初めに
年の瀬なので,という訳ではないですが,研究以外の時間として少しだけ.
統計学は極めて興味深く,重要な分野です.中でも特に面白いのが「不偏推定量」というものなのですが,個人的な感覚としてこれはあまり有名ではない気がしています.「是非知ってほしい」というのと,「計算を忘れがちなのでメモしておこう」ということで,ここでは標本平均と標本分散がそれぞれ母平均と母分散の不偏推定量か否かを確認します.
上記の問いに対する解答は有名なので,結論から言うと:
- 標本平均は母平均の不偏推定量です.
- 標本分散は母分散の不偏推定量ではありません.
では,なぜ?というのが次の問いなので,本稿ではこれらの結論に到達するまでの過程を勉強してみます.
母集団と標本
まずは母集団と標本という概念.
有名なお味噌汁の話から始めます(こちら,@WolfMoonさんからご指摘いただいた通り,誤解を起こす可能性があります,).お味噌汁を友人に振る舞うとしましょう.折角の機会なので,美味しく作って見栄を張りたいわけです.美味しくできたか確認する方法の一つは,鍋の中のお味噌汁を全て飲み干して味見することです.これで今日作ったお味噌汁の味が完全・完璧に分かります.しかし,これでは皆に出す分が無くなってしまいます.そこで,小皿に少しだけ取って味見します.これでお味噌汁の味も分かるし,皆にも食べてもらえます.
これは,見方を変えれば,小皿に少しだけ取ったお味噌汁の情報から,鍋の中のお味噌汁全体の情報を推定しているものと解釈できます.この考えは統計学の根幹に当たるもので,「少しの(あるいは幾らか限られた)情報から全体の状態を推定する」というものです.このとき,鍋の中のお味噌汁全体を「母集団」,小皿に取り分けた少しのお味噌汁を「標本」と呼びます.また,小皿に取り分ける操作を「標本抽出」と呼びます.
標本サイズ vs. 標本数
これらの言葉は頻繁に混乱を招きます.なぜなら,字面はとても似ているのに全く異なる意味を持っているからです.ここで文字に起こしておき,気になったときに振り返ることができるようにしておきましょう.
それぞれの意味は以下の通りです.
- 標本サイズ: 1回の標本抽出でどれだけの標本を抽出したか
- 標本数 : 標本抽出を何回実行したか
例えば,鍋の中から10mlだけお味噌汁を取り出して味見するという操作を5回繰り返すとします.このとき,「10」が標本サイズ,「5」が標本数です.因みに,標本抽出するたびに標本サイズが異なっても大丈夫です.例えば,「10, 8, 11, 9」(ml)という具合に標本抽出しても問題ありません(このとき,標本数は「4」ですね).
不偏推定量・不偏性
統計量$\theta$に対して,その推定量を$\hat{\theta}$と書くこととします.標本から計算される推定量(例えば,標本平均や標本分散)の期待値が,母集団のそれ(母平均や母分散)に等しいとき,その推定量は不偏推定量と呼ばれます.また,その性質を不偏性と呼びます.式を使って示すと,
E[\hat{\theta}] = \theta
ならば,推定量$\hat{\theta}$は統計量$\theta$の不偏推定量です(不偏性のある推定量などとも呼ばれます).ここで,$E[\cdot]$は期待値です.注意すべきなのは,標本サイズに関する議論が無いことです.言い換えると,標本サイズが大きくなくとも(一致性とは関係なく),推定量の期待値が母集団の統計量に等しいことを主張しています.標本サイズが重要と言われがちな統計学の分野において,これは極めて強力かつ興味深い性質であります.
標本平均は母平均の不偏推定量か?
では具体的に,標本平均は母平均の不偏推定量でしょうか?母平均を$\mu$,標本平均を$\bar{x}$と書くこととします.母集団から標本$x=\{x_i\}_{i=1}^{n}$を抽出したとき,標本平均は以下に定義されます.
\bar{x} = \frac{1}{n} \sum_{i=1}^n x_i
また,母平均の定義は$\mu = E\left[ x_n \right]$です.何かの標本をサンプリングしたときの期待値が母平均という感覚ですね.上記の標本平均が母分散の不偏推定量か確認するには,その期待値が母分散に一致するか確認します.
\begin{align}
E[\bar{x}] &= E\left[ \frac{1}{n} \sum_{i=1}^n x_i \right] \\
&= \frac{1}{n} \sum_{i=1}^n E\left[ x_i \right] \\
&= \frac{1}{n} \sum_{i=1}^n \mu \\
&= \mu
\end{align}
1行目から2行目への変形は線形性($E[aX + bY] = aE[X] + bE[Y]$)によるもの,2行目から3行目への変形は母平均の定義そのもの($\mu = E\left[ x_n \right]$)です.以上より,標本平均の期待値は母平均に一致する($E[\bar{x}] = \mu$)ので,不偏推定量の定義を満たします.つまり,標本平均は母平均の不偏推定量です.
標本分散は母分散の不偏推定量か?
次に,標本分散と母分散の関係を調べてみましょう.母分散を$\sigma^2$,標本分散を$s^2$と書くこととします.先ほどと同様に,母集団から標本$x=\{x_i\}_{i=1}^{n}$を抽出するとき,標本分散は以下に定義されます.
s^2 = \frac{1}{n} \sum_{i=1}^n (x_i - \bar{x})^2
ここで,母分散の定義は$\sigma^2 = V\left[ x_n \right]$です.$V\left[ \cdot \right]$は分散を示し,標本のばらつきという,何とも当たり前の定義です.では,標本分散の期待値を計算してみましょう.
\begin{align}
E[s^2] &= E\left[ \frac{1}{n} \sum_{i=1}^n (x_i - \bar{x})^2 \right] \\
&= \frac{1}{n} E\left[ \sum_{i=1}^n \left( (x_i - \mu) - (\bar{x} - \mu) \right)^2 \right] \\
&= \frac{1}{n} E\left[ \sum_{i=1}^n \left( (x_i - \mu)^2 + (\bar{x} - \mu)^2 - 2 (x_i - \mu) (\bar{x} - \mu) \right) \right] \\
&= \frac{1}{n} E\left[ \sum_{i=1}^n (x_i - \mu)^2 + \sum_{i=1}^n (\bar{x} - \mu)^2 - 2 (\bar{x} - \mu) \sum_{i=1}^n (x_i - \mu) \right] \\
&= \frac{1}{n} \left( E\left[ \sum_{i=1}^n (x_i - \mu)^2 \right] + E\left[ \sum_{i=1}^n (\bar{x} - \mu)^2 \right] - E\left[ 2 (\bar{x} - \mu) \sum_{i=1}^n (x_i - \mu) \right] \right)
\end{align}
見にくくなってきたので,3つの項を別々に計算します.まず,一つ目の項から:
\begin{align}
E\left[ \sum_{i=1}^n (x_i - \mu)^2 \right] &= \sum_{i=1}^n E\left[ (x_i - \mu)^2 \right] \\
&= n \cdot V\left[x_i\right] \\
&= n \sigma^2
\end{align}
次に,二つ目の項は:
\begin{align}
E\left[ \sum_{i=1}^n (\bar{x} - \mu)^2 \right] &= \sum_{i=1}^n E\left[ (\bar{x} - \mu)^2 \right] \\
&= n \cdot V\left[ \bar{x} \right] \\
&= n \cdot V\left[ \frac{1}{n} \sum_{i=1}^{n}x_i \right] \\
&= n \cdot \frac{1}{n^2} \cdot n \sigma^2 \\
&= \sigma^2 \\
\end{align}
また,三つ目の項は:
\begin{align}
-E\left[ 2 (\bar{x} - \mu) \sum_{i=1}^n (x_i - \mu) \right] &= -2 E\left[ (\bar{x} - \mu) \sum_{i=1}^n (x_i - \mu) \right] \\
&= -2 E\left[ (\bar{x} - \mu) \sum_{i=1}^n (x_i - \mu) \right] \\
&= -2 E\left[ (\bar{x} - \mu) \cdot (n\bar{x} - n\mu) \right] \\
&= -2 n E\left[ (\bar{x} - \mu)^2 \right] \\
&= -2 n V\left[ x_i \right] \\
&= -2 n \sigma^2 \\
\end{align}
したがって,標本分散の期待値の計算に戻ると,
\begin{align}
E[s^2]
&= \frac{1}{n} \left( E\left[ \sum_{i=1}^n (x_i - \mu)^2 \right] + E\left[ \sum_{i=1}^n (\bar{x} - \mu)^2 \right] - E\left[ 2 (\bar{x} - \mu) \sum_{i=1}^n (x_i - \mu) \right] \right) \\
&= \frac{1}{n} \left( n \sigma^2 + \sigma^2 -2 n \sigma^2 \right) \\
&= \frac{n-1}{n} \sigma^2 \\
\end{align}
以上より,標本分散の期待値は母分散に一致しない($E[s^2] \neq \sigma^2$)ので,不偏推定量の定義を満たしません.つまり,標本分散は母分散の不偏推定量ではありません.ここで,母分散の不偏推定量はどのように計算するか,というのが気になりますが,標本分散の式を僅かに変更するだけです.母分散の不偏推定量$\hat{s}^2$は,以下により得られます.
\hat{s}^2 = \frac{1}{n-1} \sum_{i=1}^n (x_i - \bar{x})^2
不偏性は,期待値の線形性からほぼ自明です.
\begin{align}
E[ \hat{s}^2 ] &= E\left[\frac{1}{n-1} \sum_{i=1}^n (x_i - \bar{x})^2 \right] \\
&= E\left[\frac{1}{n-1} \frac{n}{n} \sum_{i=1}^n (x_i - \bar{x})^2 \right] \\
&= \frac{n}{n-1} E\left[ \frac{1}{n} \sum_{i=1}^n (x_i - \bar{x})^2 \right] \\
&= \frac{n}{n-1} \frac{n-1}{n} \sigma^2 \\
&= \sigma^2 \\
\end{align}
以上より,期待値が母分散に一致する($E[ \hat{s}^2 ] = \sigma^2$)ので,$\hat{s}^2$が母分散の不偏推定量であることが確認できました.以降では,表記の簡略化のため,不偏性を持たない分散の推定量を「標本分散」,不偏性を持つ分散の推定量(母分散の不偏推定量)を「不偏分散」と呼ぶこととします.
標本分散と不偏分散の式を見比べると,その違いは僅かです.
s^2 = \frac{1}{n} \sum_{i=1}^n (x_i - \bar{x})^2
, \quad \hat{s}^2 = \frac{1}{n-1} \sum_{i=1}^n (x_i - \bar{x})^2
分母が$n$か,$n-1$か,という違いしかありません(この$n-1$で割るという操作には,Bessel's correctionというカッコいい名前が付いています).つまり,標本サイズ$n$が大きければ,ほぼ同じ値に収束しそうです($n$が大きければ母分散に収束する性質を一致性があるといいます).標本サイズ$n$が大きくない場合は,$s^2 < \hat{s}^2$という関係にありそうです.この辺りの性質は数値実験を通して確認します.
「母標準偏差の不偏推定量」???
母分散の不偏推定量が分かれば,母標準偏差の不偏推定量も簡単に分かりそうな全能感を持ってしまいますが(その平方根を取れば良さそうな感覚),残念ながらそうはいきません.母分散の不偏推定量の平方根は,母標準偏差の不偏推定量ではないのです.
稀に「母標準偏差の不偏推定量」という言葉がネットに転がっていることもありますが,これを見かけたときは十分気をつけなければなりません.なぜなら,(僕が見た限りでは)その言葉で定義された量が「母標準偏差の不偏推定量」でないことが多いからです(多くの解説記事や教科書が「母分散の不偏推定量の平方根が母標準偏差の不偏推定量である」と伝えていますが,一般にこれは正しくありません).証明は,例えばこちらをご覧ください.
数値実験
具体的に,何らかの確率分布から標本を取り出して標本平均と標本分散を計算してみたとき,それらは母平均,母分散に(ほぼ)等しいでしょうか.正規分布$\mathcal{N}(\mu, \sigma^2)$と連続一様分布$\mathcal{U}(a, b)$を例に,上記を確認しましょう.
例題1: 正規分布
まず,正規分布$\mathcal{N}(\mu, \sigma^2)$を取り上げます.特に$\mu=0$,$\sigma^2=1$として,標準正規分布を考えます.標準正規分布から2, 4, 8, ..., 1,024の標本を抽出し(これらの数字は標本サイズ),それぞれの場合における標本平均(=母平均の不偏推定量)と標本分散,母分散の不偏推定量を計算してみましょう.
初めに,各標本サイズで1回だけ標本抽出した際の結果を見てみます(このときの標本数は1).
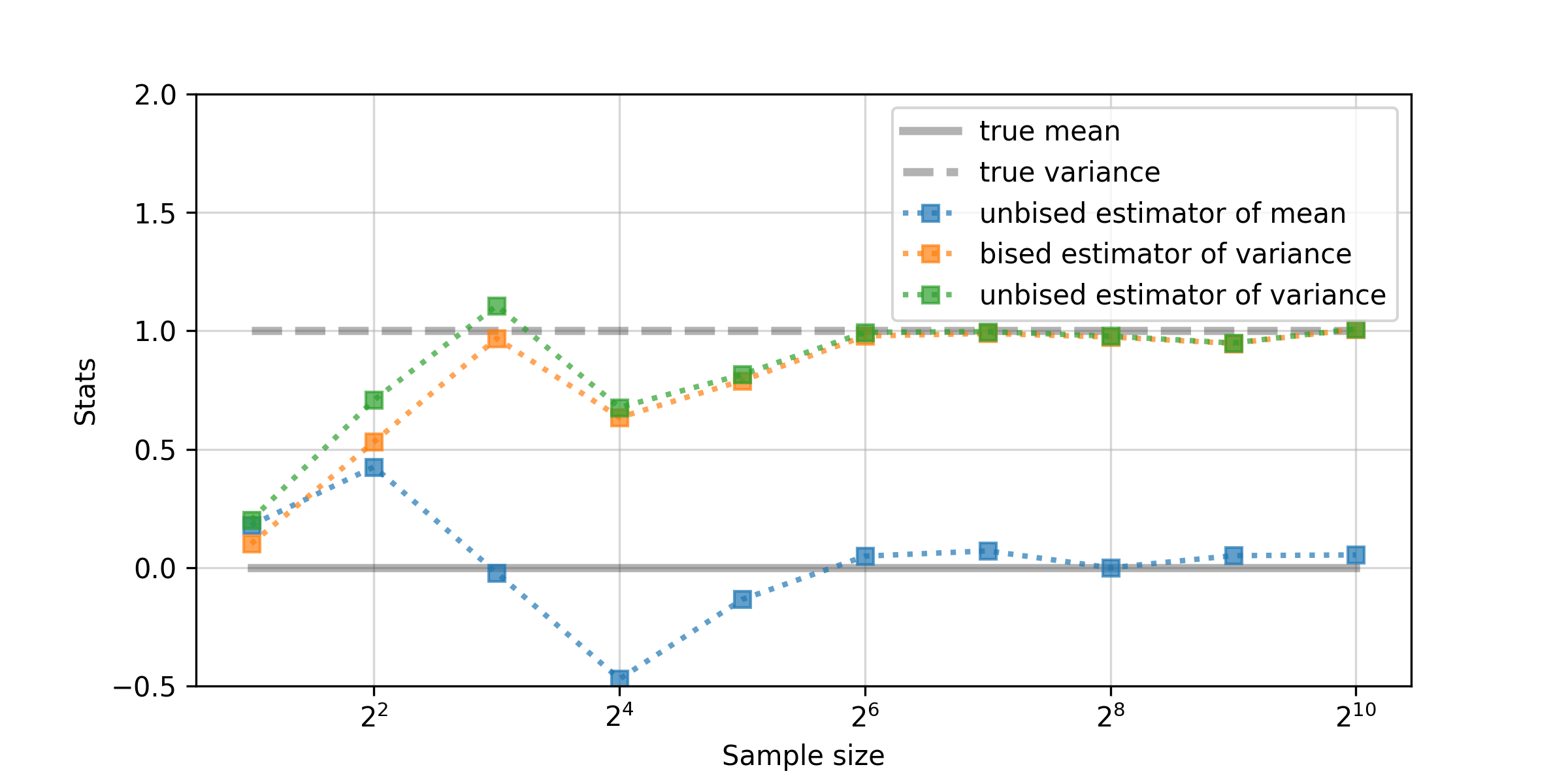
なんとも言えない感が漂う結果ですね.取り敢えず,標本分散(biased estimator of variance)と不偏分散(unbiased estimator of variance)を見比べると,少しだけ不偏分散の方が大きい値を取る傾向が確認できます.これは,標本分散の分母が$n$であるのに対して,不偏分散の分母が$n-1$であることを考えれば納得です.
標本数1では,標本分散と不偏分散のどちらが良いのか分かりにくいです.そこで,各標本サイズを抽出して平均・分散を計算する過程を256回だけ反復した結果を示します(標本数256).
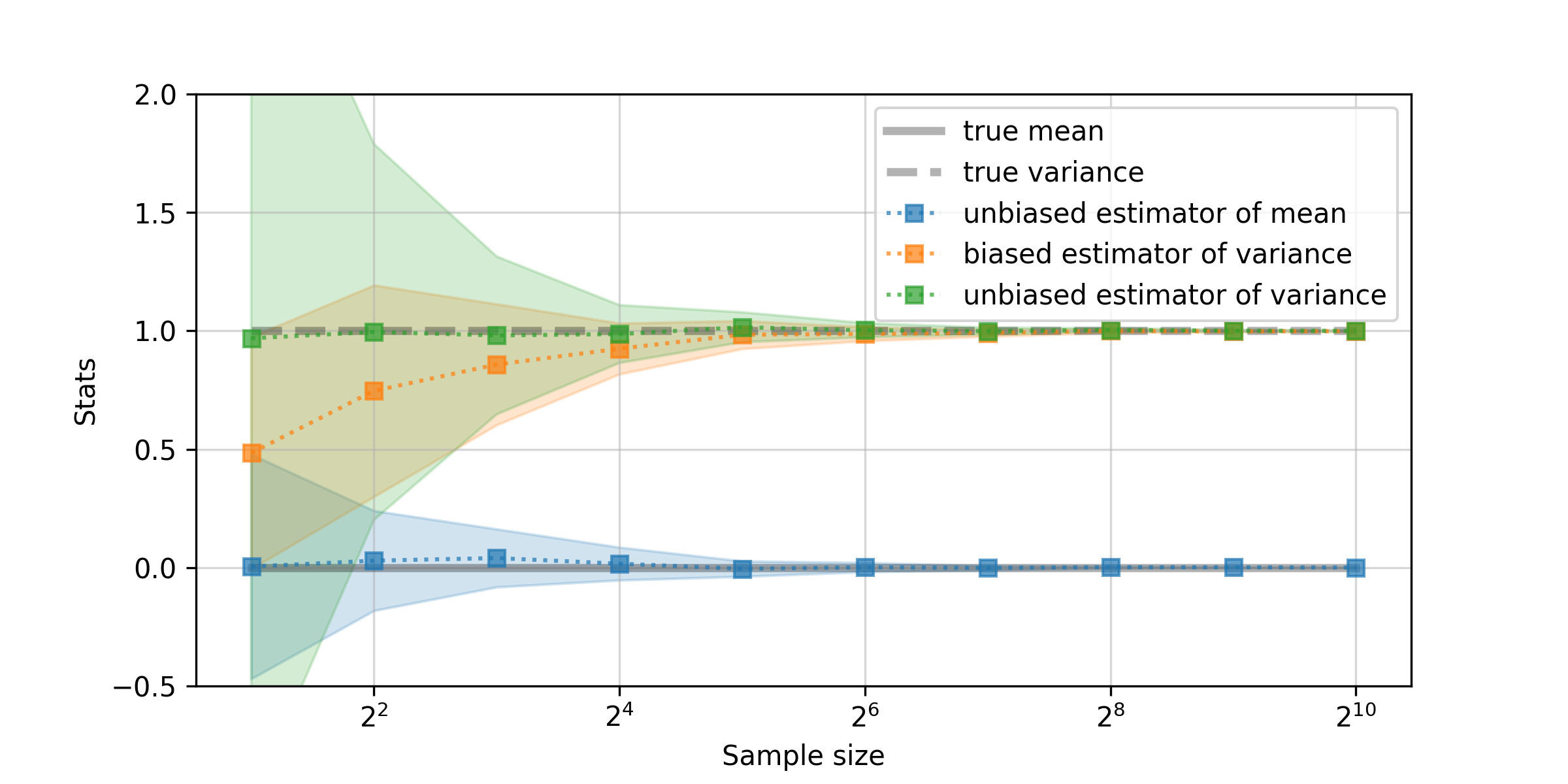
ここで,実線は標本数256の上での平均値,薄い影は分散です(混乱しそうですが,平均値の平均・分散といった具合です).図から,標本分散は標本サイズが小さいときには,母分散より少し小さい値を推定する傾向にあり,標本サイズが大きくなると真の分散に近づく印象です.一方,不偏分散は,標本サイズが小さいときにも,非常に正確に母分散を捉えていることが確認できます.標本サイズが十分に大きくなくても良い推定が実行できるという,不偏推定量の性質を反映していますね.標本平均が不偏推定量であることも,この図から直感的に理解できます.
例題2: 連続一様分布
次に,連続一様分布$\mathcal{U}(a, b)$を考えます.上限値と下限値を示すa, bをそれぞれ,a=0, b=1とすると,$\mathcal{U}(0, 1)$の母平均$\mu$と母分散$\sigma^2$はそれぞれ$\mu=0.5$,$\sigma^2=1/12$です.
先ほどと同様に,まずは標本数1の実験結果を示します.

やはり,標本分散の方が不偏分散より小さい値を返していますが,なんとも言えない結果です.再度,各標本サイズで256回だけ反復して標本抽出と統計量の計算を行った結果を示します.
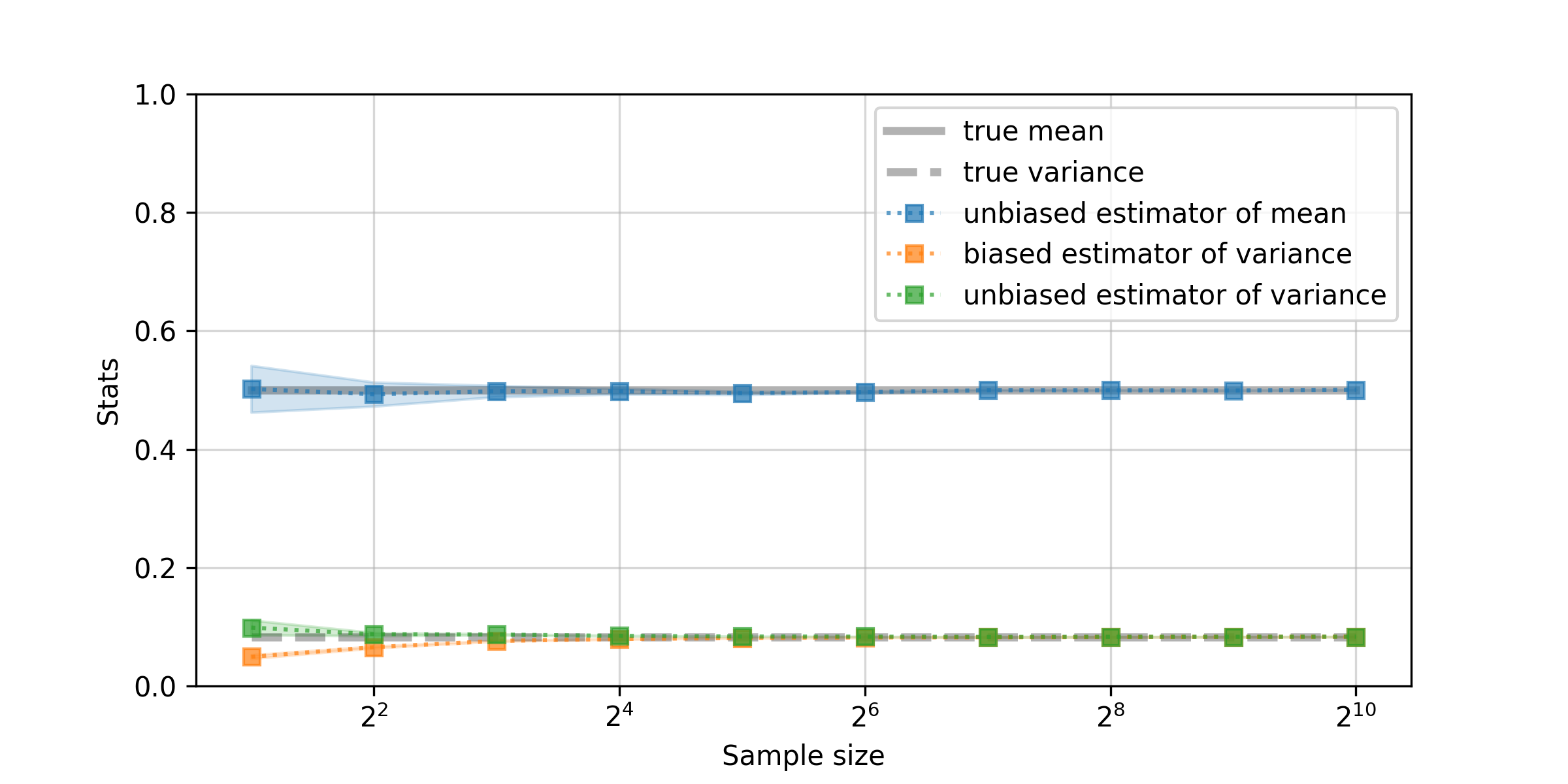
この結果から,やはり,標本平均は母平均の不偏推定量となっているようです.また,標本分散が母分散を過小評価しており,不偏分散が正確な推定を行っていることが確認できます.
終わりに
個人的に非常に興味深いと感じる話題を紹介しました.ここでは,不偏性というものに注目しましたが,その他,一致性と効率性というものがあります.一致性は大雑把に理解していますが,効率性についてはよく勉強していないので,時間があるときに勉強してみたいと思います(不偏性・一致性・効率性に関する議論は,例えばこちら).
参考文献
議論の上で参考にさせていただいたサイト:
[1] https://bellcurve.jp/statistics/glossary/12813.html
[2] https://www.jaysong.net/notes/simulation/consistency.html
[3] https://bellcurve.jp/statistics/blog/13645.html
[4] https://bellcurve.jp/statistics/course/9208.html
付録
数値実験のために用いたPythonスクリプトです.そのままコピペしていただけると,本文中に登場するものと同じ計算が実行され,図まで描画できます.以下のスクリプトは例題1に対応しています.例題2には,xの確率分布をnp.random.uniformにするだけです(同様にして,例えばPoisson分布などの実験も可能です).
1回の抽出を行う場合
np.random.seed(42)
mean_log = []
bvar_log = []
uvar_log = []
sizes = [2 ** i for i in range(1, 11)]
mean_true = np.zeros_like(sizes)
var_true = np.ones_like (sizes)
for size in sizes:
x = np.random.normal(size=size)
mean = np.mean(x)
bvar = np.var (x, ddof=0)
uvar = np.var (x, ddof=1)
mean_log.append(mean)
bvar_log.append(bvar)
uvar_log.append(uvar)
plt.figure(figsize=(8, 4))
plt.plot(sizes, mean_true, alpha=.3, ls="-", lw=3., c="k", label="true mean")
plt.plot(sizes, var_true, alpha=.3, ls="--", lw=3., c="k", label="true variance")
plt.plot(sizes, mean_log, alpha=.7, marker="s", ls=":", lw=2., c="tab:blue", label="unbised estimator of mean")
plt.plot(sizes, bvar_log, alpha=.7, marker="s", ls=":", lw=2., c="tab:orange", label="bised estimator of variance")
plt.plot(sizes, uvar_log, alpha=.7, marker="s", ls=":", lw=2., c="tab:green", label="unbised estimator of variance")
plt.legend(loc="upper right")
plt.grid(alpha=.5)
plt.xscale("log", basex=2)
plt.ylim(-.5, 2.)
plt.xlabel("Sample size")
plt.ylabel("Stats")
plt.show()
複数回の抽出を行う場合
np.random.seed(42)
n = 2 ** 10
k = 2 ** 8
x = np.random.normal(size=(n, k))
mean_mean = [] # mean
mean_var = []
bvar_mean = [] # biased estimator of variance
bvar_var = []
uvar_mean = [] # unbiased estimator of variance
uvar_var = []
sizes = [2 ** i for i in range(1, 11)]
mean_true = np.zeros_like(sizes)
var_true = np.ones_like (sizes)
for size in sizes:
# mean
_mean_mean = np.mean(np.mean(x[:size], axis=0))
_mean_var = np.var (np.mean(x[:size], axis=0), ddof=1)
mean_mean.append(_mean_mean)
mean_var .append(_mean_var)
# biased estimator of variance
_bvar_mean = np.mean(np.var(x[:size], axis=0, ddof=0))
_bvar_var = np.var (np.var(x[:size], axis=0, ddof=0), ddof=1)
bvar_mean.append(_bvar_mean)
bvar_var .append(_bvar_var)
# unbiased estimator of variance
_uvar_mean = np.mean(np.var(x[:size], axis=0, ddof=1))
_uvar_var = np.var (np.var(x[:size], axis=0, ddof=1), ddof=1)
uvar_mean.append(_uvar_mean)
uvar_var .append(_uvar_var)
# convert to np.array for fill_between visualization
mean_mean = np.array(mean_mean)
mean_var = np.array(mean_var)
bvar_mean = np.array(bvar_mean)
uvar_mean = np.array(uvar_mean)
bvar_var = np.array(bvar_var)
uvar_var = np.array(uvar_var)
plt.figure(figsize=(8, 4))
plt.plot(sizes, mean_true, alpha=.3, ls="-", lw=3., c="k", label="true mean")
plt.plot(sizes, var_true, alpha=.3, ls="--", lw=3., c="k", label="true variance")
plt.plot(sizes, mean_mean, alpha=.7, marker="s", ls=":", c="tab:blue", label="unbiased estimator of mean")
plt.fill_between(
sizes,
mean_mean + mean_var,
mean_mean - mean_var,
alpha=.2, color="tab:blue"
)
plt.plot(sizes, bvar_mean, alpha=.7, marker="s", ls=":", c="tab:orange", label="biased estimator of variance")
plt.fill_between(
sizes,
bvar_mean + bvar_var,
bvar_mean - bvar_var,
alpha=.2, color="tab:orange"
)
plt.plot(sizes, uvar_mean, alpha=.7, marker="s", ls=":", c="tab:green", label="unbiased estimator of variance")
plt.fill_between(
sizes,
uvar_mean + uvar_var,
uvar_mean - uvar_var,
alpha=.2, color="tab:green"
)
plt.legend(loc="upper right")
plt.grid(alpha=.5)
plt.xscale("log", basex=2)
plt.ylim(-.5, 2.)
plt.xlabel("Sample size")
plt.ylabel("Stats")
plt.show()