance_pow(vec: list[float]) -> float:
"""
距離の二乗を取得する
vec: 取得する対象のベクトル
"""
return sum([v * v for v in vec])
def cosign_distance(vec1: list[float], vec2: list[float]):
"""
コサイン距離を取得する(似ているほど-1に近い、似ていないほど大きくなる)
"""
# L2を取る(0.5乗するとルートが取れる)
l2_length = (distance_pow(vec1) ** 0.5) * (distance_pow(vec2) ** 0.5)
if l2_length == 0.0:
# L2が異常値になるなら0を返す
return 0.0
# 内積を取る
dot_product = sum([v1 * v2 for v1, v2 in zip(vec1, vec2)])
# コサイン類似度を計算する(変化の方向をユークリッド距離に合わせたいので、1.0から引いてコサイン距離とする)
return 1.0 - (dot_product / l2_length)
def calc_distance_list(
base_point: list[float], reference_points: list[list], distance_function
):
"""
基準点(base_point)を元に、データ点(reference_points)それぞれまでの距離を取得する
"""
return [
# 基準点から対象の点までの距離を求めて、距離リストに追加する
distance_function(blue_point, base_point)
for blue_point in reference_points
]
def nearest(
base_point: list[float],
reference_points: list[list],
distance_function=cosign_distance,
topk: int = 1,
):
"""
基準点から見て、最も距離の近いデータ点を取得する
"""
knn = sorted(
# 距離のリストに、インデックスをつけてソートする
enumerate(calc_distance_list(base_point, reference_points, distance_function)),
# enumerateで、インデックスと値の配列になるので、x[1]で値を取得する
key=lambda x: x[1],
# 距離の昇順でソート、距離が小さいものを先頭に置く
reverse=False,
)
return [{"index": k[0], "score": k[1]} for k in knn[:topk]]
from knn import nearest
# ベクトル表現で類似度を検索、最も似たログを取得する
response = nearest(
検索テキストのベクトル表現,
ログから取得したベクトル表現の一覧,
topk=表示する件数,
)
そのほか
ベクトル表現の変換をそのまま呼び出すと、importにかかる時間分だけコールドスタート時に遅延します。そのため、サブインタープリタを使って遅延インポートをしています。
ソースは2.ログをベクトル表現に変換するのソースのままですが、一か所だけサブインタープリターで動かすために変更する必要があります。
import sys
sys.path.append("/opt/python")
サブインタープリターでは実行環境の変数が初期化されるため、Lambdaに設定したレイヤーへのパスが参照できない状態になっています。/opt/pythonへの参照を追加することで、LambdaLayerにあるPowerToolsを利用できるようにします。
立ち上げたスレッドの中でサブインタープリターを実行すると、Lambdaとは別のスレッドで通信処理とログ出力が走ります。サブインタープリター内部のimportも実行後に別スレッドで行われるため、セットアップに時間のかかるライブラリをサブインタープリターの中に入れることで、Lambdaのコールドスタートによる処理の遅延を回避することができます。
まとめ
ベクトル検索用のサービスを導入しなくても、CloudWatch Logs + PowerToolsによるJSON形式のログでベクトル検索ができるのではないかと検証しました。2024年の末に増えたfilterIndexでCloudWatch LogsのInsightを使った検索が低コストになったこともあり、使い勝手良く検索できることが確認できました。