この記事について
この記事では、以下の埋め込みモデルを扱います
- Titan Text Embeddings(amazon.titan-embed-text-v1)
- Cohere Embed - Multilingual(cohere.embed-multilingual-v3)
- OpenAI Ada(text-embedding-ada-002)
- OpenAI Embedding 3(text-embedding-3-large)
この記事を3行+グラフで
- 埋め込みモデルのベクトル表現を2Dの散布図で可視化した
- 性能差が分かりやすく、OpenAIのEmbedding 3が圧倒的、次点でCohereが強い
- キーワードの傾向を調べると、性能の出ていないベクトル表現でもそれなりのスコアにはできる
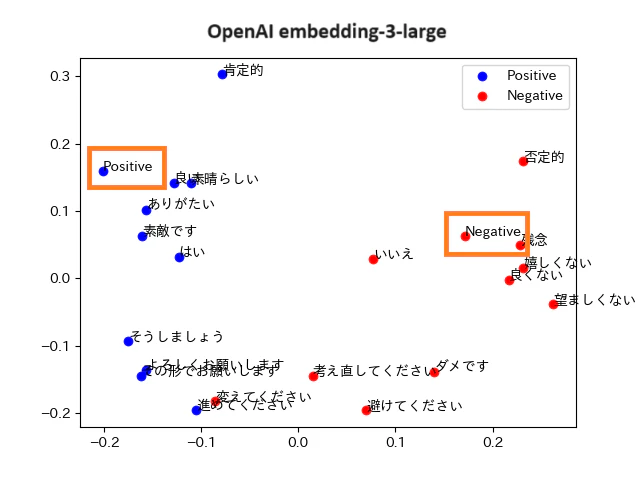
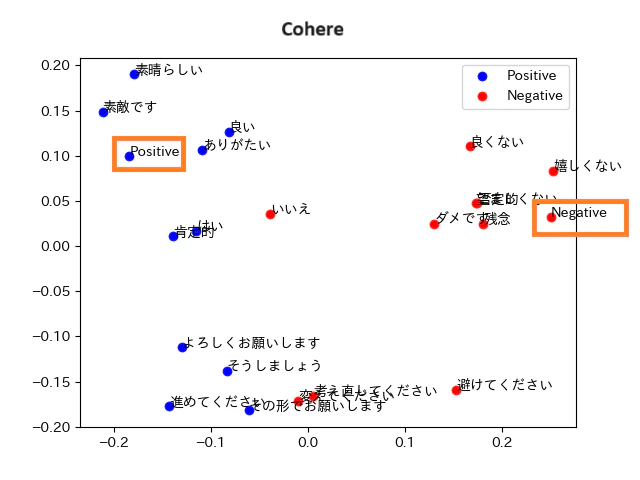
スコアの高い埋め込みモデルは、グラフにすると以下のようになりました。クラスタの位置、クラスタに配置された単語の構成を見ると、どちらのモデルも似ていることが分かります。
| OpenAI Embedding 3 | Cohere Embed - Multilingual |
|---|---|
 |
 |
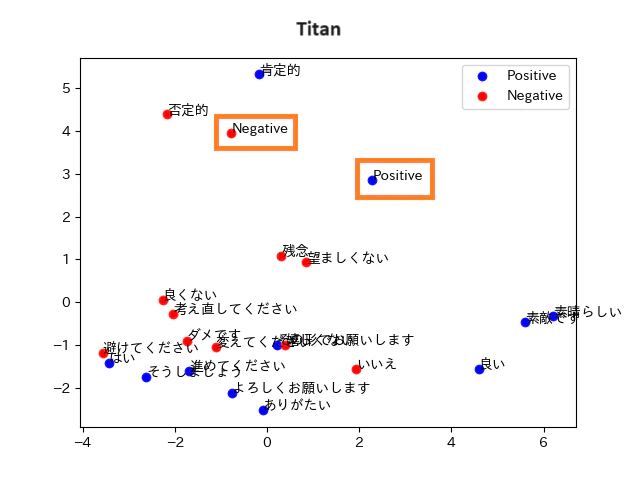
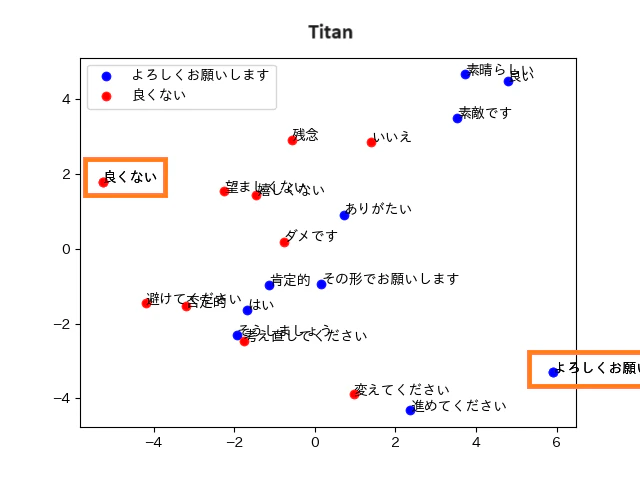
Titan Text Embeddingsは、英語と日本語で異なるクラスタを作っているように見えます。検索単語を変えることでスコアが上がること、スコアの向上がグラフに現れることが確認できました。
| 英語で日本語を検索(60%正答) | 日本語で日本語を検索(75%正答) |
|---|---|
 |
 |
検証したこと
このような会話を生成AIで処理するとします。

この「大丈夫です」は、「YES」の意味なのか「NO」の意味なのかを分類します。
「大丈夫です」なら分かりやすいのですが、あいまいな応答が来ることもあります。


この「YES」「NO」の判断を、生成AIの埋め込みモデルで分類することを考えます。
なぜ埋め込みモデル?
ClaudeのようなLLMでも分類はできるのですが、埋め込みモデルを使うモチベーションやメリットには以下の表の通りです。Haikuよりも料金が安く、応答時間が早く、結果が安定しています。
また、複数件のレコードを1度のAPI実行で一括変換することもできます。
| Cohere | Claude Sonnet | Claude Haiku | |
|---|---|---|---|
| 1Mトークンあたりの入力料金 | $0.1 | $3.0 | $0.25 |
| 1Mトークンあたりの出力料金 | 無料 | $15.0 | $1.25 |
| APIが応答するまでの時間※ | 0.88秒 | 2.195秒 | 1.650秒 |
| 同じ入力への応答 | 必ず同じ応答が返る | 設定により不定 | 設定により不定 |
※応答時間は5回連続で実行したときの応答時間の平均で計測しています
もしAPIGateway+Lambdaで埋め込みモデルを使ったテキストの分類を実装する場合は、以下のソースで実装できます。依存ライブラリは不要です。

デプロイしたものをcurlで実行すると、0.9秒で分類結果が返ってきます。
APIGateway+Lambdaで埋め込みモデルの分類を実行するソース(クリックで開く)
import json
import boto3
def distance_pow(vec: list[float]) -> float:
"""
距離の二乗を取得する
vec: 取得する対象のベクトル
"""
return sum([v * v for v in vec])
def cosign_distance(vec1: list[float], vec2: list[float]):
"""
コサイン距離を取得する(似ているほど-1に近い、似ていないほど大きくなる)
"""
# ノルム同士をかけてL2を取る(0.5乗してルートを取る)
l2_length = (distance_pow(vec1) ** 0.5) * (distance_pow(vec2) ** 0.5)
if l2_length == 0.0:
# L2が異常値になるなら0を返す
return 0.0
# 内積を取る
dot_product = sum([v1 * v2 for v1, v2 in zip(vec1, vec2)])
# コサイン類似度を計算する(変化の方向をユークリッド距離に合わせたいので、1.0から引いてコサイン距離とする)
return 1.0 - (dot_product / l2_length)
def nearest(
base_point: list[float],
reference_points: list[list],
topk: int = 1,
):
"""
基準点から見て、最も距離の近いデータ点を取得する
"""
knn = sorted(
# 距離のリストに、インデックスをつけてソートする
enumerate(
[
# 基準点から対象の点までの距離を求めて、距離リストに追加する
cosign_distance(blue_point, base_point)
for blue_point in reference_points
]
),
# enumerateで、インデックスと値の配列になるので、x[1]で値を取得する
key=lambda x: x[1],
# 距離の昇順でソート、距離が小さいものを先頭に置く
reverse=False,
)
return [{"index": k[0], "score": k[1]} for k in knn[:topk]]
def lambda_handler(event, context):
"""
エントリポイント
"""
# リクエストからテキストを取得
text = json.loads(event.get("body", "{}")).get("text", "")
# BedrockでCohereを実行する
bedrock = boto3.client("bedrock-runtime")
response = bedrock.invoke_model(
body=json.dumps(
{
# 対象のテキスト
"texts": [
text,
"Positive",
"Negative",
],
# 埋め込みモデルの利用想定
"input_type": "clustering",
# トークンの最大長を超えたとき、どのように処理をするか
# None -> 何もしない
"truncate": "NONE",
}
),
modelId="cohere.embed-multilingual-v3",
accept="application/json",
contentType="application/json",
)
# Cohereからレスポンスを取得する
response_body = json.loads(response.get("body").read())
# それぞれのベクトル表現を取得する
input_text_vector = response_body.get("embeddings")[0]
positive_vector = response_body.get("embeddings")[1]
negative_vector = response_body.get("embeddings")[2]
# ポジティブ、ネガティブのどちらに近いかを判定する
result = nearest(input_text_vector, [positive_vector, negative_vector])
nearest_index = result[0]["index"]
result_text = ""
# ポジティブに近いのならPositiveを返す
if nearest_index == 0:
result_text = "Positive"
# ネガティブに近いのならNegativeを返す
if nearest_index == 1:
result_text = "Negative"
return {
"statusCode": 200,
"body": json.dumps({"result": result_text}),
}
検証手順
入力として、20個のキーワードを用意しました。
| グループ1 | グループ2 |
|---|---|
| はい | いいえ |
| 良い | 良くない |
| 素敵です | 望ましくない |
| 素晴らしい | 考え直してください |
| ありがたい | 残念 |
| その形でお願いします | 嬉しくない |
| 肯定的 | 変えてください |
| 進めてください | 否定的 |
| よろしくお願いします | 避けてください |
| そうしましょう | ダメです |
それぞれの入力に選んだキーワードが、「Negative」と「Positive」の単語のどちらに似ているのかを判定します。グループ1はPositiveになることを期待して選んだ単語、グループ2はNegativeになることを期待して選んだ単語です。
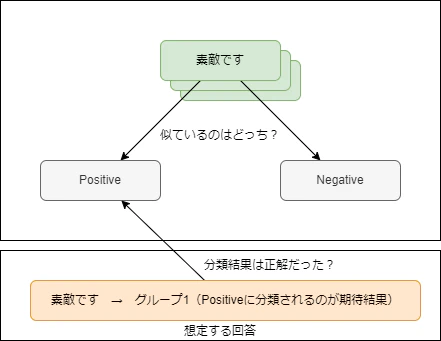
期待通りの分類結果になった割合を正答率とします。
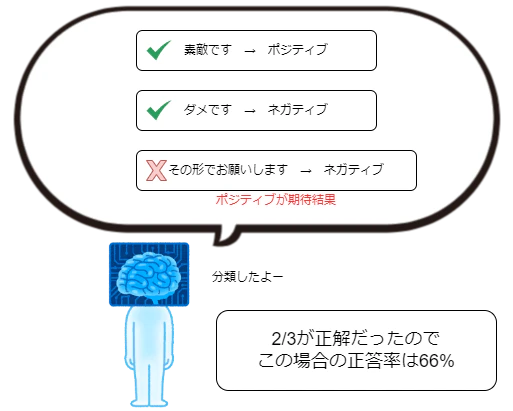
上記の手順を4つのLLMのモデルに対して実施、それぞれの正答率を出して、2Dグラフで可視化しました。
可視化の手順
可視化の流れは下図の通りです。例として「ヨークシャーテリア」の単語を可視化します。
※厳密ではなく、かなり簡略化した図です

ベクトル表現の一部から、関係する情報のベクトル表現だけを抜き出します。抜き出したベクトル表現をPCA(主成分分析)で次元削減すると、情報を壊さないまま2次元前後まで次元を減らすことができます。
この方法で、可視化が上手く動くことは以下の記事で検証しました。
ソースコードはこちらにあります。
今回の検証も同じソースコードを使っています。
検証結果:正答率
まず、グループ1、グループ2の分類に使う単語を「Positive」と「Negative」にして検証しました。
検証の結果、それぞれのモデルの正答率は以下のようになりました。
| モデル | 正答率 | 次元数 | グループ1の単語 | グループ2の単語 |
|---|---|---|---|---|
| text-embedding-3-large | 100% | 3072 | Positive | Negative |
| Cohere Embed - Multilingual | 95% | 1024 | Positive | Negative |
| text-embedding-ada-002 | 90% | 1536 | Positive | Negative |
| Titan Text Embeddings | 60% | 1536 | Positive | Negative |
Titan Text Embeddingsのグラフを見ると、言語をまたいだ検索が難しいように見えたため、分類に使う単語を日本語に変更して、再度実施しました。
日本語同士の比較の検証の結果、それぞれのモデルの正答率は以下のようになりました。
| モデル | 正答率 | グループ1の単語 | グループ2の単語 |
|---|---|---|---|
| text-embedding-3-large | 95% | ありがたい | 望ましくない |
| Cohere Embed - Multilingual | 90% | 素敵です | 嬉しくない |
| Titan Text Embeddings | 75% | よろしくお願いします | 良くない |
※Adaは可視化できる下限まで次元を削り込めていないため、単語の選定ができず、対象から除外しました。
検証結果:可視化した画像
それぞれのモデルの可視化画像は以下の通りです。
- 青丸:グループ1の単語(Positiveが期待結果)です
- 赤丸:グループ2の単語(Negativeが期待結果)です
- オレンジ色の枠:分類に使う単語です
正しく分類されていれば、オレンジの枠の単語を中心に、青色の丸と赤色の丸が2つのグループに分かれます。グループの間にははっきりとした層が出ます。
「Positive」「Negative」の分類の可視化結果は以下のようになりました。
Embedding 3 large
正答率:100%
誤答した単語は一つもありませんでした
Cohere Embed - Multilingual
正答率:95%
誤答した単語:「いいえ」
Embedding Ada 002
正答率:90%
誤答した単語:「いいえ」「変えてください」
備考:分類単語の距離が近く、可視化できる次元数まで削減しきれていないように見えます
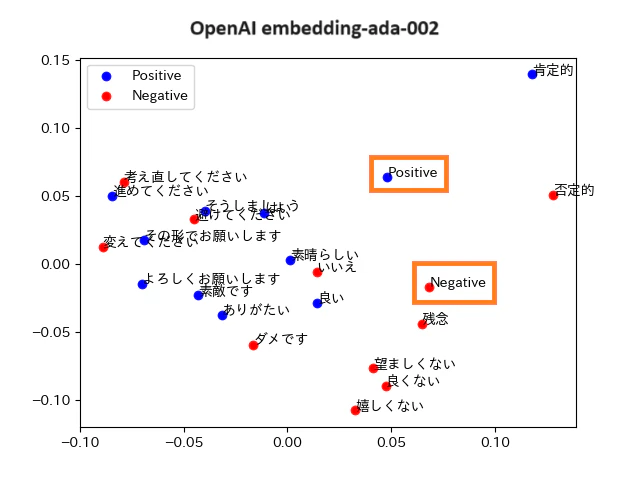
Titan Text Embeddings
正答率:60%
誤答した単語:「そうしましょう」「はい」「よろしくお願いします」「肯定的」「進めてください」「いいえ」「嬉しくない」「望ましくない」
備考:英語と日本語のクラスタが分かれていて、正しく分類できていないように見えます
検証結果:分類単語を日本語に変更
分類に使う単語を日本語に変更した結果は、以下の通りになりました。
Embedding 3 large
正答率:95%
誤答した単語:「進めてください」
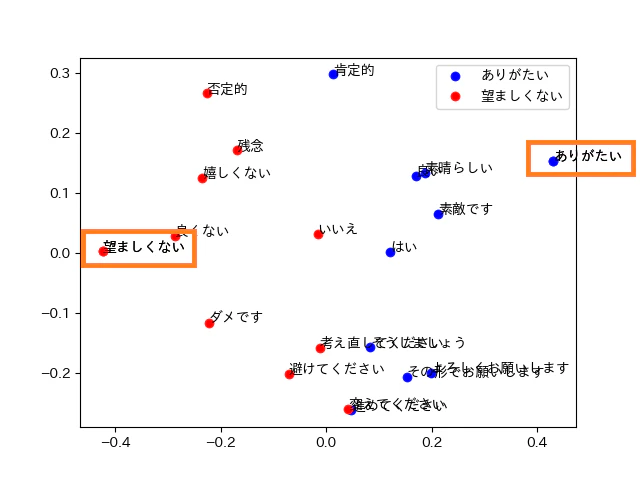
Cohere Embed - Multilingual
正答率:90%
誤答した単語:「いいえ」「変えてください」
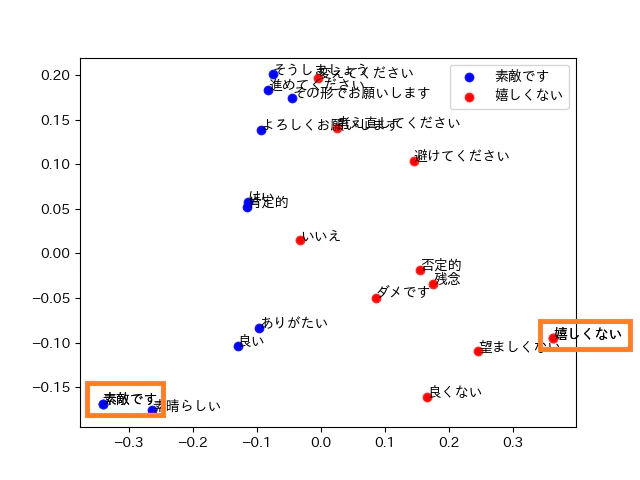
Titan Text Embeddings
正答率:75%
誤答した単語:「そうしましょう」「はい」「いいえ」「変えてください」「残念」
備考:日本語で分類することで、結果が改善しました
結果
検証の結果から分かったことを列挙します。
- Embedding 3、Cohereは性能が高く、万能
性能差は大きく、この2つのモデルはどの条件でも高い性能を出しました。
- Embedding 3とCohereの傾向は似ている
グラフを良く見ると、Embedding 3とCohereは似ていることが分かります。
| Embedding 3 | Cohere |
|---|---|
|
|
素晴らしい、素敵ですは「Positive」の近くに集まってクラスタを作っていて、嬉しくない、良くないは「Negative」の近くに集まってクラスタを作っています。図の下のほうでは、よろしくお願いします、そうしましょうが3つ目のクラスタを作っています。
基本的な点の配置、類似だと判定する傾向は似ています。
- Titan Embeddingは得意不得意の傾向が強い
Embedding 3、Cohereはどの条件でも精度が出ましたが、Titan Embeddingは得意不得意が見られました。
得意不得意がはっきりしているため、精度を出しやすいキーワード、精度の落ちるキーワードがあります。
おまけ
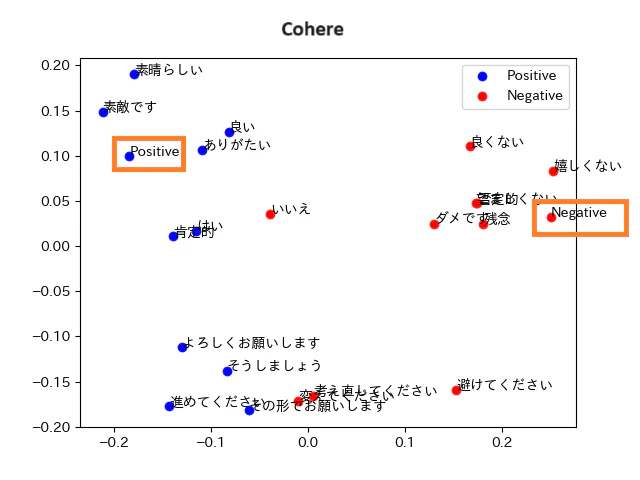
Cohere Embed - Multilingualは、引数として利用目的を指定することができます。
引数を変えて、それぞれベクトルを可視化してみます。
Clusteringを指定すると以下のようになりました。
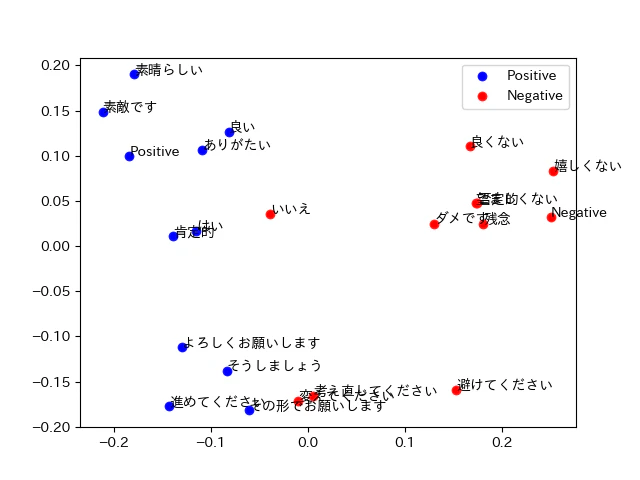
Classificationを指定すると以下のようになりました。
Search Queryを指定すると以下のようになりました。
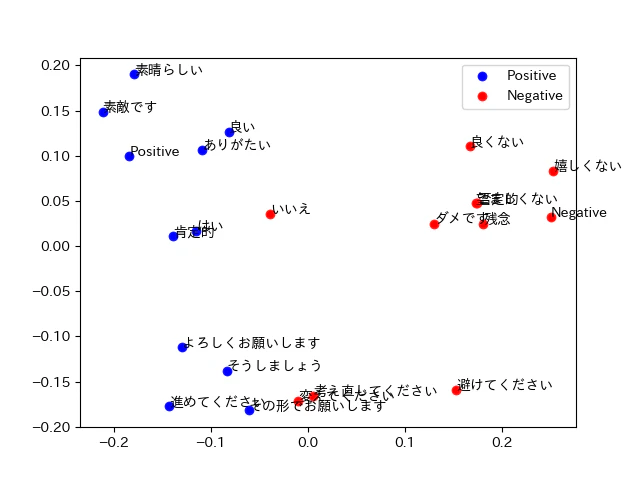
一緒に見えます。単語だと影響がないのかもしれないです。